InfluxDB写入总体框架
InfluxDB提供了多种接口协议供外部应用写入,比如可以使用collected采集数据上传,可以使用opentsdb作为输入,也可以使用http协议以及udp协议批量写入数据。批量数据进入到InfluxDB之后总体会经过三个步骤的处理,如下图所示:
1. 批量时序数据shard路由:InfluxDB首先会将这些数据根据shard的不同分成不同的分组,每个分组的时序数据会发送到对应的shard。每个shard相当于HBase中region的概念,是InfluxDB中处理用户读写请求的单机引擎。
2. 倒排索引引擎构建倒排索引:InfluxDB中shard由两个LSM引擎构成 – 倒排索引引擎和TSM引擎。时序数据首先会经过倒排索引引擎构建倒排索引,倒排索引用来实现InfluxDB的多维查询。
3. SM引擎持久化时序数据:倒排索引构建成功之后时序数据会进入TSM Engine处理。TMS Engine处理流程和通用LSM Engine基本一样,先将写入请求追加写入WAL日志,再写入cache,一旦满足特定条件会将cache中的时序数据执行flush操作落盘形成TSM File。
批量时序数据Shard路由
通常来说时序数据都会以批量的形式写入数据库,很少会像关系型数据库那样一条一条写入,这对于追求高吞吐的时序系统来说至关重要。批量数据写入InfluxDB之后做的***件事情是分组,将时序数据点按照所属shard划分为多组(称为Shard Map),每组时序数据点将会发送给对应的shard引擎并发处理。
这里我们简单回顾下InfluxDB的Sharding策略(详见文章《时序数据库技术体系 – 初识InfluxDB》中Sharding策略一节)。InfluxDB虽说是单机数据库,但是每个表依然会被分为多个shard。简单来说,InfluxDB中sharding属于两层sharding:首先按照时间进行Range Sharding,即按时间分片,比如7天一个分片的话,最近7天的数据会分到一个shard,一周前到两周前的数据会被分到上一个shard,以此类推;在时间分片的基础上还可以再执行Hash Sharding,按照SeriesKey执行Hash(保证同一个SeriesKey对应的所有数据都落到同一个shard),再将数据分散到指定的多个shard中。
当然,经过笔者深进一步了解,发现单机InfluxDB只有***层sharding,即只有根据时间进行Range Sharding,并没有执行Hash Sharding。Hash Sharding只会在分布式InfluxDB中才会用到。
倒排索引引擎构建倒排索引
InfluxDB中倒排索引引擎使用LSM引擎构建,上篇文章《时序数据库技术体系 – InfluxDB 多维查询之倒排索引》其实已经对引擎的工作原理进行了深入的介绍。这里重点将整个流程做一个串联梳理,其中细节部分不会展开来讲,有兴趣的话可以参考上一篇文章。
这里首先思考一个问题:为什么InfluxDB倒排索引需要构建成LSM引擎?其实很简单,LSM引擎天生对写友好,写多读少的系统***选择就是LSM引擎,所以大数据时代的各种数据存储系统就是LSM引擎的天下,HBase、Kudu、Druid、TiKV这些系统无一不是这样。InfluxDB作为一个时序数据库更是写多读少的典型,无论倒排索引引擎还是时序数据处理引擎选用LSM引擎更是无可厚非。
既然是LSM引擎,工作机制必然是这样的:首先将数据追加写入WAL再写入Cache就可以返回给用户写入成功,WAL可以保证即使发生异常宕机也可以恢复出来Cache中丢失的数据。一旦满足特定条件系统会将Cache中的时序数据执行flush操作落盘形成文件。文件数量超过一定阈值系统会将这些文件合并形成一个大文件。那具体到倒排索引引擎整个流程是什么样的,简单来看一下:
1. WAL追加写入:Inverted Index WAL格式很简单,由一个一个LogEntry构成,如下图所示:
每个LogEntry由Flag、Measurement、一系列Key\Value以及Checksum组成。其中Flag表示更新类型,包括写入、删除等,Measurement表示数据表,Key\Value表示写入的Tag Set以及Checksum,其中Checksum用于根据WAL回放数据时验证LogEntry的完整性。注意,LogEntry中并没有时序数据列,只有维度列(Tag Set)。
2. Inverted Index在内存中构建
(1)拼SeriesKey: 时序数据写入到系统之后先将measurement和所有的维度值拼成一个seriesKey;
(2)确认SeriesKey是否已经构建过索引:在文件中确认该seriesKey是否已经存在,如果已经存在就忽略,不需要再将其加入到内存倒排索引。那问题转化为如何在文件中查找某个seriesKey是否已经存在?这就是Series Block中Bloom Filter的核心作用,首先使用Bloom Filter进行判断,如果不存在,肯定不存在。如果存在,不一定存在,需要进一步判断。再进一步使用B+树以及HashIndex进一步查找判断;
