先说结论,我支持将逻辑写在 Java 等应用系统中。
背景:
今天只讨论一种应用模式,就是最普遍的,前端实时调用后端web服务,服务端经过DB的增删改查作出响应的应用。至于离线数据分析,在线规则引擎模板执行,流式计算等不在本次讨论范畴。
重SQL开发的场景
先看一个例子吧。用经典的 Controller Service DAO 开发模式描述。
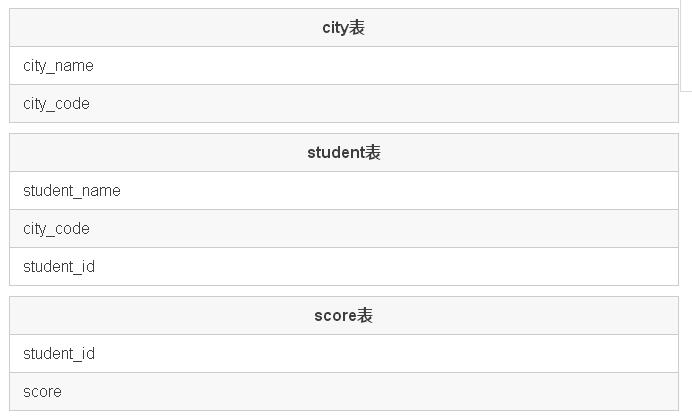
需求:
查询出每个学生所在的城市名以及分数展示到前端。
重SQL模式
class Controller{
Service service;
Map<String,String> get(Map<String,Object> param){
return service.get(param);
}
}
class Service{
DAO dao;
Map<String,String> get(Map<String,Object> param){
return dao.get(param);
}
}
class DAO{
SQLTemplate template;
Map<String,String> get(Map<String,Object> param){
String sql = "select city_name,student_name,score from student,score,city where city.city_code=student.city_code and score.student_id=student.student_id" ;
return template.execute(sql,param);
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
重Java模式
class View{
String studentName;
String cityName;
String score;
}
class Requent{
}
class Controller{
Service service;
List<View> get(Requent request){
return service.get(param);
}
}
class Service{
StudentDAO studentDAO;
ScoreDAO scoreDAO;
CityDAO cityDAO;
List<View> get(Requent param){
Student studentRequest = new Student();
//查询学生
List<Student> students = studentDAO.select(studentRequest);
List<View> result = new ArrayList(students.size());
for(Student student : students){
View view = new View();
view.setStudentName(student.getStudentName());
//拼接城市名
City cityRequest = new City();
cityRequest.setStudentId(student.getStudentId());
City city = cityDAO.select(cityRequest);
view.setCityName(city);
//拼接分数
Score scoreRequest = new Score();
scoreRequest.setStudentId(student.getStudentId());
Score score = scoreDAO.select(scoreRequest);
view.setScode(score.getScore());
result.add(view);
}
return result;
}
}
class StudentDAO{
SQLTemplate template;
Student select(Student param){
String sql = "select * from Student where param = ...";
template.select(sql,param);
}
}
class ScoreDAO{
SQLTemplate template;
Score select(Score param){
String sql = "select * from Score where param = ...";
template.select(sql,param);
}
}
class CityDAO{
SQLTemplate template;
City select(City param){
String sql = "select * from City where param = ...";
template.select(sql,param);
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
可以看到,使用重SQL的模式来进行开发确实很快很快,只需要把SQL开发出来基本就完事了,但是看着用重 Java 的模式开发,需要写一堆的代码,这么看来好像是 SQL 胜利一筹。
好,PD突然说了,我要把城市名为 “大蕉” 的,分数乘于2展示出来。握草,这个怎么搞??
