正则表达式对数据处理而言非常重要。近日,Dataquest 博客发布了一篇针对入门级数据科学家的正则表达式介绍文章,通过实际操作详细阐述了正则表达式的使用方法和一些技巧。
数据科学家的一部分使命是操作大量数据。有时候,这些数据中会包含大量文本语料。比如,假如我们需要搞清楚「巴拿马文件 [注意,可能是敏感词]」丑闻中谁给谁发送过邮件,那么我们就要筛查 1150 万份文档!我们可以采用人工方式,亲自阅读每一封电子邮件,但我们也可以利用 Python 的力量。毕竟,代码存在的意义就是自动执行任务。
即便如此,从头开始写一个脚本也需要大量时间和精力。这就是正则表达式的用武之地。正则表达式(regular expression)也被称为 RE、regex 和 regular pattern,这是一种让我们能快速筛查和分析文本的紧凑型语言。正则表达式始于 1956 年——Stephen Cole Kleene 创造了它并将其用于描述人类神经系统的 McCulloch-Pitts 模型。到了 60 年代,Ken Thompson 将这种标记方法添加到了一个类似 Windows 记事本的文本编辑器中,自那以后,正则表达式不断发展壮大。
正则表达式的一大关键特征是其经济实用的脚本。你甚至可以将其看作是代码中的捷径。没有它,我们就要码更多代码才能实现相同的功能。学习本教程需要基本的 Python 知识。如果你理解 if-else 语句、while 和 for 循环、列表(list)和字典(dictionary),你就能读懂本教程的大部分内容。你也需要一个代码编辑器,比如 Visual Code Studio、PyCharm 或 Atom。此外,了解一点 pandas 的基本知识会很有帮助,这样在我们解读每一行代码时你才不会迷失方向。如果你需要学学 pandas,可以参考这个教程:
https://www.dataquest.io/blog/pandas-python-tutorial/
学习完本教程后,你将熟悉一些正则表达式的工作原理,并能使用其基本模式和 Python 的 re 模块提供的函数来分析字符串。我们还将体验正则表达式和 pandas 库高效处理大规模无组织数据集的能力。
现在,我们来看看正则表达式的能力。
介绍我们的数据集
我们将使用来自 Kaggle 的 Fraudulent Email Corpus(欺诈电子邮件语料库)。其中包含 1998 年到 2007 年之间发送的数千封钓鱼邮件。这些邮件读起来很有意思。我们首先将使用单封邮件学习基本的正则表达式命令,然后我们会对整个语料库进行处理。
语料库地址:https://www.kaggle.com/rtatman/fraudulent-email-corpus
介绍 Python 的正则表达式模块
首先,准备数据集:打开那个文本文件,将其设置成「只读」,然后读取它。我们也为其分配了一个变量 fh,表示文件句柄(file handle)。
- fh = open(r"test_emails.txt", "r").read()
注意我们直接在目录路径之前使用了 r。这项技术会将一个字符串转换成一个原始字符串,这有助于避免由某些机器阅读字符的方式所导致的冲突,比如 Windows 中目录路径中的反斜杠。
你可能注意到了我们目前没有使用整个语料库。我们只是人工地取了该语料库中前面几封邮件,然后将其做成了一个测试文件。这样做的目的是在本教程中输出显示测试结果时,就不用每次都显示数千行结果了。这能免除很多烦恼。你自己练习的时候使用完整语料库或我们的测试文件都不会有问题。
现在,假设我们想知道这些电子邮件的发件人。我们可以试试只用原始的 Python 来实现:
- for line in fh.split("\n"):
- if "From:" in line:
- print(line)
也可以使用正则表达式:
- import re
- for line in re.findall("From:.*", fh):
- print(line)
我们来解读一下这段代码。我们首先导入了 Python 的 re 模块。然后我们写了操作代码。在这个简单的示例中,这段代码只比原始 Python 少一行。但是,随着任务的增加,正则表达式可以让你的脚本继续保持简单经济。
re.findall() 返回字符串中满足其模式的所有实例的列表。这是 Python 内置的 re 模块中最常用的函数之一。分解看看。该函数的形式是 re.findall(pattern, string),有两个参数。其中,pattern 表示我们希望寻找的子字符串,string 表示我们要在其中查找的主字符串。主字符串可以包含很多行。
.* 是字符串模式的简写。我们马上就会详细解释。现在只需知道它们的作用是匹配 From: 字段中的名称和电子邮箱地址。
在我们继续深入之前,我们先了解一些常见的正则表达式模式。
常见的正则表达式模式
我们在上面的 re.findall() 中使用的模式中包含一个完全拼写出来的字符串 From:。这在我们知道我们所要寻找的东西是什么时非常有用,可以确定到实际的字母以及大小写。如果我们不知道我们所想要的字符串的确切格式,我们将难以为继。幸运的是,正则表达式有解决这类情况的基本模式。我们看看本教程中会使用的一些模式:
