在本节内容之前,我们已经对如何引入Sleuth跟踪信息和搭建Zipkin服务端分析跟踪延迟的过程做了详细的介绍,相信大家对于Sleuth和Zipkin已经有了一定的感性认识。接下来,我们介绍一下关于Zipkin收集跟踪信息的过程细节,以帮助我们更好地理解Sleuth生产跟踪信息以及输出跟踪信息的整体过程和工作原理。
数据模型
我们先来看看Zipkin中关于跟踪信息的一些基础概念。由于Zipkin的实现借鉴了Google的Dapper,所以它们有着类似的核心术语,主要有下面几个内容:
- Span:它代表了一个基础的工作单元。我们以HTTP请求为例,一次完整的请求过程在客户端和服务端都会产生多个不同的事件状态(比如下面所说的四个核心Annotation所标识的不同阶段),对于同一个请求来说,它们属于一个工作单元,所以同一HTTP请求过程中的四个Annotation同属于一个Span。每一个不同的工作单元都通过一个64位的ID来唯一标识,称为Span ID。另外,在工作单元中还存储了一个用来串联其他工作单元的ID,它也通过一个64位的ID来唯一标识,称为Trace ID。在同一条请求链路中的不同工作单元都会有不同的Span ID,但是它们的Trace ID是相同的,所以通过Trace ID可以将一次请求中依赖的所有依赖请求串联起来形成请求链路。除了这两个核心的ID之外,Span中还存储了一些其他信息,比如:描述信息、事件时间戳、Annotation的键值对属性、上一级工作单元的Span ID等。
- Trace:它是由一系列具有相同Trace ID的Span串联形成的一个树状结构。在复杂的分布式系统中,每一个外部请求通常都会产生一个复杂的树状结构的Trace。
- Annotation:它用来及时地记录一个事件的存在。我们可以把Annotation理解为一个包含有时间戳的事件标签,对于一个HTTP请求来说,在Sleuth中定义了下面四个核心Annotation来标识一个请求的开始和结束:
cs(Client Send):该Annotation用来记录客户端发起了一个请求,同时它也标识了这个HTTP请求的开始。
sr(Server Received):该Annotation用来记录服务端接收到了请求,并准备开始处理它。通过计算sr与cs两个Annotation的时间戳之差,我们可以得到当前HTTP请求的网络延迟。
ss(Server Send):该Annotation用来记录服务端处理完请求后准备发送请求响应信息。通过计算ss与sr两个Annotation的时间戳之差,我们可以得到当前服务端处理请求的时间消耗。
cr(Client Received):该Annotation用来记录客户端接收到服务端的回复,同时它也标识了这个HTTP请求的结束。通过计算cr与cs两个Annotation的时间戳之差,我们可以得到该HTTP请求从客户端发起开始到接收服务端响应的总时间消耗。
- BinaryAnnotation:它用来对跟踪信息添加一些额外的补充说明,一般以键值对方式出现。比如:在记录HTTP请求接收后执行具体业务逻辑时,此时并没有默认的Annotation来标识该事件状态,但是有BinaryAnnotation信息对其进行补充。
收集机制
在理解了Zipkin的各个基本概念之后,下面我们结合前面章节中实现的例子来详细介绍和理解Spring Cloud Sleuth是如何对请求调用链路完成跟踪信息的生产、输出和后续处理的。
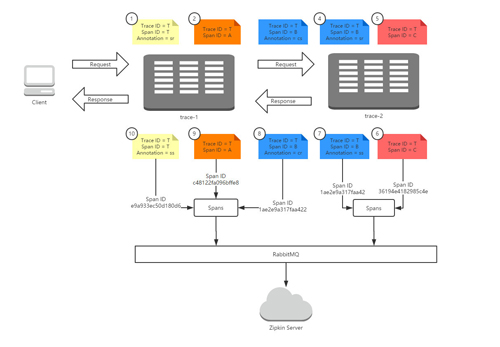
首先,我们来看看Sleuth在请求调用时是怎么样来记录和生成跟踪信息的。下图展示了我们在本章节中实现示例的运行全过程:客户端发送了一个HTTP请求到trace-1,trace-1依赖于trace-2的服务,所以trace-1再发送一个HTTP请求到trace-2,待trace-2返回响应之后,trace-1再组织响应结果返回给客户端。
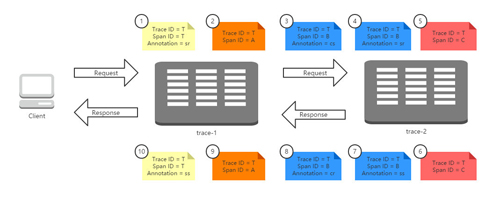
