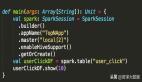
Kubernetes自从1.6起便号称可以承载5000个以上的节点,但是从数十到5000的路上,难免会遇到问题。
本片文章即分享Open API在kubernetes 5000之路上的经验,包括遇到的问题、尝试解决问题以及找到真正的问题。
遇到的问题以及如何解决
问题一:1 ~ 500个节点之后
问题:
kubectl 有时会出现 timeout(p.s. kubectl -v=6 可以显示所有API细节指令)
尝试解决:
- 一开始以为是kube-apiserver服务器负载的问题,尝试增加proxy做replica协助进行负载均衡
- 但是超过10个备份master的时候,发现问题不是因为kube-apiserver无法承受负载,GKE通过一台32-core VM就可以承载500个节点
原因:
排除以上原因,开始排查master上剩下的几个服务(etcd、kube-proxy)
- 开始尝试调整etcd
- 通过使用datadog查看etcd吞吐量,发现有异常延迟(latency spiking ~100 ms)
- 通过Fio工具做性能评估,发现只用到10%的IOPS(Input/Output Per Second),由于写入延迟(write latency 2ms)降低了性能
- 尝试把SSD从网络硬盘变为每台机器有个local temp drive(SSD)
- 结果从~100ms —> 200us
问题二:~1000个节点的时候
问题:
发现kube-apiserver每秒从etcd上读取500mb
尝试解决:
- 通过Prometheus查看container之间的网络流量
原因:
- 发现Fluentd和Datadog抓取每个节点上资料过于频繁
- 调低两个服务的抓取频率,网络性能从500mb/s降低到几乎没有
etcd小技巧:通过--etcd-servers-overrides可以将Kubernetes Event的资料写入作为切割,分不同机器处理,如下所示
- --etcd-servers-overrides=/events#https://0.example.com:2381;https://1.example.com:2381;https://2.example.com:2381
问题三:1000 ~ 2000个节点
问题:
无法再写入数据,报错cascading failure
kubernetes-ec2-autoscaler在全部的etcd都停掉以后才回传问题,并且关闭所有的etcd
尝试解决:
- 猜测是etcd硬盘满了,但是检查SSD依旧有很多空间
- 检查是否有预设的空间限制,发现有2GB大小限制
解決方法:
- 在etcd启动参数中加入--quota-backend-bytes
- 修改kubernetes-ec2-autoscaler逻辑——如果超过50%出现问题,关闭集群
各种服务的优化
Kube masters 的高可用
一般来说,我们的架构是一个kube-master(主要的 Kubernetes 服务提供组件,上面有kube-apiserver、kube-scheduler 和kube-control-manager)加上多個slave。但是要达到高可用,要参考一下方式实现:
- kube-apiserver要设置多个服务,并且通过参数--apiserver-count重启并且设定
- kubernetes-ec2-autoscaler可以帮助我们自动关闭idle的资源,但是这跟Kubernetes scheduler的原则相悖,不过通过这些设定,可以帮助我们尽量集中资源。
- {
- "kind" : "Policy",
- "apiVersion" : "v1",
- "predicates" : [
- {"name" : "GeneralPredicates"},
- {"name" : "MatchInterPodAffinity"},
- {"name" : "NoDiskConflict"},
- {"name" : "NoVolumeZoneConflict"},
- {"name" : "PodToleratesNodeTaints"}
- ],
- "priorities" : [
- {"name" : "MostRequestedPriority", "weight" : 1},
- {"name" : "InterPodAffinityPriority", "weight" : 2}
- ]
- }
以上为调整kubernetes scheduler范例,通过调高InterPodAffinityPriority的权重,达到我们的目的。更多示范参考范例.
需要注意的是,目前Kubernetes Scheduler Policy并不支持动态切换,需要重启kube-apiserver(issue: 41600)
调整scheduler policy造成的影响
OpenAI使用了KubeDNS ,但不久后发现——
问题:
经常出现DNS查询不到的情况(随机发生)
超过 ~200QPS domain lookup
尝试解决:
- 尝试查看为何有这种状态,发现有些node上跑了超过10个KuberDNS
解决方法:
- 由于scheduler policy造成了许多POD的集中
- KubeDNS很轻量,容易被分配到同一节点上,造成domain lookup的集中
- 需要修改POD affinity(相关介绍),尽量让KubeDNS分配到不同的node之上
- affinity:
- podAntiAffinity:
- requiredDuringSchedulingIgnoredDuringExecution:
- - weight: 100
- labelSelector:
- matchExpressions:
- - key: k8s-app
- operator: In
- values:
- - kube-dns
- topologyKey: kubernetes.io/hostname
新建节点时Docker image pulls缓慢的问题
问题:
每次新节点建立起来,docker image pull都要花30分钟
尝试解决:
- 有一个很大的container image Dota,差不多17GB,影响了整个节点的image pulling
- 开始检查kubelet是否有其他image pull选项
解决方法:
- 在kubelet增加选项--serialize-image-pulls=false来启动image pulling,让其他服务可以更早地pull
- 这个选项需要docker storgae切换到overlay2
- 并且把docker image存放到SSD,可以让image pull更快一些
补充:source trace
- // serializeImagePulls when enabled, tells the Kubelet to pull images one
- // at a time. We recommend *not* changing the default value on nodes that
- // run docker daemon with version < 1.9 or an Aufs storage backend.
- // Issue #10959 has more details.
- SerializeImagePulls *bool `json:"serializeImagePulls"`
提高docker image pull的速度
此外,还可以通过以下方式来提高pull的速度
- kubelet参数--image-pull-progress-deadline要提高到30mins
- docker daemon参数max-concurrent-download调整到10才能多线程下载
网络性能提升
Flannel性能限制
OpenAI节点间的网络流量,可以达到10-15GBit/s,但是由于Flannel所以导致流量会降到 ~2GBit/s
解决方式是拿掉Flannel,使用实际的网络
- hostNetwork: true
- dnsPolicy: ClusterFirstWithHostNet