












序言
最近花了很多时间在分布式存储上面,不想在这个上面再花费很多时间了,所以用这篇文章做一个最后的总结。
在面对分布式存储的时候,分为两种角度,一种是客户侧,一种是运维侧,客户是上帝,所以不谈上帝的操作,专注于运维侧的系统构建。
其实所有的系统构建,都应该分成两个纬度,一个是客户纬度,专注于客户体验,进行各种定制化输出;一个是运维纬度,专注于底层的运维,各种监控数据,各种操作,都使用白屏的操作,而不是天天命令行操作,使用平台层面,可以防止误操作,系统扛了大部分的责任,也可以让运维不用每天记忆那些傻逼命令,傻逼参数,减轻低等级的操作,让大脑有更多的空间来想想其他的事情。。。例如,看看蓝天白日黄昏。。。。
分布式存储运维系统构建
分布式的架构一般如下所示:
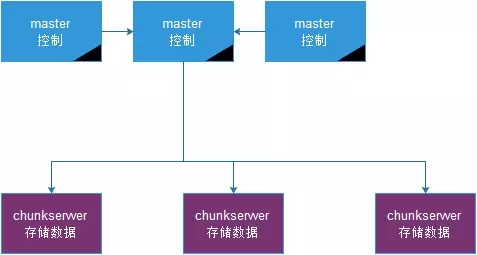
在分布式系统中,主要有几个对象。
运维测对象:一个是master,控制节点对象,主要用来提供元数据的保存,统计相关的信息,对外提供统一的API;一个是chunkserver,工作节点对象,主要是用来存储数据。
master涉及到动作有:查询master节点,进行master节点切换,备份元数据,生成checkpoint文件用于恢复,生成操作日志用于同步,修改master启动参数,重启master进程。
chunkserver涉及到动作有:查询chunkserver列表,显示总的空间大小,剩余的空间大小,磁盘的状态,进程状态,修改chunkserver进程参数,重启chunkserver进程,扩容,缩容。
客户侧对象:一个是目录,一个是文件,在此主要涉及到的动作有,查看目录,查看文件,查看分片数量,设置分片数量,检查分片数量,处理分片异常,设置用户的逻辑空间占用多少,物理空间占用多少,目录文件迁移,设置回收策略,设置文件的replica数量。
以下为对动作的解释,为什么需要这些动作:
1、 主节点为三个,主要是因为使用了paxos算法来进行选主操作,为什么要有一个主?提供服务的高可用,而使用三个节点,则是为了防止分区的情况出现。
2、 为什么要生成checkpoint文件,当master存储了大量的元数据的时候,这些数据都放在磁盘上,如果服务器宕机,那么在启动进程的时候,会将所有的数据都要加载进内存,时间上来说,是不可以接受的,从而定时生成checkpoint文件,便于宕机恢复,或者是进程挂了进行恢复。
3、 为什么要有操作日志,操作日志主要是在三个master节点上,都使用的是相同的一份数据,在master与其他的slave进行同步的时候,使用操作日志进行同步。
4、 为什么要有立刻生成chenckpoint文件和操作日志的动作,一般生成checkpoint都是定时生成的,当我要进行升级,或者修改参数的时候,需要保证数据的一致性,从而即可生成,在启动的时候,减少启动的时间。
5、 为什么要显示chunkserver的磁盘空间,chunkserver主要是用来存储的,那么必然要显示磁盘的剩余空间和总的空间,这个也是分布式存储的主要作用。
6、 修改chunkserver进程的参数是为了在重启chunkserver进程的时候,无须去服务器上手动进行修改相关的参数。
7、 扩容缩容一键化操作,大大减少运维操作的复杂性。
8、 为什么要处理分片异常,在有些异常的情况下,分片有的时候少了,有的时候没有,有的时候没有达到期望值,从而需要对分片异常的情况进行处理,这个主要是为了保障数据安全。。。而在这个进行操作的时候,可以使用replica的自动删除和添加机制,也就是修改一下文件的分片数量,从而也就会删除老版本的分片,并且将分片数量达到自己期望的状态。
9、 在分布式文件系统中,删除数据是有策略的,一般会设置一个回收站,当删除数据的时候,会将数据加入到回收站中,保留一天或者两天时间,如果还没有进行恢复,那么说明数据可以删除,会有一个定时任务来定时清理这些数据,从而需要一个回收删除的策略。
10、 设置文件的replica数量,这个是最基本的功能了,分布式存储的可靠性和可用性的唯一保障就是分片数量,一般为三份。
如果说,你看了上面的那么多内容,还不能做出一个运维测的分布式运维系统,那我也就无话可说了,对象有了,动作有了,剩下的就是代码了。。。
等风来。。。。
闲扯。。。
分布式存储就像风一样,你不知道花落谁家,你也可能找不到它到底存储在哪个节点的哪个chunk上,。。。其实是可以找到的,哈哈
分布式系统用来保证数据的可靠性,分片是唯一手段,保存来保存去,其实还是保存在磁盘上,无论你怎么跑,你要么存储在ssd磁盘上,要么存储在sata磁盘上。
分布式存储的可用性,无论怎么可用,最后都是使用linux系统中,无论怎么存储,都是使用的操作系统提供的文件系统,所以不管你是不是分布式存储,分布式文件,分布式表格,分布式键值,都存在于ext3?ext4文件系统中。。。。那么问题来了,在存储的时候,都是先写入内存,然后返回客户端写成功,如果。。。这个时候服务器宕机了,是不是就丢失数据了呢???
