简介
在大数据迅速发展的今天,很大一部分支持来自于底层技术的不断发展,其中非常重要的一点就是系统资源的管理和控制,大数据平台的核心就是对资源的调度管理,在调度和管理之后如何对这些资源进行控制便成了另一个重要的问题。大数据系统中用户成千上万的作业进程跑在集群中,如果不能对这些进程的资源进行控制,那么大数据平台将变得举步维艰,整个集群便会随时崩溃。同时,大数据作业的调度也是基于资源的配额进行分配,大数据的作业本身就承载了资源配额的属性,但是这些作业是否按照配额进行运行和计算,是否超过了指定的配额导致overuse,是否达不到指定的配额导致资源浪费,这一直以来都是大数据平台面对和要解决的问题。
本文针对大数据平台中资源控制这个层面来详细介绍资源控制在不同操作系统上的具体技术实现,以及大数据平台和资源控制的集成。
资源控制使用的系统功能
cgroup简介
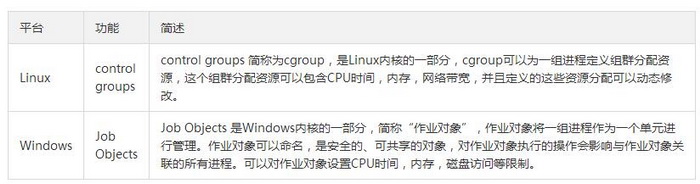
cgroup是Linux内核的一部分,cgroup可以为一组进程定义组群分配资源,这个组群分配资源可以包含CPU时间,内存,网络带宽,并且定义的这些资源分配可以动态修改。cgroup以一种层级结构(hierarchical)聚合和管理进程,将所有任务进程以文件夹的形式组成一个控制族群树,子控制组自动继承父节点的特定属性,子控制组还可以有自己特定的属性。
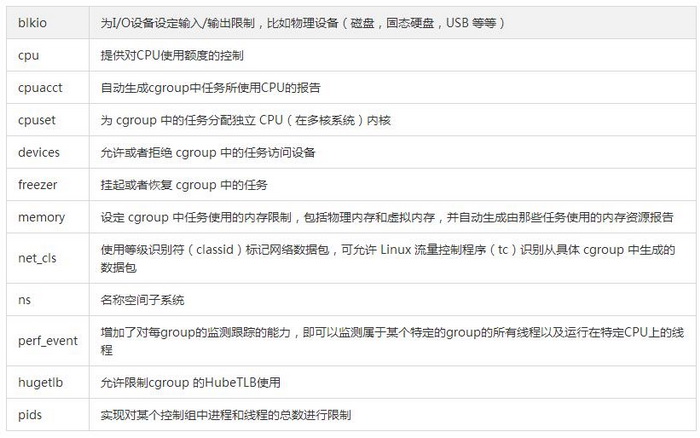
cgroup提供一些subsystem作为控制族群树的根节点,所有的任务进程都以这些子系统为入口按树状结构设置资源配额。Red Hat Linux 7.3 提供 12 个 cgroup 子系统,根据名称和功能列出如下。
cgroup各子系统功能
可通过以下命令查看操作系统支持的cgroup子系统,同时显示各个子系统挂载的根目录(也可以查看系统文件/proc/mount或者使用命令lssubsys -a):

cgroup的操作没有提供系统API调用或者命令行,而是直接访问cgroup mount的这个文件系统,举个例子描述下cgroup接口的使用方式。
1. 创建一个目录用于指定需要控制的作业进程,创建之后系统在会每一级自动生成所有的配置文件,可以将该目录认为是一个资源控制组。