- \w 匹配字母数字字符,即 a-z、A-Z 和 0-9,也会匹配下划线 _ 和连接号 –
- \d 匹配数字,即 0-9
- \s 匹配空白字符,包括制表符、换行符、回车符和空格符
- \S 匹配非空白字符
- . 匹配除换行符 \n 之外的任意字符
有了这些正则表达式模式,你就能在我们继续解释代码时很快理解。
使用正则表达式模式
我们现在可以解释上面 re.findall("From:.*", text) 一行中的 .* 了。首先来看
- for line in re.findall("From:.", fh):
- print(line)
通过在 From: 后面添加一个 .,我们是要寻找 From: 之后另外的一个字符。因为 . 是查找除 \n 之外的任意字符,所以这会得到我们看不到的空格。我们可以多加一些点来验证这个情况
- for line in re.findall("From:...........", fh):
- print(line)
看起来加点就能让我们得到这一行的其余内容了。但这很单调乏味,而且我们不知道需要加多少个点。这就是星号 * 发挥作用的地方。
* 匹配 0 个或更多个其左侧的模式的实例。也就是说它会查找重复的模式。当我们查找重复模式时,我们说我们的搜索是「贪婪匹配」。如果我们没有查找重复模式,我们可以说我们的搜索是「非贪婪匹配」或「懒惰匹配」。
让我们使用 * 构建一个 . 的贪婪搜索
- for line in re.findall("From:.*", fh):
- print(line)
因为 * 匹配 0 个或多个其左侧模式的实例且 . 在其左侧,所以我们可以获取 From: 字段中的所有字符,直到该行结束。这样就用美丽而简洁的代码输出显示了一整行。
我们甚至可以更进一步只取出其中的名称。
- match = re.findall("From:.*", fh)
- for line in match:
- print(re.findall("\".*\"", line))
这里,我们先使用之前的做法通过 re.findall() 得到了包含 From:.* 模式的行的列表。接下来,我们遍历这个列表。在这一次训练中,我们都再执行一次 re.findall()。这一次,该函数先从匹配***个引号开始。
注意我们在***个引号后使用了一个反斜杠。这个反斜杠是一个用于给其它特殊字符转义的特殊字符。比如说,当我们想将引号用作字符串本身而不是特殊字符时,我们可以像 \" 这样使用反斜杠对其转义。如果我们不使用反斜杠转义上述模式,它就会变成 "".*"",Python 解释器就会将其看作是两个空字符串之间的一个句号和一个星号。这会出错并使该脚本中断。因此,我们这里必须使用反斜杠给引号转义。
在***个引号匹配后,.* 会获取这一行中下一个引号前的所有字符。当然,该模式中的下一个引号也经过了转义。这让我们可以得到引号之中的名称。每个名称都输出显示在方括号中,因为 re.findall 以列表形式返回匹配结果。
如果我们想得到电子邮箱地址呢?
- match = re.findall("From:.*", fh)
- for line in match:
- print(re.findall("\w\S*@.*\w", line))
看起来很简单,是不是?只是模式不一样而已。让我们详细看看。
这是我们匹配电子邮箱地址前半部分的方式:
- for line in match:
- print(re.findall("\w\S*@", line))
电子邮箱地址中总会包含一个 @ 符号,所以我们从它开始入手。电子邮箱地址中 @ 符号前面的部分可能包含字母数字字符,这意味着需要 \w。但是,由于某些电子邮箱地址包含句号或连接号,所以这还不够。我们增加了 \S 来查找非空白字符。但 \w\S 只能得到两个字符,所以增加 * 来重复查找。所以 @ 符号之前部分的模式是 \w\S*@。接下来看 @ 符号之后的部分。
- for line in match:
- print(re.findall("@.*", line))
域名通常包含字母数字字符、句号,有时候还会有连接号。这很简单,一个 . 就行。为了实现贪婪搜索,我们使用 * 来延展。这让我们可以匹配直到该行结束的任意字符。
简单看看这些行,我们可以发现每个电子邮箱地址都被放在一对尖括号 <> 之中。我们的模式 .* 会将右尖括号 > 包含进来。我们再调整一下:
- for line in match:
- print(re.findall("@.*\w", line))
电子邮箱地址是以字母数字字符结尾的,所以我们用 \w 作为这一模式的结尾。因此,@ 符号之后的部分是 .*\w,也就是说我们想要的模式是一组以字母数字字符结尾的任意类型的字符。这样就排除了 >。因此,完整的电子邮箱地址模式就为 \w\S*@.*\w
