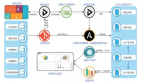
【51CTO.com快译】将您的开发团队转变为持续交付模式是一项比较艰巨工作。正如自动化持续交付过程本身那样,您应该分阶段进行,而不要一次性更改所有的方面。同时您要有回滚方案,以备各种突发问题的出现。虽然此过程***挑战性,但一旦成功实现,则会使您能够更快地响应客户的各种需求,并能使您的产品最终在市场上更具竞争力。
自动化的好处
自动化的诸多好处包括:
- 将上市的时间从按周计算和按月计算,缩短为按天或小时计算。
- 更少的软件错误意味着降低了市场的风险。
- 更少的时间花费在运维上,也减少了软件开发的成本。
- 更强大的开发团队。
一旦成功构建了自动化的pipeline,那么在将整个开发环境进行切换之前,您就可以使用此处所罗列的一些***实践来微调自己的pipeline。
我们在此将***实践分为三大类:
- 软件架构 – 各种服务和产品的整体架构,为您构建pipeline的模式和团队与之交互的方式定下基调。
- 自动化模式 - 自动化和各种测试的策略。
- 公司文化 - 团队组织、透明度和责任。
1.软件架构
采用微服务
为了实现真正的敏捷和自动化pipeline,我们建议您将产品构建为各种微服务。
如果您对为何需要微服务还存有疑问的话,请参阅:《什么是微服务?》,和《从AWS角度介绍微服务》。
除非您是从头开始创建一个应用程序,否则重新构建整个应用程序将是一项非常艰巨的任务。如果您手头已有现成的系统,那么***是逐步地切换到微服务之中。例如,您可以采用由Martin Fowler开发strangler模式。该模式保证了将单一的体系结构提升至微服务的过程中,您仍可使用并存的现有业务系统。
在这种模式下,您的关键任务系统不但能够得以维持,并且新的架构也会围绕着它被构建出来。随着时间的推移,旧系统会逐渐地被新架构所取代,而非一次性全部转换过去。
2.自动化模式
实施GitOps
为了优化平均恢复时间(MTTR,Mean Time to Recovery),您应该实施GitOps。
GitOps的运行依靠将Git(译者注:Git是一个开源的分布式版本控制系统)作为声明式基础架构和应用程序的“数据源(source of truth)”。当对于Git的更改发生时,自动化交付的pipeline会将变更部署到您的基础架构之中。
您的基础架构和应用程序代码不仅具有了数据源,而且在发生灾难时,您的开发团队还能够从Git中快速地恢复基础架构,从而将MTTR从小时级别降低到分钟级别。
有关GitOps的更多信息,请参阅《用拉式请求的各种操作》和《GitOps:Kubernetes实现高速持续集成与持续交付(CI/CD)》。
注重安全的自动化
在与大型团队协作和将各种自动化pipeline连到Kubernetes的时候,您需要重点考虑自己集群里的各种安全凭证。为了能将更新部署到群集之中,您必须将证书保存在某处。在理想情况下,这些证书应该保存在集群的内部。但是如果需要被放在外面的话,它们至少应该被保存在诸如Vault这样的库中。
推/拉式模式
由于您的持续集成能从持续交付中分离出来,因此拉式自动化pipeline提供了更好的安全性。如今大多数CI/CD工具都使用的是推送模式。基于推式意味着代码从CI系统开始经过pipeline,然后需要通过一系列编码脚本,或手动使用'kubectl'将变更推送到Kubernetes群集之中。总体而言,如果不小心使用的话,CI反而会成为您系统的一个入口。
像Weave Cloud的拉模式就依赖于两个关键的组件:一个是用于监控镜像注册表的部署性自动化器(Deploy Automator),另一个是位于群集之中,以维护其状态的部署性同步器(Deploy Synchronizer)。
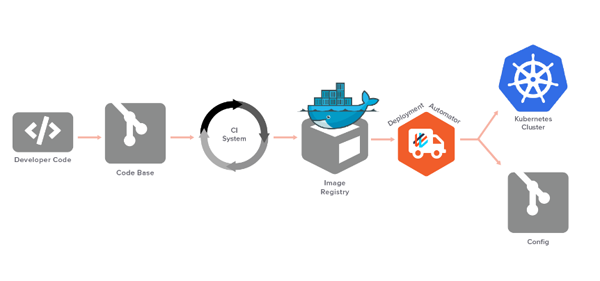
由于Weave Cloud部署针对的是如下方面,因此拉式方法更为安全:
- 基于角色访问控制(RBAC)的相关策略与安全性,仅执行Kubernetes所允许的操作。信任关系由群集所共享,并非被单独地掌握。
- 本地绑定所有Kubernetes对象,并获悉操作是否已完成或需要重试。
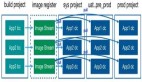
不必每次都从头开始重建镜像
在通过pipeline去运行各种更新时,为了节省宝贵的时间,您不必每次都去重建镜像。您只需一次性构建容器的镜像,然后通过每个测试序列/环境将其“推广”出去。如果您使用的是GitOps,那么就可以在Git中对各种声明性配置文件进行更改,或者直接使用Weave Cloud部署的各种操作。
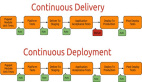
对发布进行解耦部署
在将产品发布给客户之前,请添加一个部署的阶段,以进行冒烟测试,甚至是一些更多类型的测试,如:蓝绿部署、金丝雀测试、或A/B测试。
值得注意的是:我们应当在概念上理解“部署”与“发布”之间的区别。部署是指软件已经通过了测试并被安装到了特定环境之中;而发布则是将这些更改最终真实地落实并推送到最终用户的手中。
衡量pipeline的成功
请建立并跟踪pipeline里的那些关键性的指标。您可以将开始自动化之前的情况和之后的结果做比较,主要包括如下方面:
- 部署频率 - 每天完成的部署数量。
- 变更的交付周期 - 部署一次变更所需要的交付时间。
- 平均恢复时间(MTTR) - 在灾难发生时,恢复应用所需要的时间。
- 变更失败率 - 以正常运行时间的百分比来表示宕机的时间。
3.持续交付的企业文化
创建一种开放且不抱怨的文化
请围绕着自动化过程增加企业透明度。通过允许开发人员犯错,从而激励他们勇于解决和纠正各种过程中所产生的偏差。一旦自动化被建立起来,开发人员需要对pipeline拥有完全的所有权,以便在测试失败发生时,代码变更能够被及时地进行回滚。
每个人都为构建承担责任
在完全的自动化pipeline模式下,任何人都应该能够去诊断并解决构建中出现的问题。这不仅能够产生更多自创的软件开发流程,还会促进整个组织内产生更好的团队协作。
***的建议
众所周知,易于出错的手动式部署往往会增加软件发布的风险和成本,同时也会降低公司在其业务领域的竞争力。因此,虽然实施自动化的持续交付pipeline会是一项艰巨的任务,但它最终将被证明是企业值得付出的“阵痛”。
原文标题:Best Practices for Continuous Delivery ,作者:Anita Buehrle
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】