













越来越多的人在反思算法带来的负面效应。
自从微博用户 @廖师傅廖师傅抱怨了自己用手机打车和订酒店遭遇到的“大数据杀熟”,更多人在社交网络上表达共鸣——面对同一段行程、同一家酒店或者同一个商品,基于互联网公司的用户画像,不同的用户会看到截然不同的价格。
滴滴、携程、飞猪、京东、美团和淘票票都被卷入其中。有人说在携程上看到一家酒店,用自己的账号和别人的账号显示不同的价格;也有人说打开滴滴打车,iPhone 用户会比 Android 用户显示出更高的预估车费;如果是级别更高的白金用户,行程升舱到专车后可能结算价格并没有得到优惠;在购票网站买夜场电影票要 38 块,而在电影院柜台只要 15 块。
不过提供服务的公司没有承认。携程后来回应说,人们对于价格体系有所误解,展示上的差异是因为用户领用或购买优惠券的差异。滴滴对此的回应是,“滴滴平台不允许价格歧视,打车价格更不会因人、因设备、手机系统而异。”
“大数据杀熟”的始作俑者是亚马逊。2000 年,亚马逊针对同一张 DVD 碟片施行不同的价格政策,新用户看到的价格是 22.74 美元,如果是算法认定有购买意愿的老用户,价格会显示为 26.24 美元。如果删除 Cookie,价格马上又回落。很快这种策略被用户发现并投诉,亚马逊 CEO 贝索斯公开道歉,说这仅仅是一场实验,也承诺不再进行价格歧视。
大数据为企业的价格歧视提供巨大便利。所谓“价格歧视”其实是个中性术语,它是指相同等级或质量的商品或服务,在购买者中实行不同的收费标准。
大多数情况下它能帮助企业平衡效率和收益,最为典型的是民航业,同样是经济舱,赶时间、对价格不敏感的商务旅客在起飞前才买票,价格昂贵;提前很久预定的旅行游客,却可以低价买到同样一班飞机、同一个舱位。不管坐多少人飞机都得飞,这样的不平等让更多人坐得起飞机,而航空公司也可以获得尽可能多的利润。
还有日常生活常见的现象,一瓶矿泉水在街边商店只需要 2 块钱,但在景区景点可能会卖到 10 倍价格。
而互联网扩大了价格歧视的范围,科技公司能够轻而易举知道你是否有购买意向。但可疑之处在于,一张机票在临近起飞才购买价格高昂合情合理,这是为时间成本付出的代价。但是同一时间、同一购票平台、不同用户看到不同的价格就令人难以接受,这似乎不再是价格歧视,而是对购买者的“歧视”。
即便抛开有没有价格歧视,利用大数据来分析用户,以此来实现利润最大化早就是互联网的常态。在广告业务上,Google、Facebook 以及国内的微博、微信、今日头条、百度都是建立在用户产生的数据之上——分析用户喜欢什么,再把广告主的广告,或者自己的产品和服务尽量精准的推送到用户眼前。
每个用户都被打上无数个标签,你喜欢看什么、买什么、有多大的消费能力、你的好友都是谁……在掌握数据的科技公司眼中,已经存在对你是精确“偏见”。
很多时候这样的偏见让人意识不到,但确实会影响日常决策:
- 根据购物记录判断购买能力,电商平台会推荐你可能会买的东西,甚至不同的评论排序;
- 同一家酒店或机票,同一时间很多人搜索,价格可能会上涨;
- 经常不使用的账号会一直收到优惠券,频繁预定的账号反而优惠券很少;
- 同理,账户的级别越高反而代表了购买力越强,就越有可能被推荐更贵的东西
这是一个世界性议题,尤其在 Facebook 遭到数据泄露的丑闻之后,人们开始反思曾经被视为改变人类生活、提供巨大便利的算法和大数据,现在是怎样摧毁我们的。
上周,每年一次讨论未来话题的 TED 大会也表现出这种焦虑。计算机科学家亚隆·兰尼尔(Jaron Lanier)在演讲中说,当计算机变得越加聪明、算法更加精准,一切都是为了让你看更多广告而运作的时候,一切似乎都乱套了,“我不称他们为社交网络了,我现在称它们为’行为改造帝国’。”“这是一个全球的灾难。”
他没有给出具体的解决方法,在大数据改造人类行为上,科技公司而不是他们的用户掌握主导权。
而且令人沮丧的是,一时半会这样的大数据偏见不会好转。就像 Facebook 在面对国会的质询后承诺整改,但是它的广告业务依然基于庞大的用户数据分析。花了那么多预算招人做大数据、做人工智能算法的公司们,会放弃用数据来提升赚钱的效率么?