看起来有些麻烦。实际上正则表达式确实需要花些时间才能熟练,但一旦你掌握了,在写分析字符串的代码时就会快很多。接下来,我们会介绍一些常见的 re 函数,这些函数在重新组织这个语料库时会很有用。
常见的正则表达式函数
re.findall() 毫无疑问非常有用,re 模块还提供了一些同样方便的函数,其中包括:
- re.search()
- re.split()
- re.sub()
我们先逐一介绍一下这些函数,然后再将它们用来整理笨重难读的语料库。
1. re.search()
re.findall() 匹配的是一个模式在一个字符串中的所有实例然后以列表的形式返回它们,而 re.search() 匹配的是一个模式在一个字符串中的***个实例,然后以 re 匹配对象的形式返回它。
- match = re.search("From:.*", fh)
- print(type(match))
- print(type(match.group()))
- print(match)
- print(match.group())
与 re.findall() 类似,re.search() 也有两个参数。***个参数是所要匹配的模式,第二个是要在其中查找的字符串。这里为了简洁我们已经分配了 match 变量的结果。
因为 re.search() 返回的是一个 re 匹配对象,所以我们不能直接通过 print 展示其中的名称和电子邮箱地址。我们必须首先为其应用 group() 函数。我们已经在上面的代码中将它们输出显示了出来。如我们所见,group() 函数的作用是将匹配对象转换成字符串。
我们还能看到 print(match) 会显示字符串以及除字符串本身之外的属性,而 print(match.group()) 只会显示字符串。
2. re.split()
假设我们需要一种获取电子邮箱地址域名的快速方式。我们可以用 3 个正则表达式操作来完成。如下:
- address = re.findall("From:.*", fh)
- for item in address:
- for line in re.findall("\w\S*@.*\w", item):
- username, domain_name = re.split("@", line)
- print("{}, {}".format(username, domain_name))
***行我们很熟悉。我们返回一个字符串列表并为其分配一个变量,其中每个字符串都包含了 From: 字段的内容。接下来我们遍历整个列表,寻找电子邮箱地址。与此同时,我们遍历这些电子邮箱地址并使用 re 模块的 split() 函数以 @ 符号为分割符将每个电子邮件一分为二。***,我们将其显示出来。
3. re.sub()
re.sub() 是另一个很好用的 re 函数。顾名思义,它的功能是替换一个字符串的一部分。举个例子:
- sender = re.search("From:.*", fh)
- address = sender.group()
- email = re.sub("From", "Email", address)
- print(address)
- print(email)
其中***行和第二行的任务我们之前已经见过。第三行我们在 address 上应用 re.sub(); address 是电子邮件标头中的完整的 From: 字段。
re.sub() 有三个参数。***个是所要替换的子字符串,第二个是用来替换前者的字符串,第三个是主字符串本身。
pandas 的正则表达式
现在我们已经有了正则表达式的基础,我们可以试试一些更高级的功能。但是,我们需要将正则表达式与 pandas Python 数据分析库结合起来。在将数据整理成整洁的表格(也称为 dataframe)方面,pandas 非常有用,而且还能让我们从不同的角度理解数据。与正则表达式那经济简练的代码结合到一起,就好像是用快刀切黄油——简单利落。
如果你之前从未用过 pandas,也不要担心。我们会一步步地介绍代码,这样你绝不会迷失方向。正如我们在引言中提到的那样,如果你想详细学习这个库,请访问那个教程。
我们可以通过 Anaconda 或 pip 获取 pandas,详情参阅安装指南:
https://pandas.pydata.org/pandas-docs/stable/install.html
使用正则表达式和 pandas 整理电子邮件
我们的语料库是包含了数千封电子邮件的单个文本文件。我们将使用正则表达式和 pandas 将每封电子邮件的各部分整理到合适的类别中,以便对该语料库的读取和分析更简单。
我们将会将每封电子邮件整理成以下类别:
- sender_name(发件人名称)
- sender_address(发件人地址)
- recipient_address(收件人地址)
- recipient_name(收件人名称)
- date_sent(发送时间)
- subject(主题)
- email_body(邮件正文)