2. 添加需要的进程到该资源控制组,可以添加多个进程ID
3. 设置该资源控制组的物理内存使用配额

如果不进行设置,默认情况下,继承根目录的内存配置,即系统内存。
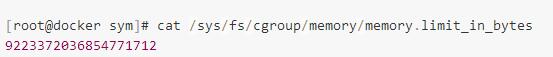
下面介绍下大数据系统中常用的配额设置。
内存:物理内存的设置文件为memory子系统下的memory.limit_in_bytes,虚拟内存为memory.memsw.limit_in_bytes。如果同时设置这两个参数,需要先设置memory.limit_in_bytes,因为虚拟内存的配额只有在物理内存用完后开始生效。在Linux系统上,只有当物理内存消耗完后才开始消耗虚拟内存,超过配额后再申请的话就会触发OOM kill掉进程。注意:OOM killer也可以关闭,需要向memory.oom_control中写入1,这样当进程尝试申请的内存超过允许,那么它就会被暂停,直到额外的内存被释放。
CPU:对CPU的配额控制是通过CPU子系统下的cpu.cfs_period_us和cpu.cfs_quota_us两个参数控制。cpu.cfs_period_us表示重新分配CPU时间的周期,默认为 100000,即百毫秒。cpu.cfs_quota_us就是在这期间内可使用的 cpu 时间,默认 -1,即***制。所以默认情况下CPU的使用为100%。如果需要将CPU的使用设置为50%,可以将 cpu.cfs_quota_us设为 50000,cpu.cfs_period_us保持100000,表示每隔100毫秒分配CPU时间,持续使用50毫秒。对CPU的限制不像内存,超过配额后再申请的话就会触发OOM kill掉进程,CPU设置配额后进程不会超过该配额的使用。
JobObjects简介
Windows平台也有对应的内核对象用来控制作业对系统资源的访问,而且控制的范围比Linux广,包括剪切板,关闭Windows的权限,窗口权限等。不同于Linux,Windows通过系统API来实现对作业对象的访问。
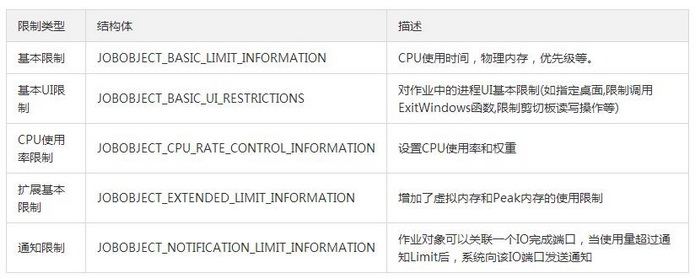
Windows JobObjects支持的列表
Windows上使用内核作业对象的流程大概如下:
- 创建内核作业对象:调用::CreateJobObject()创建一个内核对象,刚创建的对象没有和进程关联。
- 把限制属性设置到作业对象:调用:: SetInformationJobObject()可以设置如上列表中的限制属性到该作业对象。
- 将进程加入到作业对象:调用:: AssignProcessToJobObject()将进程加入到作业中,如果该进程产生子进程,那么该子进程会自动成为作业的一部分。
- 关闭作业对象:调用:: CloseHandle()关闭作业对象的句柄。
需要注意以下几点:
- 一个进程属于一个作业对象之后,不能再assign给另一个作业对象。
- 在Windows开启UAC的系统中,没有提示权限的进程会被加入到一个默认的兼容性系统作业对象中,所以必须使用CREATE_BREAKAWAY_FROM_JOB参数创建进程使该进程脱离默认的作业对象。
- 新启动的进程***使用CREATE_SUSPEND参数这样可以在进程启动之前加入到作业对象中,防止起启动的新的子进程逃离作业对象。
Windows对于内存的管理与Linux不同,Windows上的物理内存指的是WorkingSet,虚拟内存指的是committed memory,在Windows任务管理器中看的话物理内存指的是“工作设置(内存)”,虚拟内存指的是“提交大小”。CPU通过CpuRate设置,CpuRate的含义是线程在每10000个处理器调度周期内被调度的周期数,比如需要限制到20%,就设置CpuRate为2000。
下面直接以C++代码为例来说明如果创建和管理作业对象,同时包含如何与ACE进程对象如何集成。
Docker容器资源控制
目前在Linux生态圈,用Docker发布和运行程序基本已经成为一个标准,同时用Docker管理本地私有云也越来越流行,尤其对于用Kubernetes管理的容器云,如何限制容器资源变得非常重要。
在RedHat上,Docker拥有自己的cgroup控制目录,位于各个子系统下的system.slice的文件夹里面。当我们启动一个docker容器之后,就会产生这个容器ID开头的一个子目录,用来配置这个容器里面的所有进程对系统资源的使用。
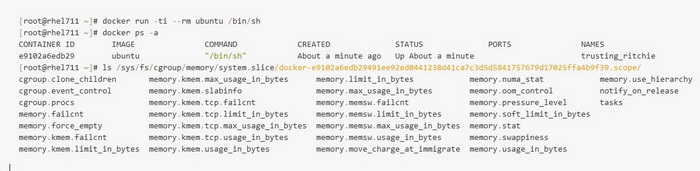
其中task目录中存放的为容器中进程的PID,以我们这个示例来说,我们在容器中启动了 /bin/sh 进程,这个进程ID为2730。