乐观一点看,我们还是有一些可以自己决定的空间。今天的 Hack Your Life 就尝试为你找到一些方法,让你在有限的范围内可以尽量控制自己的隐私输出。
先从控制浏览记录开始吧。
第一步,尽量在浏览中不留痕迹
用户偏好的数据积累来自你的浏览记录,购买过的东西、点击过的广告、收藏过的商品都构成互联网公司分析你的基础。
比如在搜索引擎输入关键词,浏览记录就会被搜集记录,如果登录了搜索网站的账号体系,手机号又被当成注册的账号,这就是一次实名搜索。之后搜索公司可以将你的数据卖给广告营销公司,推送适合的广告,也可能向手机发送短信。
当然我们要承认这些数据带来了很大便利,淘宝首页永远有你近期打算买的东西、大众点评会推荐附近评分最高的餐厅、在旅行网站买过的机票隔天就会推送目的之处的酒店和其他服务。
让算法减少对你的判断信息是第一步,可以尽量不要用他们各自的手机应用完成浏览和购买,改用浏览器会让你有更多的主动权。
你无法阻止的是,一旦开启一个账号应用就会开始搜集你的偏好数据,特别是购物类的应用。最极端的办法是删除整个账户,我们针对清除账号做过一次评测和攻略,可以戳这里复习。
在不需要的网站,关掉 Cookie
Cookies 是网站为了辨别用户身份,储存在用户本地终端上的数据,通常它记录你经常访问哪类网页、停留多久、什么时间访问……这也没什么错,但如果信息被比如广告商收集,你的兴趣和口味就会被分析判断。
Cookie 不是魔鬼,启用 Cookie 可让你浏览网页更轻松,比如以前填写过的各种资料、选择的语言……都会被 Cookie 存储,停用 Cookie 会让你第二次访问网页时遇到很多麻烦。

停用并不麻烦,只需要关掉一些不需要登陆但又常用的网站比如搜索引擎。这个步骤并不难,Chrome 也有详细的说明。进入浏览器的设置页面进入高级设置后,在隐私的内容设置里关掉 Cookie 追踪就可以了。如果嫌麻烦,你可以直接用 duckdockgo.com(需要访问技巧)这个网站进行搜索,它在你搜索时,并不会记录你的个人信息。
开启匿名浏览模式
主流的浏览器大多有匿名浏览模式,也叫隐身模式或者无痕浏览。Google 的 Chrome、苹果的 Safari、还有 Firefox、Internet Explorer……
开启隐身模式,浏览器不会记录访问过页面上的信息,包括浏览记录、密码、Cookie、缓存的图片等等,用完就走不留痕迹。
当然也有相对不便利的地方,比如网页上的自动填充,还有需要账户登录的时候并不会自动登录,要再次手动输入一次账号和密码。
不过要想达到完全没有偏好推荐的状态,在使用购物应用的时候最好在匿名浏览模式下也不要登录账号,你可能会看到这个网站最原始的样子。
关注手机获取权限
iOS 和 Android 都会在下载新应用时,提示隐私数据的设置。你可以根据自己的需要选择是否要禁止它对你通讯录、地理位置等信息的抓取。
更多的时候,应用在第一次安装打开时会弹窗提醒一些权限获取,这时候你可以谨慎一点,如果一个手电筒应用要求调用拍照或话筒,还要获取你的地理位置和联系人信息?拒绝它!
iOS 系统更保守一些,在使用途中也会提示获取权限,比如麦克风一旦被开启,屏幕顶端会做明显的提示。
几个匿名搜索引擎
可以试试以下几个匿名搜索引擎。
Tor(The Onion Router,洋葱路由)。Tor 浏览器可以让用户 IP 地址在世界各地间“跳跃”,由此避免被其他人追踪到。不仅可以提供客户端的匿名访问,还可以提供服务器的匿名,这样服务端和客户端互相都不知道对方的 IP。由此服务端无法记录用户使用信息、客户端不输入真实个人数据,可以达成上网的完全匿名性。
DuckDuckGo。一个承诺完全不监控、不记录用户的搜索内容的网站,
WolframAlpha,它更像一个问答网站,当你输入问题比如“北京到上海的距离”,直接弹出的不是一个个网页链接而是问题结果。
评论夸得天花乱坠,要如何才知道这件商品究竟好不好?