其中每个类别都会成为我们的 pandas dataframe 或表格中的一列。这会很有用,因为这让我们可以操作每一列本身。比如,这让我们可以编写代码来查找这些电子邮件来自哪些域名,而无需先编写代码将电子邮箱地址与其它部分隔开。本质上讲,将我们的数据集中的重要部分分门别类让我们可以之后用简练得多的代码获取细粒度的信息。反过来,简洁的代码也能减少我们的机器必须执行的运算的数量,这能加速我们的分析过程,尤其是当操作大规模数据集时。
准备脚本
我们上面已经了解过了一个简单的脚本。接下来让我们从头开始,了解如何将它们聚合到一起。
- import re
- import pandas as pd
- import email
- emails = []
- fh = open(r"test_emails.txt", "r").read()
首先在脚本最上面,我们按照标准惯例导入 re 和 pandas。我们也导入了 Python 的 email 包,电子邮件正文的处理尤其需要这个包。如果只使用正则表达式,那么电子邮件正文处理起来会相当复杂,甚至可能还需要一篇单独的教程才能说请。所以我们使用开发优良的 email 包来节省时间,让我们专注学习正则表达式。
接下来我们创建一个空列表 emails,用来存储字典。每个字典都将包含每封电子邮件的细节。
我们经常把代码的结果显示在屏幕上,以了解代码正确或出错的位置。但是,因为数据集中存在数千封电子邮件,所以这会在屏幕上打印出数千行,从而让本教程臃肿不堪。我们肯定不想不断滚动数千行结果。因此,正如我们在本教程开始时做的那样,我们打开并阅读一个语料库的缩短版。我们是通过人工的方式专为本教程准备的。但你自己练习的时候可以使用实际的数据集。每当你运行 print() 函数时,你都能在几秒之内在屏幕上看到数千行结果。
现在,开始使用正则表达式。
- contents = re.split(r"From r", fh)
- contents.pop(0)
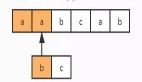
我们使用 re 模块的 split 函数来将 fh 中的整个文本块分割成单独的电子邮件构成的列表,我们将其分配给变量 contents。这很重要,因为我们希望通过一个 for 循环遍历这个列表,一封封地处理邮件。但我们怎么知道如何通过字符串 From r 来进行分割?因为我们在写这个脚本之前先查看了文件。我们不必仔细阅览这里的数千封邮件。只需看看前面几封邮件,了解一下其数据结构即可。可以看到,每封电子之前都有字符串 From r。我们给这个文本文件截了个图:

「From r」起头的电子邮件
绿色区域是***封邮件,蓝色区域是第二封邮件。可以看到,这两封邮件都是以 From r 开始的(红框所示)。
本教程使用 Fraudulent Email Corpus 的原因之一是表明当数据未经整理、不熟悉且没有说明文档时,只通过编写代码不能整理好它。这还需要人眼。正如刚才我们做的那样,我们必须阅读这个语料库,了解它的结构。此外,这些数据可能还需要大量清理工作;这个语料库也是如此。比如说,尽管我们使用本教程即将构建好的完整脚本算出这个数据集中有 3977 封邮件,但实际上还有更多。某些电子邮件不是以 From r 开始的,所以就没有被分开。但我们还是这样使用我们的数据集,否则本教程还会更长。
还要注意,我们使用了 contents.pop(0) 来避开列表中的***个元素。这是因为 From r 也在***封电子邮件之前。当分割该字符串时,它会在索引 0 的位置产生一个空字符串。我们即将编写的脚本是为电子邮件设计的。如果用它来操作空字符串,可能会报错。避开空字符串能让我们避开会造成脚本执行中断的错误。
用 for 循环获取每个名称和地址
现在,我们处理 contents 列表中的电子邮件。
- for item in contents:
- emails_dict = {}
在上面的代码中,我们使用了一个 for 循环来遍历 contents,以便我们依次处理每封邮件。我们创建了一个字典 emails_dict,其中有每封邮件的所有细节,比如发件人的地址和名称。实际上,这就是我们首先要查找的项。
这是一个三步式的过程。首先从查找 From: 字段开始。
- for item in contents: # First two lines again so that Jupyter runs the code.
- emails_dict = {}
- # Find sender's email address and name.
- # Step 1: find the whole line beginning with "From:".
- sender = re.search(r"From:.*", item)
第 1 步,使用 re.search() 函数查找整个 From: 字段。. 代表除 \n 之外的任意字符,* 将其延展到这一行的末尾。然后我们将其分配给变量 sender
但是,数据并不总是简单直观的,也可能有意外情况。比如,要是没有 From: 字符呢?这个脚本会报错并且中断。我们在第 2 步预先排除这种情况。
- # Step 2: find the email address and name.