在上图的请求过程中,我们为整个调用过程标记了10个标签,它们分别代表了该请求链路运行过程中记录的几个重要事件状态,我们根据事件发生的时间顺序我们为这些标签做了从小到大的编号,1代表请求的开始、10代表请求的结束。每个标签中记录了一些我们上面提到过的核心元素:Trace ID、Span ID以及Annotation。由于这些标签都源自一个请求,所以他们的Trace ID相同,而标签1和标签10是起始和结束节点,它们的Trace ID与Span ID是相同的。
根据Span ID,我们可以发现在这些标签中一共产生了4个不同ID的Span,这4个Span分别代表了这样4个工作单元:
- Span T:记录了客户端请求到达trace-1和trace-1发送请求响应的两个事件,它可以计算出了客户端请求响应过程的总延迟时间。
- Span A:记录了trace-1应用在接收到客户端请求之后调用处理方法的开始和结束两个事件,它可以计算出trace-1应用用于处理客户端请求时,内部逻辑花费的时间延迟。
- Span B:记录了trace-1应用发送请求给trace-2应用、trace-2应用接收请求,trace-2应用发送响应、trace-1应用接收响应四个事件,它可以计算出trace-1调用trace-2的总体依赖时间(cr - cs),也可以计算出trace-1到trace-2的网络延迟(sr - cs),也可以计算出trace-2应用用于处理客户端请求的内部逻辑花费的时间延迟(ss - sr)。
- Span C:记录了trace-2应用在接收到trace-1的请求之后调用处理方法的开始和结束两个事件,它可以计算出trace-2应用用于处理来自trace-1的请求时,内部逻辑花费的时间延迟。
在图中展现的这个4个Span正好对应了Zipkin查看跟踪详细页面中的显示内容,它们的对应关系如下图所示:
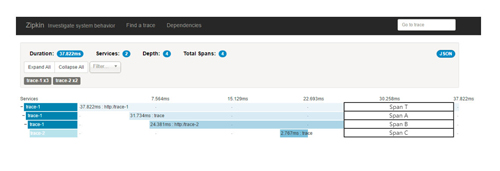
仔细的读者可能还有这样一个疑惑:我们在Zipkin服务端查询跟踪信息时(如下图所示),在查询结果页面中显示的spans是5,而点击进入跟踪明细页面时,显示的Total Spans又是4,为什么会出现span数量不一致的情况呢?
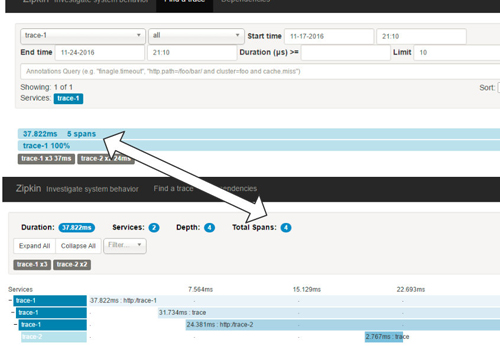
实际上这两边的span数量内容有不同的含义,在查询结果页面中的5 spans代表了总共接收的Span数量,而在详细页面中的Total Span则是对接收Span进行合并后的结果,也就是前文中我们介绍的4个不同ID的Span内容。下面我们来详细研究一下Zipkin服务端收集客户端跟踪信息的过程,看看它到底收到了哪些具体的Span内容,从而来理解Zipkin中收集到的Span总数量。
为了更直观的观察Zipkin服务端的收集过程,我们可以对之前实现的消息中间件方式收集跟踪信息的程序进行调试。通过在Zipkin服务端的消息通道监听程序中增加断点,我们就能清楚的知道客户端都发送了一些什么信息到Zipkin的服务端。在spring-cloud-sleuth-zipkin-stream依赖包中的代码并不多,我们很容易的就能找到定义消息通道监听的实现类:org.springframework.cloud.sleuth.zipkin.stream.ZipkinMessageListener。它的具体实现如下所示,其中SleuthSink.INPUT定义了监听的输入通道,默认会使用名为sleuth的主题,我们也可以通过Spring Cloud Stream的配置对其进行修改。
@MessageEndpoint
@Conditional(NotSleuthStreamClient.class)
public class ZipkinMessageListener {
final Collector collector;
@ServiceActivator(inputChannel = SleuthSink.INPUT)
public void sink(Spans input) {
List<zipkin.Span> converted = ConvertToZipkinSpanList.convert(input);
this.collector.accept(converted, Callback.NOOP);
}
...