出门不用带钱包已经是常态了,衣食住行没哪样是不能用手机解决的。但相信有一个困扰是普遍的:我怎么知道商品的评论是真是假?
首先有一个事实,就是在淘宝已经诞生 15 年之后,所有能买东西的在线服务上都已经有了成熟的“刷单”商业模式。淘宝店铺的信誉、销量,大众点评店家的好评,推荐微博下的评论和点赞都是可以制造的。
所以总的来说,评论这件事很难判断。逻辑上来说,你没办法知道一条“这东西真好,强烈推荐”是一句发自肺腑的顾客反馈还是机器制造的噪音。
从评论体系这件事说起。首先,购物的核心体验是买到东西,如果这样东西称心如意,以个人经验来说,在绝大部分情况下大概是没什么动力跑回去说夸奖的话的,评论这件事根本不是正常购物流程的一部分。
当然也有例外。把在线购物这件事对应到现实生活的购物中,会发现挑选、讨价还价、付款这些环节是一样的,但评论环节是独立的。现实世界中离开一家商店之后是没有评论这个环节的。当你真的发自肺腑需要将一件东西推荐给别人时,有效的动作是告诉他店铺的地址或者网址。
评论的价值就在于“推荐”,只有一件东西的价值难以从外观上来判断时,才会天然的形成内容丰富的评论。你不会为了一件衣服写上 500 字,但为了一本书或一部电影来说就很正常,因为后两种消费中本身就含有个人的再创作。
但无论是 C2C 的淘宝还是 B2C 的京东,平台都希望大家来评论,希望能够影响到正在挑选的顾客,所有淘宝有店家的返现好评,京东有评论送京豆。但它们有一些不同。在 C2C 平台上,卖同一件东西的商家都是竞争关系,好评论留下的客户就是营业额;在以自营为主的 B2C 平台上,评论的价值就要弱很多,因为无论你买哪一样对平台来说都是一样的。
基于这些逻辑,我们有几个小建议来从评论中获得相对真实的信息:
1. 不要看店铺信誉,看销量
在各种刷单商业模式下,C2C 平台的“信誉”数值现在已经没有参考价值了。
C2C 平台上挑选东西时,比如购买海外版本的手机,比较好的方式是以销量来排名。虽然“销量”这个数值也可以有水分,但具体到某件商品上来说,它是可以看出趋势的,比如手机卖的最好的那家要么是网红开的,他比较在乎信誉;要么是价格便宜一点,这何乐而不为;要么是上架最早,这说明渠道相对靠谱。
2. 看差评。
差评基本上只有两种来源,要么是怒不可遏的消费者,要么是不怀好意的竞争对手,而后一种情况其实并不多见,因为差评需要说的很具体,批量生产的差评这很容易拆穿。
无论是大众点评、淘宝还是携程,当差评区域出现针对某种特定事件的多个评论,可信度就相对高。比如某家餐厅不开发票只送饮料,某个店家发已拆封商品,某间酒店隔音很差等等。
在淘宝上,一个真实的差评是很“难得”的。绝大部分店家会选择息事宁人,用退货退款的方式减少差评的诞生。但如果你发现一件商品里挂着一个差评,而且字数不少且和店家有几次文字交锋,那基本上说明买家经历了难以忍受的购物体验。
3. 排除“返现”好评。
淘宝上的返现评论都是店家自己组织的,这很难识别。但比如大众点评这样的平台上,出现抽奖赢得的评论可以说没有任何信息量。比如“感谢抽到了霸王餐,这间店美味又大碗”。
但京东这样的平台除外,因为理论上来说,京东的评论只有购买才能添加,而且无论写什么都有代金券可以拿,这种情况下那些贴上照片的评论,就会比随便写 15 个字的更有参考价值。