- if sender is not None:
- s_email = re.search(r"\w\S*@.*\w", sender.group())
- s_name = re.search(r":.*<", sender.group())
- else:
- s_email = None
- s_name = None
为了避免因缺失 From: 字段而出错,我们使用 if 语句检查 sender 是否不为 None。如果是 None,则为 s_email 和 s_name 分配 None 值,这样这个脚本就不会意外中断了。
尽管本教程中使用正则表达式(和下面的 pandas)时看起来相当简单,但你的实际体验可能不会这么好。比如,我们看起来自然地使用了 if-else 语句来检查数据是否存在。但实际上,我们知道这一点的原因是我们在这个语料库上尝试了很多次这个脚本。编写代码是一个迭代式的过程。需要指出,就算教程看起来是一次成型的,但实际操作起来涉及到很多实验过程。
在第 2 步中,我们使用了与之前类似的正则表达式模式 \w\S*@.*\w 来匹配电子邮箱地址。
我们使用了不同的策略来匹配名称。每个名称的左边都有 From: 之中的冒号 :,且右边都有电子邮箱地址左边的左尖括号 <。因此,我们使用 :.*< 来查找姓名。我们马上就要去掉每个结果中的 : 和 <。
现在让我们显示结果,看看代码的效果。
- print("sender type: " + str(type(sender)))
- print("sender.group() type: " + str(type(sender.group())))
- print("sender: " + str(sender))
- print("sender.group(): " + str(sender.group()))
- print("\n")
注意,在每次应用 re.search() 时,我们不使用 sender 作为要搜索的字符串。我们打印了 sender 和 sender.group() 的类型以便了解它们的不同。看起来 sender 是一个 re 匹配对象,所以不能用 re.search() 进行搜索。但是,sender.group() 是一个字符串,正好适合 re.search() 处理。
让我们看看 s_email 和 s_name 是怎样的。
- print(s_email)
- print(s_name)
同样是匹配对象。每当我们对字符串应用 re.search() 时,都会得到匹配对象。我们必须将其转换成字符串对象。
在我们做这件事之前,要记得如果没有 From: 字段,sender 的值是 None;因此 s_email 和 s_name 的值也是 None。因此,我们必须再次检查这个情况,让该脚本不会意外中断。首先来看如何使用 s_email 来构建代码。
- # Step 3A: assign email address as string to a variable.
- if s_email is not None:
- sender_email = s_email.group()
- else:
- sender_email = None
- # Add email address to dictionary.
- emails_dict["sender_email"] = sender_email
在第 3A 步,我们使用一个 if 语句来检查 s_email 是否不是 None,否则它会报错并中断脚本。
然后,我们将 s_email 匹配对象转换成字符串并分配给变量 sender_email。我们将其添加到 emails_dict 字典,这让我们之后可以非常轻松地将这些细节变成 pandas dataframe。
我们在第 3B 步为 s_name 做几乎一样的事情。
- # Step 3B: remove unwanted substrings, assign to variable.
- if s_name is not None:
- sender_name = re.sub("\s*<", "", re.sub(":\s*", "", s_name.group()))
- else:
- sender_name = None
- # Add sender's name to dictionary.
- emails_dict["sender_name"] = sender_name
正如我们之前的做法,我们首先检查 s_name 是否不是 None。
然后,我们使用 re 模块的 re.sub() 函数两次,之后再将所得到的字符串分配给一个变量。在***次使用 re.sub() 时,我们移除冒号以及其和名称之间的任何空格字符。我们使用空字符串 "" 替换 :\s* 即可实现。然后我们移除名称另一边的空格字符和尖括号,同样用一个空字符串替换它。***,在将其分配给变量 sender_name 后,我们将其添加到字典。
检查结果:
- print(sender_email)
- print(sender_name)
***。我们分离出了发件人的电子邮箱地址和名称,我们也将它们添加进了字典,后面会有用的。
现在,我们已经找到了发件人的电子邮箱地址和名称,我们再通过同样的步骤获取收件人的电子邮箱地址和名称,并加入字典。
首先,我们查找 To: 字段。
- rerecipient = re.search(r"To:.*", item)
接下来,我们预先设定好 recipient 为 None 的情况。
- if recipient is not None:
- r_email = re.search(r"\w\S*@.*\w", recipient.group())
- r_name = re.search(r":.*<", recipient.group())
- else:
- r_email = None
- r_name = None
如果 recipient 不为 None,我们就使用 re.search() 查找包含电子邮箱地址和收件人名称的匹配对象。否则,我们就将 r_email 和 r_name 赋值为 None。
然后,我们将匹配对象变成字符串,并将它们加入字典。
- if r_email is not None:
- recipient_email = r_email.group()
- else:
- recipient_email = None
- emails_dict["recipient_email"] = recipient_email
- if r_name is not None:
- rerecipient_name = re.sub("\s*<", "", re.sub(":\s*", "", r_name.group()))
- else:
- recipient_name = None
- emails_dict["recipient_name"] = recipient_name
因为 From: 和 To: 字段的结构是一样的,所以我们可以为两者使用同样的代码——只需针对性地稍微调整一下即可。
获取电子邮件日期
现在获取电子邮件的发送日期:
- for item in contents: # First two lines again so that Jupyter runs the code.