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
从通道监听方法的定义中我们可以看到Sleuth与Zipkin在整合的时候是有两个不同的Span定义的,一个是消息通道的输入对象org.springframework.cloud.sleuth.stream.Spans,它是sleuth中定义的用于消息通道传输的Span对象,每个消息中包含的Span信息定义在org.springframework.cloud.sleuth.Span对象中,但是真正在zipkin服务端使用的并非这个Span对象,而是zipkin自己的zipkin.Span对象。所以,在消息通道监听处理方法中,对sleuth的Span做了处理,每次接收到sleuth的Span之后就将其转换成Zipkin的Span。
下面我们可以尝试在sink(Spans input)方法实现的***行代码中加入断点,并向trace-1发送一个请求,触发跟踪信息发送到RabbitMQ上。此时我们通过DEBUG模式可以发现消息通道中都接收到了两次输入,一次来自trace-1,一次来自trace-2。下面两张图分别展示了来自trace-1和trace-2输出的跟踪消息,其中trace-1的跟踪消息包含了3条span信息,trace-2的跟踪消息包含了2条span信息,所以在这个请求调用链上,一共发送了5个span信息,也就是我们在Zipkin搜索结果页面中看到的spans数量信息。
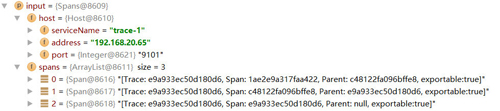

点开一个具体的Span内容,我们可以看到如下所示的结构,它记录了Sleuth中定义的Span详细信息,包括该Span的开始时间、结束时间、Span的名称、Trace ID、Span ID、Tags(对应Zipkin中的BinaryAnnotation)、Logs(对应Zipkin中的Annotation)等我们之前提到过的核心跟踪信息。
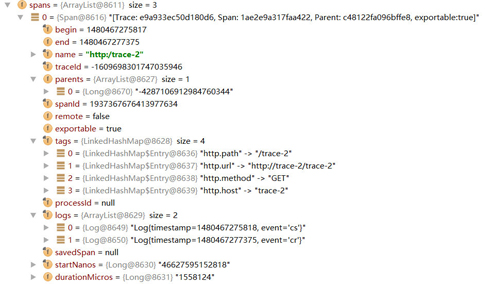
介绍到这里仔细的读者可能会有一个这样的疑惑,在明细信息中展示的Trace ID和Span ID的值为什么与列表展示的概要信息中的Trace ID和Span ID的值不一样呢?实际上,Trace ID和Span ID都是使用long类型存储的,在DEBUG模式下查看其明细时自然是long类型,也就是它的原始值,但是在查看Span对象的时候,我们看到的是通过toString()函数处理过的值,从sleuth的Span源码中我们可以看到如下定义,在输出Trace ID和Span ID时都调用了idToHex函数将long类型的值转换成了16进制的字符串值,所以在DEBUG时我们会看到两个不一样的值。
public String toString() {
return "[Trace: " + idToHex(this.traceId) + ", Span: " + idToHex(this.spanId)
+ ", Parent: " + getParentIdIfPresent() + ", exportable:" + this.exportable + "]";
}
public static String idToHex(long id) {
return Long.toHexString(id);
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
在接收到Sleuth之后我们将程序继续执行下去,可以看到经过转换后的Zipkin的Span内容,它们保存在一个名为converted的列表中,具体内容如下所示:


上图展示了转换后的Zipkin Span对象的详细内容,我们可以看到很多熟悉的名称,也就是之前我们介绍的关于zipkin中的各个基本概念,而这些基本概念的值我们也都可以在之前sleuth的原始span中找到,其中annotations和binaryAnnotations有一些特殊,在sleuth定义的span中没有使用相同的名称,而是使用了logs和tags来命名。从这里的详细信息中,我们可以直观的看到annotations和binaryAnnotations的作用,其中annotations中存储了当前Span包含的各种事件状态以及对应事件状态的时间戳,而binaryAnnotations则存储了对事件的补充信息,比如上图中存储的就是该HTTP请求的细节描述信息,除此之外,它也可以存储对调用函数的详细描述(如下图所示)。