4. 选择信誉比较好的平台
这个部分最简单,选“官方店”出错的概率是极小的。比如淘宝、天猫品牌旗舰店,京东自营,或者店家自己的在线平台,比如 Apple Online Store。或许第三方卖家会比这些官方店便宜一些,但在购买比较贵的东西时,官方店的价值大多数情况比差价更有价值。
如果买书,你可以找你信任的媒体评论。目前翻译版是主流,去美国亚马逊或Goodreads 看原版评论也是好选择。
看维基百科,也有一些方法筛选信息
首先,用更有节操的搜索引擎可以获得更有价值的信息,Google 是相对好的那个选择。
Google 的搜索技巧已经介绍过蛮多次了,比如用在关键词后面加上 site:****.com 进行站内搜索,或者用“-”符号来排除搜索结果里的一些关键词,比如“UFO -dailystar”来排除某些小报的不严肃报道等等。更多的搜索技巧可以看这里。
或者,可以查看国际互联网上最中立的网站之一维基百科。
维基百科是一个由志愿编辑维护的非盈利网站,每一个字都是身处世界各地,使用各种语言的志愿编辑敲上去的。按照维基百科的编辑规则,除了极少数的常识性文字,大部分描述、评论和事实都需要具体的资料作为引用的证据,引用可以是严肃网站的网页,也可以是某本出版的论文或者书籍。
同时,没一个编辑的操作是被其他编辑监督的。如果一段话没有来源,会被编辑团队打上角标“本段文字缺乏来源”。
可以用 Google 直接搜索具体的词汇,维基百科的结果会被放在极为重要的位置,要么是结果的第一条,要么是页面右侧位置更重要的引用栏。
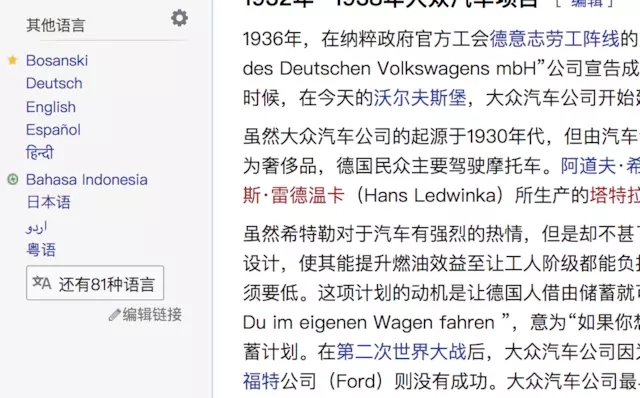
在维基百科中,会有一些被编辑团队加上好评的页面。比如搜索大众汽车,在左下角多语言页面的位置,能看到德文页面被标上了黄色小星星,这代表维基百科页面最好的评价“典范条目”。按照维基百科的说法,整个维基百科 100 多万条目中,只有 652 个典范条目,它们是按照专业的写作标准完成,介绍且大致附有可靠来源可供查证,是维基百科“最好的作品”。
同时能看到印尼语的页面被标上了绿色加号套圆圈的标志,这代表“优良条目”,就是不够“典范条目”那么好,但已经满足“编写得非常有条理,内容真实准确且信息可供查证、覆盖面广泛、观点中立、内容稳定,且在可能情况下,遵守版权地配以切题图像。”
查看这两种条目是最好的体验,如果遇到了不会使用的语言,请活用 Google 或者 Bing 的页面翻译,在翻译维基百科这样以书面语撰写的页面时它们非常好用。
最后的建议,当查看中文维基百科时,尤其是在和意识形态、历史、文化相关的页面时,请注意查看引用来源,以及页面的编辑历史。维基百科的多个中文页面曾被人恶意篡改,在大多数的情况下这些页面会被按照维基百科的要求重新编辑并冻结,但或许有漏网之鱼。
当然,最重要的是有好奇心和求真精神。
别被个性推荐左右了视野,信息来源自己掌握
这也是全面客观理解事物的一个部分。