- emails_dict = {}
- date_field = re.search(r"Date:.*", item)
我们使用获取 From: 和 To: 字段一样的代码来获取 Date: 字段。而且和上面的操作一样,我们要检查赋值为 date_field 的 Date: 字段是否为 None。
- if date_field is not None:
- date = re.search(r"\d+\s\w+\s\d+", date_field.group())
- else:
- date = None
- print(date_field.group())
我们输出显示了 date_field.group(),以便我们更清楚地了解这个字符串的结构。它包含了 DD MMM YYYY 格式的日期以及具体的时间。我们只需要日期。针对日期的代码和针对名称与电子邮箱地址的代码差不多,但却更加简单。也许这里最让人迷惑的是正则表达式模式 \d+\s\w+\s\d+。
日期是以一个数字开始的。因此我们使用 \d 表示它。但是,DD 部分的日期可能是一个数字,也可能是两个数字。因此这里的 + 号就很重要了。在正则表达式中,+ 匹配 1 个或多个其左侧模式的实例。因此 \d+ 可以匹配 DD 部分,不管是一个数字还是两个数字。
在那之后,有一个空格。用 \s 代表,可以查找空白字符。月份由三个字母组成,因此用 \w+。然后是另一个空格 \s。年份由数字组成,所以再次使用 \d+。
完整的模式 \d+\s\w+\s\d+ 是有效的,因为它是两边都有空白字符的精确模式。
接下来,我们想之前一样检查 None 值。
- if date is not None:
- datedate_sent = date.group()
- date_star = date_star_test.group()
- else:
- date_sent = None
- emails_dict["date_sent"] = date_sent
如果 date 不是 None,我们就将其从匹配对象变成字符,并分配给变量 date_sent。然后插入字典。
在继续前进之前,我们应该指出:+ 和 * 看起来相似但结果非常不同。我们以这里的日期字符串为例看看。
- date = re.search(r"\d+\s\w+\s\d+", date_field.group())
- # What happens when we use * instead?
- date_star_test = re.search(r"\d*\s\w*\s\d*", date_field.group())
- datedate_sent = date.group()
- date_star = date_star_test.group()
- print(date_sent)
- print(date_star)
如果我们使用 *,我们会匹配 0 或更多个实例;而 + 是匹配 1 或多个实例。我们显示了两种情况的结果。差距很大。如你所见 + 得到了完整的日期,而 * 则得到了一个空格和数字 1.
接下来,获取电子邮件的主题行。
获取电子邮件主题
和之前一样,我们使用同样的代码和代码结构来获取我们所需的信息。
- for item in contents: # First two lines again so that Jupyter runs the code.
- emails_dict = {}
- subject_field = re.search(r"Subject: .*", item)
- if subject_field is not None:
- subject = re.sub(r"Subject: ", "", subject_field.group())
- else:
- subject = None
- emails_dict["subject"] = subject
我们越来越熟悉使用正则表达式了。这和之前的代码基本一样,只是我们使用空字符串替换了 "Subject: ",以便只得到主题本身。
获取电子邮件正文
我们的字典要插入的***一项是电子邮件正文。
- full_email = email.message_from_string(item)
- body = full_email.get_payload()
- emails_dict["email_body"] = body
将邮件标头与正文分开是一项很复杂的任务,尤其是当很多标头都不一样时。在原始的未整理的数据中,一致的情况很少见。幸运的是,这项工作已经被完成了。Python 的 email 包非常适合这项任务。我们之前已经导入了这个包。现在我们将 message_from_string() 应用在 item 上,将整封电子邮件变成一个 email 消息对象。消息对象包含一个标头和一个 payload,分别对应电子邮件的标头和正文。
接下来,我们在这个消息对象上应用 get_payload() 函数。这个函数可以分离出电子邮件的主体。我们将其分配给变量 body,然后插入到我们的 emails_dict 字典中的 "email_body" 下。
你可能会问:为什么要使用 email 包,而不使用正则表达式?因为目前来看,如果没有大量数据清理工作,使用正则表达式还不能很好地做到这一点。这意味着需要另外一些代码,还需要再写一个教程才能说请。
但值得说明一下我们做出这个决定的方式。但是,首先我们需要了解一下方括号 [ ] 在正则表达式中的含义。
[ ] 匹配放置于其中的任意字符。比如如果我们想在一个字符串中查找 a、b 或 c,我们可以使用 [abc] 作为模式。我们前面讨论的模式也适用。[\w\s] 是查找字母数字或空白字符。但 . 是例外,它在 [ ] 中就表示句号。
现在我们可以更好地理解我们使用 email 包的原因了。
看一看这个数据集,可以发现这个电子邮件标头终止于 "Status: 0" 或 "Status: R0";而正文在下一封电子邮件的 "From r" 字符串之前终止。因此我们可以使用 Status:\s*\w*\n*[\s\S]*From\sr* 来获取电子邮件正文。[\s\S]* 可用于大量文本、数字和标点符号构成的字符串,因为它既能搜索空白字符,也能搜索非空白字符。
不幸的是,有些邮件包含不止一个 Status: 字符串,还有一些邮件不包含 From r。这意味着我们分割得到的电子邮件数量会多于或少于电子邮件列表字典的数量。就会与我们已经得到的其它类别不匹配。这会在使用 pandas 时出现问题。因此,我们选择使用 email 包。