重SQL模式
class DAO{
SQLTemplate template;
Map<String,String> get(Map<String,Object> param){
String sql = "select city_name,student_name,CASE WHEN city.city_name='大蕉' THEN 2*score.score ELSE score END score from student,score,city where city.city_code=student.city_code and score.student_id=student.student_id " ;
return template.execute(sql,param);
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
好了。。这个SQL已经变得很复杂了基本没法看了。。
重 Java 模式
Service.class
//拼接分数
Score scoreRequest = new Score();
scoreRequest.setStudentId(student.getStudentId());
Score score = scoreDAO.select(scoreRequest);
if("大蕉".equals(city.getCityName()){
view.setScode(score.getScore() * 2);
}else{
view.setScode(score.getScore());
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
咦好像改动也不多嘛。
这时候PD又来了我要把城市名为 “大蕉” ,并且城市Code小于10086的,分数乘于2展示出来。握草,完蛋了,之前全是SQL,这个需求要怎么搞??继续叠加上去继续 CASE WHEN?
还没想清楚呢,突然 DBA 电话飞过来了,兄dei你的SQL太慢了,现在把整个库拖垮了,你是不是没有加索引?
我:索引加了啊。。。难道是没走到?那是先解决慢SQL还是先开发需求呢?拆库是不可能了,逻辑这么死鬼复杂拆库完全没法跑啊,加CPU加内存啊 DBA大佬!!!
[DBA日报] 慢SQL 180+,已解决10。
又上了一个版本
[DBA日报] 慢SQL 200+,已解决15。
又上了一个版本
[DBA日报] 慢SQL 250+,已解决30。
慢慢的,开发和运营和DBA每天都疲劳于监控这些SQL。。。。
前言
观察了一下,传统企业以及绝大部分转型中的企业的 Java 应用中,很神奇的是,他们的开发人员包括我自己以前,大家都非常非常希望使用一个 SQL 来完成所有的逻辑的编写,非常多企业更是把数据库的存储过程和数据库自定义函数来完成。
这些关于逻辑应该写在哪里的争论从来没有停止过,不仅仅发生在后端和数据库端,连前后端都经常会发生这种争论,现在只讨论后端和数据库端的纠结。
我将从这五个方面分别对比一下两种模式的异同。
- 出现场景
- 开发效率
- 缺陷排查
- 架构升级
- 系统维护
出现场景
SQL
我们绝大多数的历史代码都是用存储过程来实现的啊,如果有新需求不往上面做的话,很难兼容原来的逻辑啊啊。
前面的人呢是这样写的,我来了看大家都这样写就这样写了。
Java
新应用嘛,我想怎么样写就怎样写。
监控和埋点写起来简单吖,排查问题可方便了。
前面的人呢是这样写的,我来了看大家都这样写就这样写了。
开发效率
SQL
这样写起来很快啊,而且写 Java 代码多难受啊,写 SQL 我自己在数据库开发环境跑一下结果正确我就直接丢到代码中提交了,多爽啊。
老实说,这样子确实会提高开发的效率,因为不用写那么多查库聚合的操作,一切都在 SQL 中搞定了。另一方面来看,这确实会让 Java 代码看起来很鸡肋,好像只是把数据从 web 层到数据层的一个管道而已,一切 if else 能写在 SQL 中的都写在 SQL 中了。
但是新需求来或者需求变更的时候,我经常要重新写SQL,如果变动不多我可能要改动到原来的 SQL,但是我又不敢改,所以只好 copy 重新写一个,改 SQL 的风险好大,一报错又要重启好难受。
Java