左翼互联网活动家 Eli Pariser 在《别让算法控制你》这本书中提出了“信息泡沫(The Filter Bubble)”。简单来说,互联网分析了你的喜好,不断推送你爱看的东西,这个过程让你获取的信息越来越接近“你认同的”而非事物的本来面目。就好像,你被笼罩在一个范围有限的泡泡里面,然后形成偏见。
社交网络,别只看热门内容
微博看起来开放,但它的智能排序让流量分发变得并不平等。如今的微博基于用户关注、标签记微博内容等相关信息做智能排序,而不是时间排序,你会看到一些自己更想看到的信息,而不是正在发生的信息。
你并不能关掉智能排序,有限的选择是微博搜索,这可以帮助你快速把握某些热门事件的多个面貌,看到和你意见向左的观点。微博搜索也会按照智能排序,你可以选择“实时”,这可能是微博仅剩的单纯的时间排序信息流。
而微信朋友圈全部基于熟人,它实际上加重了人群观点的分离,并不适合做高效的信息搜索,顶栏的搜索框可以显示“一周热门朋友圈”,以及热门的公众号文章,但实际上这也是基于你的朋友的喜好。这也会让假消息证伪的周期会变慢一些,人们可能会陷入某种大众情绪。想想你在长辈的朋友圈里见过多少耸人听闻的养生和健康谣言。
自己订阅和管理新闻源
类似今日头条的新闻应用有源源不断的新闻文章,根据你之前的点击行为和你的个人数据推荐内容,但实际上它剥夺了你的选择权。
用微博这样的社交网络关注新闻也不能拒绝数据推荐,点赞高的会排在前面。
这也是加重信息偏见的一部分,如果不想被喂食,你可以选择自己主动在订阅软件中订阅想看的信息源。
有几个应用可以考虑。比如 Digg 和 Feedly。把你认为可靠的新闻网站一个个添加进去,就可以在同一个信息流中获取最新刷出的信息。
并且还可以对话题做分类,比如时事政治、商业新闻、娱乐新闻……自己定制一个新闻阅读应用。
如果你不满足于这种时效性不太强的邮件订阅,还可以用 Google 自定义一份。在 Google News 里搜索你感兴趣领域的关键字,比如“共享单车”,它的页面会出现大量相关新闻,在页面的右下角会有一个“创建快讯”功能,利用这个功能你可以直接创建一个相关领域的 Newsletter。
怎样快速辨别虚假的信息?这里有一些简单的办法和逻辑
假新闻也是算法推荐的结果,也是 Facebook 面对的最大质疑之一。虚假新闻往往有耸人听闻的标题,这让它传播的更广更快。同样的道理也适用于毒鸡汤、养生帖。
这是信息传播的必然,个性化的算法又更加助推了这些吸引人、但实际上难辨真假甚至有害的信息。
怎么辨别虚假的信息?
简单的说,一篇有理有据令人信服的文章,应该有具体的时间地点和人物姓名,以及使用标准的引用来源。通过查证这个来源就可以迅速判断真实性。反过来说,时间、地点、具体人物和引用来源只要缺一样,信息的可靠性就值得怀疑。当缺少两样或更多时,就大概率是鸡汤或者毒鸡汤了。
查找信源是最直接的办法,但也有一些套路可以辨别假新闻。
在中文互联网上,和民族主义有关的假新闻是最为猖獗,而且受众广泛的。举例来说,4 月 15 日美军因使用化学武器空袭叙利亚军事目标之后,中文社交网络上流传了一张所谓“叙利亚驻联合国代表贾法里低头枯坐,弱国无外交”的照片。这张照片所配的文字迎合了某种情绪,但仅以事实来说,这张照片和配文是附会的。
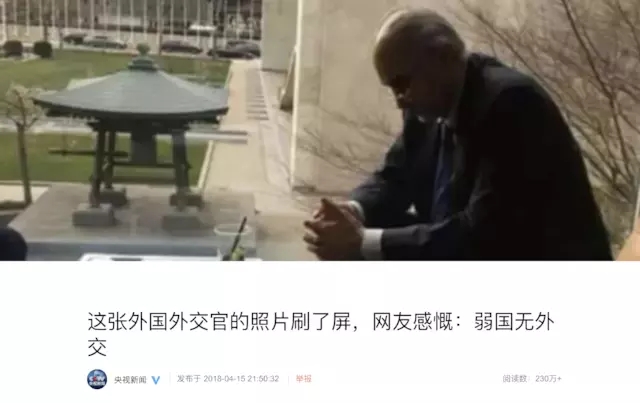
如何分辨?