创建字典列表
***,将字典 emails_dict 附加到 emails 列表之后:
- emails.append(emails_dict)
你可能需要输出显示看看 emails 列表,看看效果。你也可以运行 print(len(emails_dict)) 来了解列表中有多少字典,即电子邮件。正如我们之前提到的,完整的语料库包含 3977 个。我们的小测试文件包含 7 个。以下是完整代码:
- import re
- import pandas as pd
- import email
- emails = []
- fh = open(r"test_emails.txt", "r").read()
- contents = re.split(r"From r",fh)
- contents.pop(0)
- for item in contents:
- emails_dict = {}
- sender = re.search(r"From:.*", item)
- if sender is not None:
- s_email = re.search(r"\w\S*@.*\w", sender.group())
- s_name = re.search(r":.*<", sender.group())
- else:
- s_email = None
- s_name = None
- if s_email is not None:
- sender_email = s_email.group()
- else:
- sender_email = None
- emails_dict["sender_email"] = sender_email
- if s_name is not None:
- sender_name = re.sub("\s*<", "", re.sub(":\s*", "", s_name.group()))
- else:
- sender_name = None
- emails_dict["sender_name"] = sender_name
- rerecipient = re.search(r"To:.*", item)
- if recipient is not None:
- r_email = re.search(r"\w\S*@.*\w", recipient.group())
- r_name = re.search(r":.*<", recipient.group())
- else:
- r_email = None
- r_name = None
- if r_email is not None:
- recipient_email = r_email.group()
- else:
- recipient_email = None
- emails_dict["recipient_email"] = recipient_email
- if r_name is not None:
- rerecipient_name = re.sub("\s*<", "", re.sub(":\s*", "", r_name.group()))
- else:
- recipient_name = None
- emails_dict["recipient_name"] = recipient_name
- date_field = re.search(r"Date:.*", item)
- if date_field is not None:
- date = re.search(r"\d+\s\w+\s\d+", date_field.group())
- else:
- date = None
- if date is not None:
- datedate_sent = date.group()
- else:
- date_sent = None
- emails_dict["date_sent"] = date_sent
- subject_field = re.search(r"Subject: .*", item)
- if subject_field is not None:
- subject = re.sub(r"Subject: ", "", subject_field.group())
- else:
- subject = None
- emails_dict["subject"] = subject
- # "item" substituted with "email content here" so full email not displayed.
- full_email = email.message_from_string(item)
- body = full_email.get_payload()
- emails_dict["email_body"] = "email body here"
- emails.append(emails_dict)
- # Print number of dictionaries, and hence, emails, in the list.
- print("Number of emails: " + str(len(emails_dict)))
- print("\n")
- # Print first item in the emails list to see how it looks.
- for key, value in emails[0].items():
- print(str(key) + ": " + str(emails[0][key]))
我们已经输出显示了 emails 列表中的***项,显然这是带有 key 和值配对的字典。因为我们使用了 for 训练,所以每个字典都有相同的 key 和不同的值。
我们使用 email content here 替换了 item,这样我们就无需输出所有电子邮件来占领我们的屏幕了。如果你在操作实际数据集这样显示,你会看到整个电子邮件。
使用 pandas 操作数据
将字典放入列表后,我们就能使用 pandas 库来轻松操作这些数据了。每个 key 都会成为一个列标题,每个值都是一列中的一行。
我们只需应用这些代码:
- import pandas as pd # Module imported above, imported again as reminder.