一次要写N个类,有点烦。
新需求来或者需求变更的时候,如果逻辑比较复杂,我直接抽成方法或者改成一些设计模式,维护起来效率还是可以接受的。
缺陷排查
SQL
开发排查问题的时候,除了看日志,直接把SQL和参数丢到 PL/SQL 或者 其他工具里跑一下,基本就能知道数据问题出现在哪了。测试同学在进行测试的时候,如果发现有不对的东西,直接跟开发同学一样的思路,把SQL 跑一下,问题基本就定位得七七八八了。
但是呢,一旦遇到跑 SQL 无法一眼看出问题的 bug 或者 SQL 实在是太长太长了的的时候,就蒙圈了。我曾经就维护了一个几千行的存储过程,一旦发生问题,排查问题的过程巨艰难。但是呢直接用一个数据库一个功能搞定所有功能未尝不是一件很爽的事情,因为关系型数据库实在是实在是太太太稳定了,一次编写***运行。
Java
看日志看监控。
根据报错的代码位置 check 一下代码逻辑。
一些入参分支肉眼 check 不出来,只能远程 debug 慢慢看数据流向。
测试的同学基本无法帮忙 check 缺陷,只能靠程序的表现来判断。
架构升级
SQL
SQL 慢没关系,它稳定啊,慢就把机器垂直扩展一下好啦,加cpu,加内存,换SSD,加加加绝对可以解决事情的。
SQL 有各种索引和优化策略,说不定跑起来比我们自己写逻辑还快呢。
加加加,加内存加cpu垂直升级。也没有其他招数了,除了前置缓存,但是如果查询都很个性化SQL很复杂,前置缓存也基本没啥乱用。。。
如果你的逻辑全部写在 SQL 中,那完蛋了,你这个表基本就没法分表了,因为你的业务逻辑跟数据库的数据完整性是强耦合的,需要一切数据基本都在一个数据库中,这是一件很难受很难受的事情,不信你去问问那些所有业务逻辑全写在 SQL 中的小伙。
数据库中非常复杂的表关联会极大程度拖慢数据库处理每条 SQL 的平均时间,极大程度拖慢数据库 RT,降低了数据库的 RT ,如果逻辑都写在 SQL 中,那么只能进行垂直升级。因为一旦进行水平扩展,那么多机器的非常复杂的分布式表关联,RT 基本不是一个高并发的业务应用的能容忍的。
Java
如果是数据库瓶颈,加数据库机器,分库分表一下,应用层基本不用改,在DAO层进行路由一下。
如果是服务器cpu瓶颈,多加几台机器就好了。
如果还有瓶颈,增加一下查询缓存。
在应用快速发展的过程中一般都会分库分表的拆分或者自动水平扩展,这时候其实只需要数据库层面做好自己的数据迁移和同步就好了,对于业务层来说是完全无感知的。即使业务非常非常复杂,需要拆应用,其实也非常简单,只需要把对应的 DAO 层的操作拆分出去,换成 RPC 或者其他方式的调用就好了。
系统维护
SQL
旧SQL完全不敢动,来一个需求加一个 SQL。
慢SQL日益增加,应对疲乏。
Java
SQL写完一次基本不用动,来一个需求加一个方法聚合一下数据操作即可。
应用维护比较简单,只要监控做好了,定位到问题基本都能很快解决。
逻辑越来越复杂,没有好的开发框架的话,代码维护起来也是挺要命,因为完全不知道跑哪个分支去了。但是现在已经有很多优秀的开源框架来更好地维护代码了,比如 Spring 的全家桶。
怎么破
旧的重 SQL 逻辑暂时不要动,新的逻辑都基于 Java 模式开发,先保证慢 SQL 不增加,旧的 SQL 稳定运行,毕竟业务稳定是***要素。
如果业务初期需要非常非常快速开发,那么使用重 SQL 模式也是可以理解的,但是还是要抽时间重构成 Java 模式。
结论
我支持将逻辑写在 Java 等应用系统中。其实原因在上面基本描述完了,***就是复杂 SQL 的表关联其实跟个人的能力有非常大的关系,如果一个 SQL 写得不好,那是极慢极慢的非常容易把整个数据库拖慢的。第二就是维护这些 SQL 也是一件很难受的事情,因为你完全不知道这个 SQL 背后的数据流转是怎样的,你只能根据自己的猜测去查看 SQL 中的 bug,Java 应用好歹还能 debug 一下还有打点看看数据不是?如果逻辑写在 Java 中那么其实你的 DAO 层只需要编写一次,但是可以***使用,基本不会在这一层浪费很多的时间(用过 ibatis 的都知道改了 SQL 需要重启应用吧?)。第三就是逻辑都写在 SQL ,中对于分库分表和应用拆分来说是一件非常难受的事情,真的难受。
昨天写的被吐槽了,回炉重造了,重新看看。