以贾法里这张照片为例,首先使用 Google 图片搜索之后,英文结果中绝大部分已经被中文社交网络的结果污染了,仔细分辨能发现,有一条来自 Twitter 的结果显示照片发布时间是 4 月 11 日。
使用贾法里的英文名 Bashar al-Jaafari 在 Twitter 搜索,可以发现这张照片被大量引用,但因为分辨率不高所以 Google 似乎没办法很好的识别,但最早的发布时期是 4 月 9 日。也就是说,贾法里这张照片至少和 15 日的空袭没任何关系,
随便选了一个 Twitter 帖子,就是 15 日之前发的“穿越帖”
类似的例子有很多,有相当一部分谣言是这个模式,“开头一张图,结局全靠编”。在图片清晰度较高的情况下,Google 搜索可以有效的找到信息源头,至少可以验证一些基本的事实。
有时候,即使是内容完全是事实,它也并不是全部真相。
举例来说,“努力可以带来成功”这句话是事实,但如果继续推导出“只要努力就会成功”显然就不对了,这种推导落入了“幸存者偏差”,只有努力且成功的人会被关注,而失败者的存在则被无视了。
这样的例子不胜枚举。“那有什么大饥荒,我家老人说从没饿过肚子”,“同性恋地位可高了,我认识的一对恋人收到很多祝福”,“我家亲戚用这个偏方治好了疑难杂症,你试试肯定有效”等等,这些例子都是类似的。
还有一种情况和幸存者偏差类似,都和概率相关,但是看起来似乎相反。比如有公众号发布文章,说统计了很多打疫苗之后有严重副作用的幼儿,呼吁家长不要给小孩子注射疫苗。类似的新闻也类似幸存者偏差,只是反过来了,忽视了幸存者的存在。
科学是严谨且可以证伪的。看到言之凿凿的新闻,尤其是和科学相关时,用幸存者偏差的逻辑就可以做有效的初步判断。
旅行是重灾区,尤其是国际机票
旅行可能是最容易受到大数据偏见影响的消费,这其中有太多信息不对等——机票价格怎么变动、当地的交通开销、景点的费用等等都要抽丝剥茧一样自己查。
所以携程和飞猪这类在线旅行平台往往尽可能让你打包购买服务,去年搭售的问题备受争议后,打包售卖其实也并没有完全被解决,买完机票后你可能会收到接二连三的推送,推荐你购买接送机、保险、门票之类的附加产品。
用一个匿名浏览器看价格,以及利用比价工具
理论上来说机票的定价波动主要来自航空公司,但就像我们前面提到的,在线代理平台可以利用大数据做一定空间内的价格调整。如果同一个行程同时有很多人搜索,价格自然会水涨船高,两次搜索前后差个一小时,价格也可能差别巨大。
匿名浏览器可以尽可能消除大数据价杀熟的可能性,更进一步的话,连账号都不要登录,这样你可能会看到最原始的价格显示。
机票价格波动的原因太多,航空公司一直在微调价格,预测起来非常难。
有一些工具可以帮到你。预定国际机票的话可以试试 KAYAK 和 FareCompare,他们从其他平台抓取到票价的变化,然后给出一个参考,告诉你某个明确的时间段内什么时间是出手的时机。
爱飞狗旅行是一个微信小程序,它用一年时间收集了 350 亿机票价格,提供的服务是航班的历史数据对比,然后给出未来一段时间机票变化的预测轨迹。
订阅某个航班,确定出行日期,它会通过历史价格轨迹告诉你提前几天买到最低价的可能性最大。不过目前它所覆盖的航班数量还比较少。
不过价格预测工具注定不会变成大平台,仅仅只能当做参考。假如真的有一个能准确预测价格波动的大平台,航空公司也会因此再次动态调整价格,那么所谓的预测也就失去了意义。
自己掌握目的地信息,有些海外服务更了解本地市场
比如预定接送机的车辆,国内的旅行网站经过了层层代理,价格可能远远高于你自己寻找的本地服务。
旅行网站的信息并不完全可靠,订酒店之前,不如先看看官网的价格,景点的信息和门票也是一样的道理。
更多的时候,自己用本土的海外服务还更方便。
Uber 国际版。Uber 中国被滴滴出行吞并后,Uber 推出了一个新的中文版 Uber 应用,不能在大陆使用,但可以在海外 Uber 运营的地方用来打车。
