k-means算法比较简单。在k-means算法中,用cluster来表示簇;容易证明k-means算法收敛等同于所有质心不再发生变化。基本的k-means算法流程如下:
简介
又叫K-均值算法,是非监督学习中的聚类算法。
")
基本思想
k-means算法比较简单。在k-means算法中,用cluster来表示簇;容易证明k-means算法收敛等同于所有质心不再发生变化。基本的k-means算法流程如下:
选取k个初始质心(作为初始cluster,每个初始cluster只包含一个点);
repeat:
- 对每个样本点,计算得到距其最近的质心,将其类别标为该质心所对应的cluster;
- 重新计算k个cluster对应的质心(质心是cluster中样本点的均值);
- until 质心不再发生变化 12345
repeat的次数决定了算法的迭代次数。实际上,k-means的本质是最小化目标函数,目标函数为每个点到其簇质心的距离的平方和:
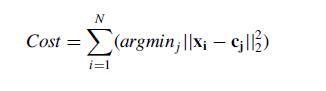
- N是元素个数,x表示元素,c(j)表示第j簇的质心
- 算法复杂度
- 时间复杂度是O(nkt) ,其中n代表元素个数,t代表算法迭代的次数,k代表簇的数目
优缺点
- 优点
- 简单、快速;
- 对大数据集有较高的效率并且是可伸缩性的;
- 时间复杂度近于线性,适合挖掘大规模数据集。
缺点
- k-means是局部***,因而对初始质心的选取敏感;
- 选择能达到目标函数***的k值是非常困难的。
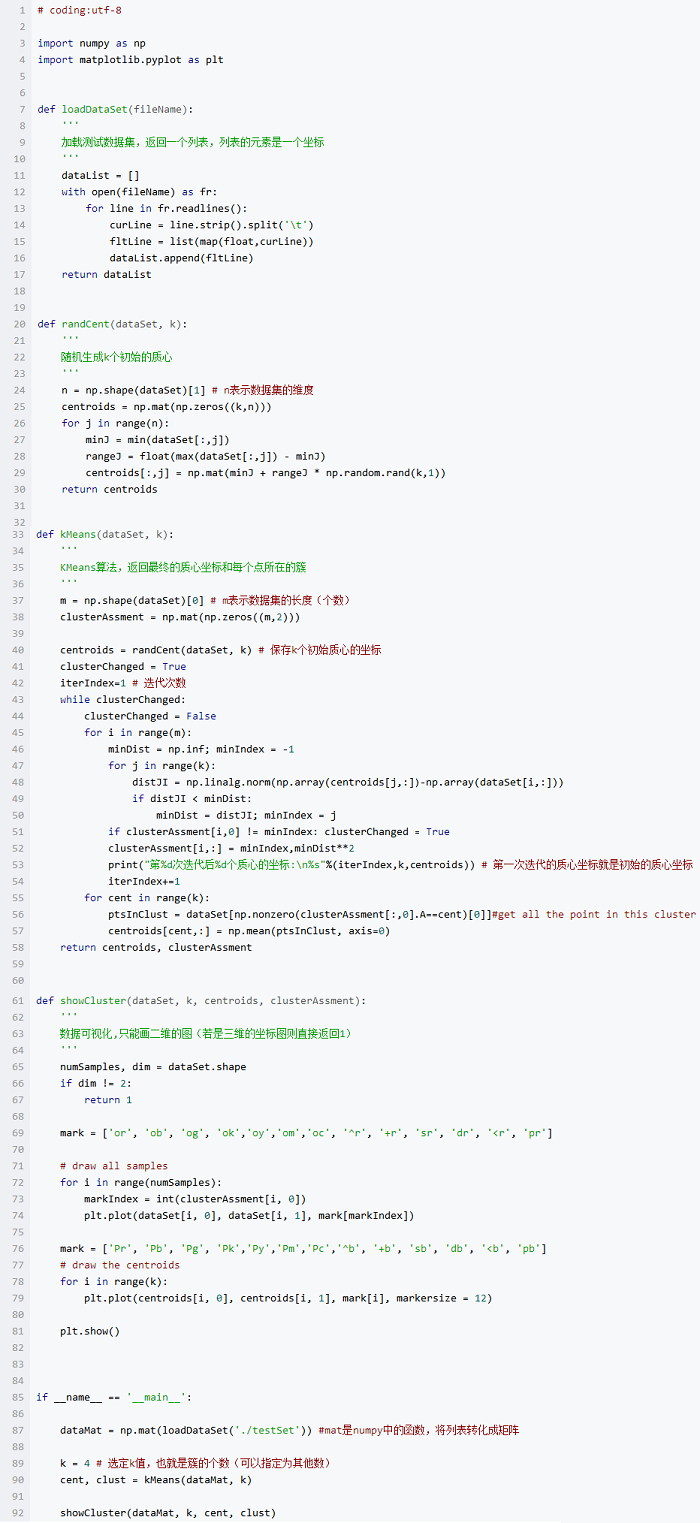
代码
代码已在github上实现,这里也贴出来
测试数据集获取地址为testSet