云计算中Docker容器的资源收集
目前通过Docker容器部署大数据平台也比较流行,但是大数据平台需要获取每个节点运行环境的资源配额,对于已经运行在Docker容器里面的进程,如何判断自己拥有多少系统资源也可以通过cgroup文件系统获取。但是Docker容器里面看到的cgroup的文件目录和宿主机不同,docker容器里面没有system.slice文件夹,直接以/sys/fs/cgroup/开头,可以通过命令查看。所以可以通过这个目录下的memory.limit_in_bytes获取容器自身的物理内存配额。对于容器中CPU core数目的获取,可以通过这个公式获取到近似的core数:min(1, (int)ceil(cpu.cfs_quota_us/cpu.cfs_period_us))。

用Kubernetes部署的容器平台需要提前定义资源配额,否则容器可以使用到宿主机的所有资源,资源配额在YAML文件的resources中定义:
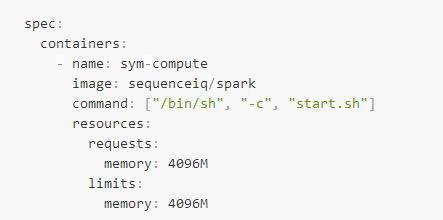
YARN容器管理
作为容器管理的平台,Kubernetes主要用来在容器中部署分布式应用程序,YARN作为一个资源管理平台也支持容器的管理,主要用来以容器的方式运行大数据作业。像Spark将YARN作为资源管理器运行Spark job。
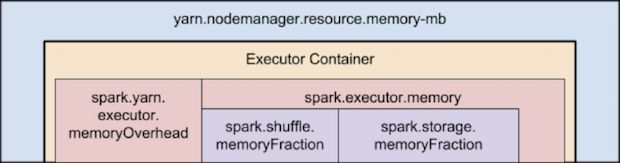
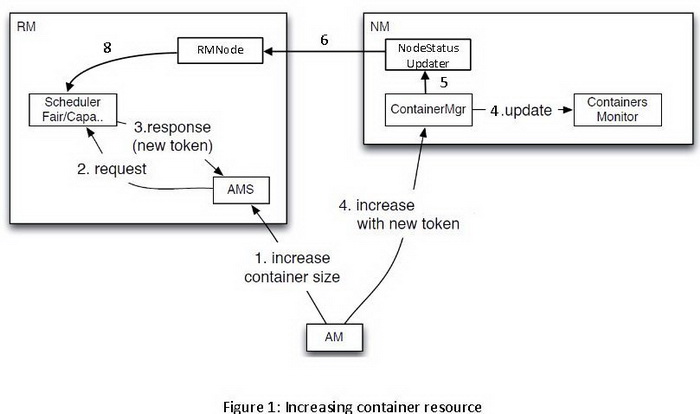
YARN支持对现有容器大小的调整(cgroup和jobobjects都支持修改资源配额),当用户从YARN申请了一些固定大小的容器,想改变容器资源配额的大小的时候不需要释放掉这些容器重新申请,YARN支持动态改变已经分配的容器的大小。
结束语
随着大数据和云计算技术的发展,资源控制和管理作为底层技术已经非常成熟,掌握这些技术便可以在大数据处理中游刃有余。