Yelp。美国的大众点评,在欧美国家有较好的覆盖,用来查找餐厅、查看餐厅评分、人均价格的利器。Yelp 官网也定期分享一些更新的进展和使用小技巧。比如 Yelp 每周会有当地的周报,告诉你有哪些新鲜的地方上榜,还有专门的“新增商家”栏目。
如果你去日本,tabelog 是日本版的大众点评,对各个城市的了解要比大众点评海外版好很多,支持中文。
TripAdvisor。这是一个更适合查看景点和当地资讯的应用,特别是酒店评分,可以看到全球各地入住者的评价,相对来说比较客观。
Google Trips。Google 推出的行程管理应用,特点在于它充分利用了 Google 本身的资源和信息优势,通过自动抓取你通过Gmail 邮箱订阅的酒店、飞机、火车等信息,自动分类,为你自动生成推荐的行程;此外,它会根据其他旅行者的历史记录,为你智能推荐值得一去的景点、餐厅等。
还想看更多的旅行建议,这里有一份 TED 大会演讲者提供的建议汇总。
删掉购物应用,只在电脑下单不但省钱也能减少对你的追踪
这似乎是一个恶性循环,算法推荐给你合适的内容或者商品,你就无法自拔不断浏览,继而算法会抓取更多的个人细信息,越来越懂你的喜好。
抖音和淘宝可能让你花费了越来越多的时间沉迷其中,浪费了大量时间,还有金钱。
好好控制使用手机的时间吧,这需要你的自制力。
我们曾经探讨过为什么你会在双十一热衷于买买买,尽管有些商品并不能带来实质性的优惠。购物和美食一样可以激活大脑分泌多巴胺,这种物质可以缓解内心的负面情绪,让我们陷入越买越上瘾的循环中。
关于怎么降低自己的购物欲理性消费,请戳这份指南。
购物应用诱惑太多,用网买东西吧
大数据在助长不合理的消费欲望,你可以从源头上做一点控制。
比如尽量不要用购物应用,和购买机票的套路类似,购物也在一个不会记录 Cookie 的浏览器里完成,也可以帮助你减少隐私的泄露。
还有一些察觉不到的习惯,购物应用大多可以通过社交账号(微博、微信和手机号等等)登录,这就等于把你的社交关系交了出去。服务提供商可以据此做很多事,比如推荐你好友去过的餐厅、买过的东西。同时你的喜好也被“广播”了出去,比如微信计步、大众点评的好友动态,有时候也是个大写的尴尬。
所以,单独准备一个用来购物的手机号码吧,把你的社交关系和购买消费隔离开来。
购物应用的诱惑太多了,每一个角落都在刺激你的消费。淘宝还有边看边买的直播,一不小心就种草了很多根本用不着没买过的东西。在这一点上,年轻人可能和看电视购物买东西的长辈们没有任何差别。
如果用实体线下购物做类比的话,用网页购物就像去逛商场,而花样繁多的购物应用更像 711 这样的便利店——它更加触手可得,消费决策的门槛也就更低了。
好好记账,搞清需求
在消费的控制上,可以试试下面两个记应用。记账本身不是一个快乐的事,每一笔都手动输入的话是个负担。电子支付的普及,选择记账应用的首要条件是能够自动导入。
网易有钱,截图记账,不用输入账户信息。如果信任它,登陆支付宝账号,或者网银账号,直接导入账单。
把所有的收入开支渠道统一起来,也方便你搞清楚自己的开支去向。
另一个是每年要付 350 元的 YNAB,它的特点是节省时间,以及设置预算上的便利。它在设计时考虑了你不一定是每天记账,当你连续记录新账目时,每一笔开支的时间默认和上一笔记录相同。这样当你记录周一的 7 笔账的时候,就不需要调 7 次时间。
怎么做手机和电脑的使用时间管理?
关于电脑和手机使用的时间管理,你可以试一下工作狂喜欢的工具 RescueTime 。目前它支持 Windows、Mac、Android,暂时不能装在 iOS 设备上。
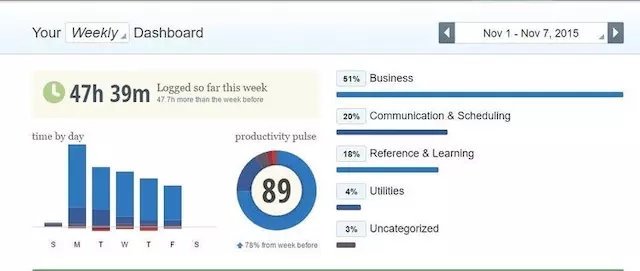
安装了应用,它就会默默记录你都干了什么,让你知道每一天、每个月自己时间的多少花在了哪些任务上面。最为核心的一个数字是“有效率的比例”,记录了使用工作相关应用、网站的时间,它们占据总时间的多少比重。
这有助于你审视自己浪费掉的时间都去了哪里。
