- emails_df = pd.DataFrame(emails)
只需一行代码,我们就使用 pandas 的 DataFrame() 函数将 emails 字典列表变成了一个 dataframe。我们也为其分配了一个变量。
完成了。现在我们有了复杂精细的 pandas dataframe。这是一个简练整洁的表格,包含了我们从这些电子邮件中提取的所有信息。
让我们看看前面几行:
- pd.DataFrame.head(emails_df, n=3)
dataframe.head() 函数只会展示前面几行,而不会展示整个数据集。它有一个参数。还有一个可选参数可以指定所要展示的行数。这里 n=3 表示我们想看 3 行。
我们也可以精确查找我们想要的东西。比如,我们可以查找所有来自特定域名的邮件。但是,让我们学习另一个正则表达式模式以提升我们查找所需项的准确性。
竖线符号 | 会查找其两边的字符,比如 a|b 会查找 a 或 b。
| 看起来似乎和 [ ] 一样,但实际并不一样。假如我们要查找 crab 或 lobster 或 isopod,那么使用 crab|lobster|isopod 会比使用 [crablobsterisopod] 要合理得多。前者是查找其中每个词,而后者是搜索其中每个字母。
现在我们使用 | 来查找来自一个域名或另一个域名的电子邮件。
- emails_df[emails_df["sender_email"].str.contains("maktoob|spinfinder")]
这是一行相当长的代码。让我们从内部开始解读。
emails_df['sender_email'] 是选择有 sender_email 标签的一列。接下来,str.contains(maktoob|spinfinder) 是指如果在该列中找到了 maktoob 或 spinfinder,则返回 Ture。***,外围的 emails_df[] 返回一个行视图,其中 sender_email 列包含了目标子字符串。干的漂亮!
我们也可以查看每个单元格的电子邮件。要做到这一点,我们要做 4 步。第 1 步,查找 sender_email 列中包含 @maktoob 字符串的行的索引。注意我们使用正则表达式的方式。
- # Step 1: find the index where the "sender_email" column contains "@maktoob.com".
- index = emails_df[emails_df["sender_email"].str.contains(r"\w\S*@maktoob.com")].index.values
第 2 步,我们使用该索引查找电子邮箱地址,loc[] 方法返回一个 Series 对象,其具有几种不同的属性。我们用以下方式显示输出其结果。
- # Step 2: use the index to find the value of the cell in the "sender_email" column.
- # The result is returned as pandas Series object
- address_Series = emails_df.loc[index]["sender_email"]
- print(address_Series)
- print(type(address_Series))
第 3 步,我们从这个 Series 对象提取电子邮箱地址,就像我们从一个列表提取项一样。你可以看到它现在的类型是类(class)。
- # Step 3: extract the email address, which is at index 0 in the Series object.
- address_string = address_Series[0]
- print(address_string)
- print(type(address_string))
第 4 步,提取电子邮件正文。
- # Step 4: find the value of the "email_body" column where the "sender email" column is address_string.
- print(emails_df[emails_df["sender_email"] == address_string]["email_body"].values)
在第 4 步中,emails_df['sender_email'] == "james_ngola2002@maktoob.com" 是查找 sender_email 列中包含 james_ngola2002@maktoob.com 的行。接下来,['email_body'].values 查找对应行的 email_body 列。***,得到结果值。
可以看到,使用正则表达式的方式多种多样,而且能很好地与 pandas 搭配使用。
其它资源
正则表达式自从生物学迈向工程领域之后,多年来发展迅速。现在,正则表达式已经在各种不同的编程语言中得到了应用,其中某些变体已经超越了其基本模式。
- 在本教程中,我们使用 Python 进行了练习,如果你有进一步探索的兴趣,可以参阅这个帖子:https://stackoverflow.com/questions/4644847/list-of-all-regex-implementations。
- 维基百科也有一个比较不同正则表达式引擎的表格:https://en.m.wikipedia.org/wiki/Comparison_of_regular_expression_engines#Part_1
- 一篇教程肯定不能说尽正则表达式的全部。完整参考可参阅 Python 的 re 模块的文档:https://docs.python.org/3/library/re.html。谷歌也有一个快速参考:https://developers.google.com/edu/python/regular-expressions
- 如果你需要数据集来做实验,Kaggle 和 StatsModels 很不错。
- 这里有个正则表达式快速参考表:https://github.com/dmikalova/sublime-cheat-sheets/blob/master/cheat-sheets/Regular%20Expressions.cheatsheet。这是为 Sublime 设计的,但对其它工具而言也很方便。
原文链接:https://www.dataquest.io/blog/regular-expressions-data-scientists/
【本文是51CTO专栏机构“机器之心”的原创译文,微信公众号“机器之心( id: almosthuman2014)”】