下面我们再来详细看看通过调试消息监听程序接收到的这5个Span内容。首先,我们可以发现每个Span中都包含有3个ID信息,其中除了标识Span自身的ID以及用来标识整条链路的traceId之外,还有一个之前没有提过的parentId,它是用来标识各Span父子关系的ID(它的值来自与上一步执行单元Span的ID) ,通过parentId的定义我们可以为每个Span找到它的前置节点,从而定位每个Span在请求调用链中的确切位置。在每条调用链路中都有一个特殊的Span,它的parentId为null,这类Span我们称它为Root Span,也就是这条请求调用链的根节点。为了弄清楚这些Span之间的关系,我们可以从Root Span开始来整理出整条链路的Span内容。下表展示了我们从Root Span开始,根据各个Span的父子关系***整理出的结果:
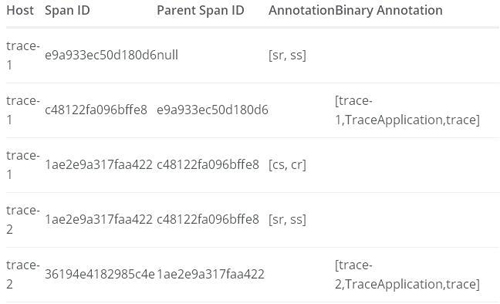
上表中的Host代表了该Span是从哪个应用发送过来的;Span ID是当前Span的唯一标识;Parent Span ID代表了上一执行单元的Span ID;Annotation代表了该Span中记录的事件(这里主要用来记录HTTP请求的四个阶段,表中内容作了省略处理,只记录了Annotation名称(sr代表服务端接收请求,ss代表服务端发送请求,cs代表客户端发送请求,cr代表客户端接收请求),省略了一些其他细节信息,比如服务名、时间戳、IP地址、端口号等信息);Binary Annotation代表了事件的补充信息(Sleuth的原始Span记录更为详细,Zipkin的Span处理后会去掉一些内容,对于有Annotation标识的信息,不再使用Binary Annotation补充,在上表中我们只记录了服务名、类名、方法名,同样省略了一些其他信息,比如:时间戳、IP地址、端口号等信息)。
通过收集到的Zipkin Span详细信息,我们很容易的可以将它们与本节开始时介绍的一次调用链路中的10个标签内容联系起来:
- Span ID = T的标签有2个,分别是序号1和10,它们分别表示这次请求的开始和结束。它们对应了上表中ID为e9a933ec50d180d6的Span,该Span的内容在标签10执行结束后,由trace-1将标签1和10合并成一个Span发送给Zipkin Server。
- Span ID = A的标签有2个,分别是序号2和9,它们分别表示了trace-1请求接收后,具体处理方法调用的开始和结束。该Span的内容在标签9执行结束后,由trace-1将标签2和9合并成一个Span发送给Zipkin Server。
- Span ID = B的标签有4个,分别是序号3、4、7、8,该Span比较特殊,它的产生跨越了两个实例,其中标签3和8是由trace-1生成的,而标签4和7则是由trace-2生成的,所以该标签会拆分成两个Span内容发送给Zipkin Server。trace-1会在标签8结束的时候将标签3和8合并成一个Span发送给Zipkin Server,而trace-2会在标签7结束的时候将标签4和7合并成一个Span发送给Zipkin Server。
- Span ID = C的标签有2个,分别是序号5和6,它们分别表示了trace-2请求接收后,具体处理方法调用的开始和结束。该Span的内容在标签6执行结束后,由trace-2将标签2和9合并成一个Span发送给Zipkin Server。
所以,根据上面的分析,Zipkin总共会收到5个Span:一个Span T,一个Span A,两个Span B,一个Span C。结合之前请求链路的标签图和这里的Span记录,我们可以总结出如下图所示的Span收集过程,读者可以参照此图来理解Span收集过程的处理逻辑以及各个Span之间的关系。
虽然,Zipkin服务端接收到了5个Span,但就如前文中分析的那样,其中有两个Span ID=B的标签,由于它们来自于同一个HTTP请求(trace-1对trace-2的服务调用),概念上它们属于同一个工作单元,因此Zipkin服务端在前端展现分析详情时会将这两个Span合并了来显示,而合并后的Span数量就是在请求链路详情页面中Total Spans的数量。
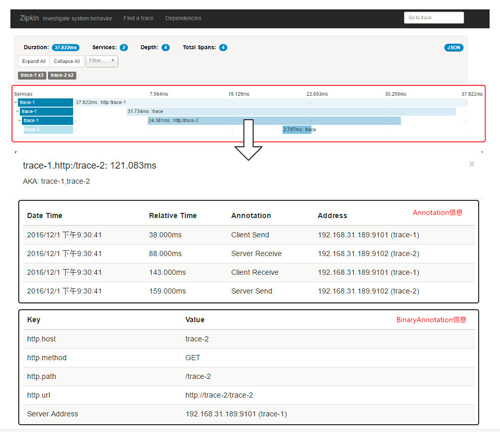
下图是本章示例的一个请求链路详情页面,在页面中显示了各个Span的延迟统计,其中第三条Span信息就是trace-1对trace-2的HTTP请求调用,通过点击它可以查看该Span的详细信息,点击后会以模态框的方式弹出Span详细信息(如图下半部分),在弹出框中详细展示了Span的Annotation和BinaryAnnotation信息,在Annotation区域我们可以看到它同时包含了trace-1和trace-2发送的Span信息,而在BinaryAnnotation区域则展示了该HTTP请求的详细信息。
完整示例:
读者可以根据喜好选择下面的两个仓库中查看trace-1和trace-2两个项目:
Github:https://github.com/dyc87112/SpringCloud-Learning/
Gitee:https://gitee.com/didispace/SpringCloud-Learning/
【本文为51CTO专栏作者“翟永超”的原创稿件,转载请通过51CTO联系作者获取授权】