丢数据,有什么关系,但是,可以不丢么,可以的。。。只要禁用swap,禁用操作系统层面的缓存就可以了,损失了部分性能,换取了更强的可靠性。
在使用分布式存储的时候,使用ssd,使用sata,可以优化么?那是必须可以的,在操作系统层面,总是存储各种元数据,例如atime,diratime,但是在分布式系统中,可以不存储已提高性能,在进行挂载的时候,加入这些参数就好了。。
这就是所谓的优化???是的,就那么几个参数,也算是优化。。。你不能修改源码进行适配,所以。。。加几个参数就算是优化了,这个。。。算是一种搞笑的行为,不过。。很多人以为这种优化酷毙了。。。。淡然一笑。。。不语。。。
有的时候,感觉有的操作很酷,因为在构建一个运维平台的时候,不仅仅有各种测试数据,各种TPS,各种QPS,各种http latency,还有。。。我做这个动作需要几步。。。例如我扩容,点击3次,输入3次,就完成了一次扩容。。。可控的风险,可控的升级。。。。这种还是极好的。。。
没有幂等性,如何做到唯一性???在使用分布式系统的时候,可能会经常碰到超时,那么这种超时,怎么办???业务方面一般认为存储系统是可靠的,返回成功就是成功,而返回失败则是失败,而没有考虑到如果服务端处理成功,客户端超时没接受到响应,咋整。。。。业务序列号的唯一性,查询此笔业务的序列号,然后查询记录,从而可以得到成功或者失败,只能根据历史情况查询。。。
突然记起来了,在分布式存储中,还有一个动作就是数据打散,也就是rebalance,这种操作感觉好高端,例如。。。在扩容的时候,新上线的机器需要迁移数据,例如,在使用DHT算法的时候,需要将相邻的数据迁移到新上限的机器上,那么进行rebalance,如果此时数据量过大,可能会影响整体分布式存储的IO能力,从而在进行rebalance的时候,需要手动进行操作,进行限流,也就是限制迁移的速度,可能是20M/S,也可能是100M.S,主要看你的带宽来进行评估了。。。不要让屁股决定脑袋。。。
突然记起来上次一个故障,客户端写存储,写不进去,业务报错,查询,发现客户端响应码,5XXX,内部错误,查询日志,发现是,,,分区未找到。。。初步判断为可能服务器宕机,不可能。。。进程重启。。。不可能,都没收到报警。。。那么就认定为是服务器内部进行了rebalance的操作。。。但是最后再一看,发现所有的rebalance都必须手动,自动进行rebalance的操作都已经关闭,然后查询对应的时间点,发现。。。对应的chunkserver上面的进程进行了重启。。。。然后再查为什么重启,发现是进程使用的内存过大,而cgroup对这个进程使用的内存做了限制,从而把这个进程杀了,然后监控进程一看,这个傻逼挂了,然后又把它给启动了,。。。装作什么事都没有发生。。。而就在一分钟之内,啪啪啪,报错报错。。。。那么问题来了,启动一个chunkserver进程需要一分钟么。。。那么问题又来了,前端的nginx或者lvs发现了进程挂了15S,拉起来进程,假设是15S,那么检查间隔15S,大于45S,再加上各种延时,考虑一下服务器的负载,差不多一分钟。。。。那么这种问题。。。主管判断?日志检查?这种才是好玩的问题排查。。。。
JUST FUCK...............好了,这篇文章只花一个小时,浪费太多时间不好





















