一.spark简介
spark是基于内存运算的大数据分布式并行计算框架,本身具有丰富的API,可实现与HDFS、HBase、Hive、Kafka、Elasticsearch、Druid等组件的交互,同时也是优秀的MapReduce替代方案。
spark卓越的计算性能得意于其核心的分布式数据架构:RDD和DataFrame。


1、RDD
RDD(Resilient Distributes Dataset), 是spark中最基础、最常用的数据结构。其本身封装了作业中input data数据,并以分区方式分布在内存或者磁盘上的Block中。但实质上RDD对象是一个元数据结构,存储着Block、Node映射关系等元数据信息。
RDD常规去重算子:

2、DataFrame
DataFrame是一种以RDD为基础的分布式数据集,具有schema元数据信息,即标注了DataFrame中每一列名称和类型,能够大幅提升Transform、Action的计算效率。
DataFrame常规去重算子:

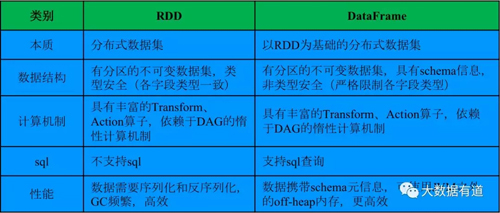
3、RDD与DataFrame对比
二.选择去重

接下来,大数据有道将和大家一起学习一下spark RDD和DataFrame选择去重的技巧。
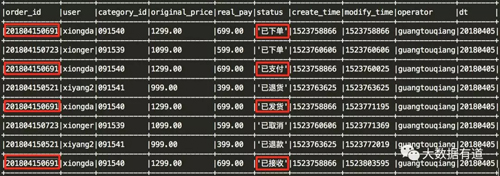
1、原始数据
江南皮革厂订单数据(input),需要指出“original_price”和real_pay对应double类型、“create_time”和“modify_time”为long类型。
源数据预处理:

为了方便对每条订单进行提取和计算,作业中封装了订单对象RiveSouthOrder:

2、RDD选择去重
a.选择去重代码(scala):

b.执行日志:

c.计算结果:

d.逻辑解析:
***部分,加载源数据并封装到RiveSouthOrder样例类中,生成RDD;
第二部分,首先通过groupBy对order_id数据做分组后生成RDD[(String, Iterable[RiveSouthOrder])]对象([K,V]结构),随即使用map对每个Key(order_id)下多组记录(Iterable[RiveSouthOrder])进行reduce操作(maxBy),***在maxBy算子传入一个字面量函数(也可写为x=>x.modify_time),即提取该order_id下每条记录中的modify_time进行比对,然后选出***时间记录(maxBy为高阶函数,依赖reduceLeft实现);
第三部分,toDebugString方法打印RDD转换过程,***值得注意collect才是真正触发一系列运算的源头。
3、DataFrame选择去重
a.选择去重代码(scala):
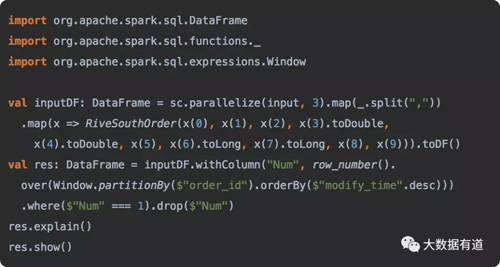
b.执行日志:
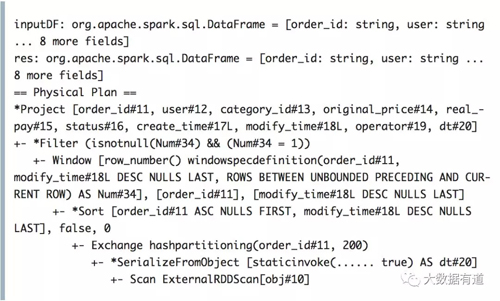
c.计算结果:

d.逻辑解析:
***部分,引入依赖和隐式转换,分别对应DataFrame类型识别、使用sql格式的$"modify_time"和row_number()+Window()函数的使用;
第二部分,加载源数据,由于源数据由RiveSouthOrder封装,可直接toDF;
第三部分,首先使用withColumn方法添加Num字段,Num是由row_number()+Window()+orderBy()实现(原理同Hive sql),原则是根据modify_time对每个order_id分区下的订单进行降序排序,接着使用where做过滤(也可使用filter),***drop掉不再使用的Num字段;
第四部分,通过explain打印dataFrame的物理执行过程,show方法作为action算子触发了以上的系列运算。
三.归纳总结
spark RDD和DataFrame均提供了丰富的API接口,极大的提升了开发效率和计算性能;
RDD的计算更倾向于map和reduce方式,而DataFrame含有schema元信息更容易与sql计算方式相结合;
RDD选择去重使用了groupBy+maxBy方法,一气呵成;DataFrame则使用row_number+window+orderBy方法,逻辑清晰;两者处理方式所展现的spark函数式编程的精妙之处都值得探索和学习。