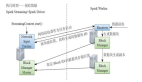
在面向流处理的分布式计算中,经常会有这种需求,希望需要处理的某个数据集能够不随着流式数据的流逝而消失。
以spark streaming为例,就是希望有个数据集能够在当前批次中更新,再下个批次后又可以继续访问。一个最简单的实现是在driver的内存中,我们可以自行保存一个大的内存结构。这种hack的方式就是我们无法利用spark提供的分布式计算的能力。
对此,spark streaming提供了stateful streaming, 可以创建一个有状态的DStream,我们可以操作一个跨越不同批次的RDD。
1 updateStateByKey
该方法提供了这样的一种机制: 维护了一个可以跨越不同批次的RDD, 姑且成为StateRDD,在每个批次遍历StateRDD的所有数据,对每条数据执行update方法。当update方法返回None时,淘汰StateRDD中的该条数据。
具体接口如下:
/**
* Return a new "state" DStream where the state for each key is updated by applying
* the given function on the previous state of the key and the new values of each key.
* Hash partitioning is used to generate the RDDs with `numPartitions` partitions.
* @param updateFunc State update function. If `this` function returns None, then
* corresponding state key-value pair will be eliminated.
* @param numPartitions Number of partitions of each RDD in the new DStream.
* @tparam S State type
*/
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S],
numPartitions: Int
): DStream[(K, S)] = ssc.withScope {
updateStateByKey(updateFunc, defaultPartitioner(numPartitions))
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
即用户需要实现一个updateFunc的函数,该函数的参数:
Seq[V] 该批次中相同key的数据,以Seq数组形式传递
Option[S] 历史状态中的数据
返回值: 返回需要保持的历史状态数据,为None时表示删除该数据
def updateStateFunc(lines: Seq[Array[String]], state: Option[Array[String]]): Option[Array[String]] = {...}
- 1.
这种做法简单清晰明了,但是其中有一些可以优化的地方:
a) 如果DRDD增长到比较大的时候,而每个进入的批次数据量相比并不大,此时每次都需要遍历DRDD,无论该批次中是否有数据需要更新DRDD。这种情况有的时候可能会引发性能问题。
b) 需要用户自定义数据的淘汰机制。有的时候显得不是那么方便。
c) 返回的类型需要和缓存中的类型相同。类型不能发生改变。
2 mapWithState
该接口是对updateSateByKey的改良,解决了updateStateFunc中可以优化的地方:
* :: Experimental ::
* Return a [[MapWithStateDStream]] by applying a function to every key-value element of
* `this` stream, while maintaining some state data for each unique key. The mapping function
* and other specification (e.g. partitioners, timeouts, initial state data, etc.) of this
* transformation can be specified using [[StateSpec]] class. The state data is accessible in
* as a parameter of type [[State]] in the mapping function.
*
* Example of using `mapWithState`:
* {{{
* // A mapping function that maintains an integer state and return a String
* def mappingFunction(key: String, value: Option[Int], state: State[Int]): Option[String] = {
* // Use state.exists(), state.get(), state.update() and state.remove()
* // to manage state, and return the necessary string
* }
*
* val spec = StateSpec.function(mappingFunction).numPartitions(10)
*
* val mapWithStateDStream = keyValueDStream.mapWithState[StateType, MappedType](spec)
* }}}
*
* @param spec Specification of this transformation
* @tparam StateType Class type of the state data
* @tparam MappedType Class type of the mapped data
*/
@Experimental
def mapWithState[StateType: ClassTag, MappedType: ClassTag](
spec: StateSpec[K, V, StateType, MappedType]
): MapWithStateDStream[K, V, StateType, MappedType] = {
new MapWithStateDStreamImpl[K, V, StateType, MappedType](
self,
spec.asInstanceOf[StateSpecImpl[K, V, StateType, MappedType]]
)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
其中spec封装了用户自定义的函数,用以更新缓存数据:
mappingFunction: (KeyType, Option[ValueType], State[StateType]) => MappedType
- 1.
实现样例如下:
val mappingFunc = (k: String, line: Option[Array[String]], state: State[Array[String]]) => {...}
- 1.
参数分别代表:
数据的key: k
RDD中的每行数据: line
state: 缓存数据
当对state调用remove方法时,该数据会被删除。
注意,如果数据超时,不要调用remove方法,因为spark会在mappingFunc后自动调用remove。
a) 与updateStateByKey 每次都要遍历缓存数据不同,mapWithState每次遍历每个批次中的数据,更新缓存中的数据。对于缓存数据较大的情况来说,性能会有较大提升。
b) 提供了内置的超时机制,当数据一定时间内没有更新时,淘汰相应数据。
注意,当有数据到来或者有超时发生时,mappingFunc都会被调用。
3 checkpointing
通常情况下,在一个DStream钟,对RDD的各种转换而依赖的数据都是来自于当前批次中。但是当在进行有状态的transformations时,包括updateStateByKey/reduceByKeyAndWindow 、mapWithSate,还会依赖于以前批次的数据,RDD的容错机制,在异常情况需要重新计算RDD时,需要以前批次的RDD信息。如果这个依赖的链路过长,会需要大量的内存,即使有些RDD的数据在内存中,不需要计算。此时spark通过checkpoint来打破依赖链路。checkpoint会生成一个新的RDD到hdfs中,该RDD是计算后的结果集,而没有对之前的RDD依赖。
此时一定要启用checkpointing,以进行周期性的RDD Checkpointing
在StateDstream在实现RDD的compute方法时,就是将之前的PreStateRDD与当前批次中依赖的ParentRDD进行合并。
而checkpoint的实现是将上述合并的RDD写入HDFS中。
现在checkpoint的实现中,数据写入hdfs的过程是由一个固定的线程池异步完成的。一种存在的风险是上次checkpoint的数据尚未完成,此次又来了新的要写的checkpoint数据,会加大集群的负载,可能会引发一系列的问题。
4 checkpoint周期设置:
对mapWithStateByKey/updateStateByKey返回的DStream可以调用checkpoint方法设置checkpoint的周期。注意传递的时间只能是批次时间的整数倍。
另外,对于mapWithState而言,checkpoint执行时,才会进行数据的删除。 State.remove方法只是设置状态,标记为删除,数据并不会真的删除。 SnapShot方法还是可以获取得到。