(3)如果seriesKey在文件中不存在,需要将其写入内存。倒排索引内存结构主要包含两个Map:<measurement, List<tagKey>> 和 <tagKey, <tagValue, List<SeriesKey>>>,前者表示时序表与对应维度集合的映射,即这个表中有多少维度列。后者表示每个维度列都有哪些可枚举的值,以及这些值都对应哪些SeriesKey。InfluxDB中SeriesKey就是一把钥匙,只有拿到这把钥匙才能找到这个SeriesKey对应的数据。而倒排索引就是根据一些线索去找这把钥匙。
3. Inverted Index Cache Flush流程
(1)触发时机:当Inverted Index WAL日志的大小超过阈值(默认5M),就会执行flush操作将缓存中的两个Map写成文件;
(2)基本流程:
- 缓存Map排序:<measurement, List<tagKey>>以及<tagKey, <tagValue, List<SeriesKey>>都需要经过排序处理,排序的意义在于有序数据可以结合Hash Index实现范围查询,另外Series Block中B+树的构建也需要SeriesKey排序;
- 构建并持久化Series Block:在排序的基础上首先持久化<tagKey, tagValue, List<SeriesKey>>结构中所有的SeriesKey,也就是先构建Series Block。依次持久化SeriesKey到SeriesKeyChunk,当Chunk满了之后,根据Chunk中最小的SeriesKey构建B+树中的Index Entry节点。当然,Hash Index以及Bloom Filter是需要实时构建的。需要注意的是,Series Block在构建的同时需要记录下SeriesKey与该Key在文件中偏移量的对应关系,即<SeriesKey, SeriesKeyOffset>,这一点至关重要;
- 内存中将SeriesKey映射为SeriesId:将<tagKey, <tagValue, List<SeriesKey>>结构中所有的SeriesKey由上一步中得到的<SeriesKey, SeriesKeyOffset >中的SeriesKeyOffset代替。形成新的结构:<tagKey, <tagValue, List<SeriesKeyOffset>>,即<tagKey, <tagValue, List<SeriesKeyId>>>,其中SeriesKeyId就是SeriesKeyOffset;
- 构建并持久化Tag Block:在新结构<tagKey, <tagValue, List<SeriesKeyId>>>的基础上首先持久化tagValue,将同一个tagKey下的所有tagValue持久化在一起并生成对应Hash Index写入文件,接着持久化下一个tagKey的所有tagValue。所有tagValue都持久话完成之后再依次持久化所有的tagKey,形成Tag Block;
- 构建并持久化Measurement Block:***持久化measurement形成Measurement Block。
时序数据写入流程
时序数据的维度信息经过倒排索引引擎构建完成之后,接着就需要将数据写入系统。和倒排索引引擎一样,数据写入引擎也是一个LSM引擎,基本流程也是先写WAL,再写Cache,***满足一定阈值条件之后将Cache中的数据flush到文件。
1. WAL追加写入:时间线数据数据会经过两重处理,首先格式化为WriteWALEntry对象,该对象字段元素如下图所示。然后经过snappy压缩后写入WAL并持久话到文件。

2. 时序数据写入内存结构
(1)时序数据点格式化:将所有时间序列数据点按时间线组织形成一个Map:<SeriesKey+FieldKey, List<Value>>,即将相同Key(SeriesKey+FieldKey)的时序数据集中放在一个List中;
(2)时序数据点写入Cache:InfluxDB中Cache是一个crude hash ring,这个ring由256个partition构成,每个partition负责存储一部分时序数据Key对应的值。就相当于数据写入Cache的时候又根据Key Hash了一次,根据Hash结果映射到不同的partition。为什么要这么处理?个人认为有点像Java中ConcurrentHashMap的思路,将一个大HashMap切分成多个小HashMap,每个HashMap内部在写的时候需要加锁。这样处理可以减小锁粒度,提高写性能。
3. Data Cache Flush流程(参考engine.compactCache)
(1)触发时机:Cache执行flush操作有两个基本触发条件,其一是当cache大小超过一定阈值,可以通过参数’cache-snapshot-memory-size’配置,默认是25M大小;其二是超过一定时间阈值没有时序数据写入WAL也会触发flush,默认时间阈值为10分钟,可以通过参数’cache-snapshot-write-cold-duration’配置;
(2)基本流程:在了解了TSM文件的基本结构之后,我们再简单看看时序数据是如何从内存中的Map持久化成TSM文件的,整个过程可以表述为:
- 内存中构建Series Data Block:顺序遍历内存Map中的时序数据,分别对时序数据的时间列和数值列进行相应的编码,按照Series Data Block的格式进行组织,当Block大小超过一定阈值就构建成功。并记录这个Block内时间列的最小时间MinTime以及***时间MaxTime。
- 将构建好的Series Data Block写入文件:使用输出流将内存中数据输出到文件,并返回该Block在文件中的偏移量Offset以及总大小Size。
- 构建文件级别B+索引:在内存中为该Series Data Block构建一个索引节点Index Entry,使用数据Block在文件中的偏移量Offset、总大小Size以及MinTime、MaxTime构建一个Index Entry对象,写入到内存Series Index Block对象。
这样,每构建一个Series Data Block并写入文件之后都会在内存中顺序构建一个Index Entry,写入内存Series Index Block对象。一旦一个Key对应的所有时序数据都持久化完成,一个Series Index Block就构建完成,构建完成之后填充Index Block Meta信息。接着新建一个新的Series Index Block开始构建下一个Key对应的数据索引信息。
InfluxDB数据删除操作(DropMeasurement,DropTagKey)
一般LSM引擎处理删除通常都采用Tag标记的方式,即删除操作和写入操作流程基本一致,只是数据上会多一个Tag标记 – deleted,表示该值已经被deleted。这种处理方案可以最小化删除代价,但万物有得必有失,减小了写入代价必然会增加读取代价,Tag标签方案在读取的时候需要对标记有deleted的数值进行特殊处理,这个代价还是很大的。HBase中删除操作就是采用Tag标记方案。
InfluxDB比较奇葩,对于删除操作处理的比较异类,通常InfluxDB不会删除一条记录,而是会删除某段时间内或者某个维度下的所有记录,甚至一张表的所有记录,这和通常的数据库有所不同。比如:
DROP SERIES FROM h2o_feet WHERE location = ‘santa_monica' DELETE FROM "cpu" DELETE FROM "cpu" WHERE time < '2000-01-01T00:00:00Z' DELETE WHERE time < '2000-01-01T00:00:00Z'
上文我们知道InfluxDB中一个shard有两个LSM引擎,一个是倒排索引引擎(存储维度列到SeriesKey的映射关系,方便多维查找),一个是TSM Engine,用来存储实际的时序数据。如果是删除一条记录,通常只需要TSM Engine执行删除就可以,倒排索引引擎是不需要执行删除的。而如果是Drop Measurement这样的操作,那么两个LSM引擎都需要执行相应的删除。问题是,这两个引擎的删除策略完全不同,TSM Engine采用了一种同步删除策略,Inverted Index Engine采用了标记删除策略。如下图所示:
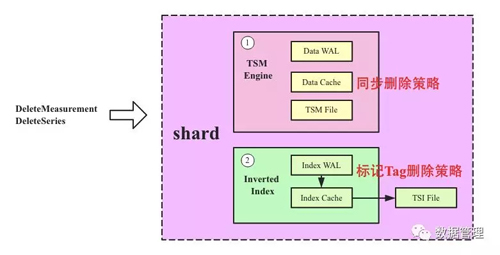
1. TSM Engine同步删除策略,整个删除流程可以分为如下四步:
(1)删除所有TSM File中满足条件的series,系统会遍历当前shard中所有TSM File,检查该File中是否存在满足删除条件的File,如果有会执行如下两个操作:
- TSM File Index相关处理:在内存中删除满足条件的Index Entry,通常删除会带有Time Range以及Key Range,而且TSM File Index会在引擎启动之后加载到内存。因此删除操作会将满足条件的Index Entry从内存中删除。
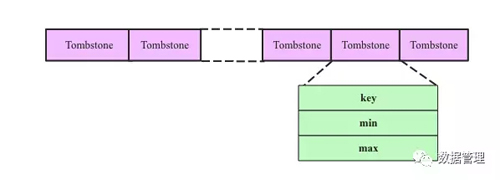
- 生成tombstoner文件:tombstoner文件会记录当前TSM File中所有被删除的时序数据,时序数据用[key, min, max]三个字段表示,其中key即SeriesKey+FieldKey,[min, max]表示要删除的时间段。如下图所示:
(2)删除Cache中满足条件的series;
(3)在WAL中生成一条删除series的记录并持久化到硬盘。
2. Inverted Index Engine 标记Tag删除策略,标记Tag删除非常简单,和一次写入流程基本相同:
(1)在WAL中生成一条flag为deleted的LogEntry并持久化到硬盘;
(2)将要删除的维度信息写入Cache,需要标记deleted(设置type=deleted);
(3)当WAL大小超过阈值之后标记为deleted的维度信息会随Cache Flush到倒排索引文件;
(4)和HBase一样,Inverted Index Engine中索引信息真正被删除发生在compact阶段。
总结
InfluxDB因为其特有的双LSM引擎而显得内部结构更加复杂,写入流程相比其他数据库来说更加繁琐。但只要理解了它的数据文件内部组织格式以及倒排索引文件内部组织格式,相信对于整体的把握也并不是很难。