最近在我的项目中自己搭了一套小型的“高可用”Redis 服务,在此做一下总结和思考。
基于内存的 Redis 应该是目前各种 Web 开发业务中最为常用的 key-value 数据库了。
我们经常在业务中用其存储用户登陆态(Session 存储),加速一些热数据的查询(相比较 MySQL 而言,速度有数量级的提升),做简单的消息队列(LPUSH 和 BRPOP)、订阅发布(PUB/SUB)系统等等。
规模比较大的互联网公司,一般都会有专门的团队,将 Redis 存储以基础服务的形式提供给各个业务调用。
不过任何一个基础服务的提供方,都会被调用方问起的一个问题是:你的服务是否具有高可用性?***不要因为你的服务经常出问题,导致我这边的业务跟着遭殃。
最近在我的项目中自己搭了一套小型的“高可用”Redis 服务,在此做一下自己的总结和思考。
首先我们要定义一下对于 Redis 服务来说怎样才算是高可用,即在各种出现异常的情况下,依然可以正常提供服务;或者宽松一些,出现异常的情况下,只经过很短暂的时间即可恢复正常服务。
所谓异常,应该至少包含了以下三种可能性:
某个节点服务器的某个进程突然 down 掉,例如某开发手残,把一台服务器的 redis-server 进程 kill 了。
某台节点服务器 down 掉,相当于这个节点上所有进程都停了,例如某运维手残,把一个服务器的电源拔了;例如一些老旧机器出现硬件故障。
任意两个节点服务器之间的通信中断了,例如某临时工手残,把用于两个机房通信的光缆挖断了。
其实以上任意一种异常都是小概率事件,而做到高可用性的基本指导思想就是:多个小概率事件同时发生的概率可以忽略不计,只要我们设计的系统可以容忍短时间内的单点故障,即可实现高可用性。
对于搭建高可用 Redis 服务,网上已有了很多方案,例如 Keepalived、Codis、Twemproxy、Redis Sentinel。
其中 Codis 和 Twemproxy 主要是用于大规模的 Redis 集群中,也是在 Redis 官方发布 Redis Sentinel 之前 Twitter 和豌豆荚提供的开源解决方案。
我的业务中数据量并不大,所以搞集群服务反而是浪费机器了。最终在 Keepalived 和 Redis Sentinel 之间做了个选择,选择了官方的解决方案 Redis Sentinel。
Redis Sentinel 可以理解为一个监控 Redis Server 服务是否正常的进程,并且一旦检测到不正常,可以自动地将备份(slave)Redis Server 启用,使得外部用户对 Redis 服务内部出现的异常无感知。
下面我们按照由简至繁的步骤,搭建一个最小型的高可用的 Redis 服务。
方案1:单机版 Redis Server,无 Sentinel
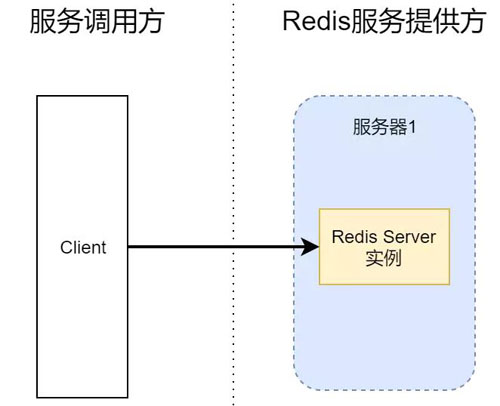
一般情况下,我们搭的个人网站或者平时做开发时,会起一个单实例的 Redis Server。
调用方直接连接 Redis 服务即可,甚至 Client 和 Redis 本身就处于同一台服务器上。
这种搭配仅适合个人学习娱乐,毕竟这种配置总会有单点故障的问题无法解决。
一旦 Redis 服务进程挂了,或者服务器 1 停机了,那么服务就不可用了。并且如果没有配置 Redis 数据持久化的话,Redis 内部已经存储的数据也会丢失。
方案2:主从同步 Redis Server,单实例 Sentinel
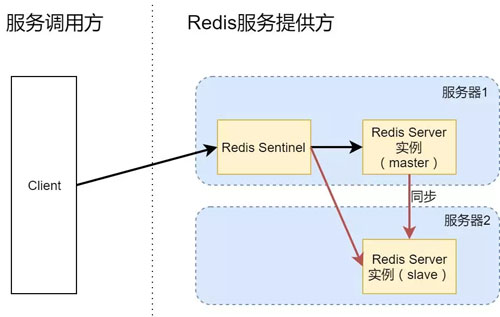
为了实现高可用,解决方案 1 中所述的单点故障问题,我们必须增加一个备份服务,即在两台服务器上分别启动一个 Redis Server 进程,一般情况下由 master 提供服务,slave 只负责同步和备份。
与此同时,在额外启动一个 Sentinel 进程,监控两个 Redis Server 实例的可用性,以便在 master 挂掉的时候,及时把 slave 提升到 master 的角色继续提供服务,这样就实现了 Redis Server 的高可用。
这基于一个高可用服务设计的依据,即单点故障本身就是个小概率事件,而多个单点同时故障(即 master 和 slave 同时挂掉),可以认为是(基本)不可能发生的事件。
对于 Redis 服务的调用方来说,现在要连接的是 Redis Sentinel 服务,而不是 Redis Server 了。
常见的调用过程是,client 先连接 Redis Sentinel 并询问目前 Redis Server 中哪个服务是 master,哪些是 slave,然后再去连接相应的 Redis Server 进行操作。
当然目前的第三方库一般都已经实现了这一调用过程,不再需要我们手动去实现(例如 Nodejs 的 ioredis,PHP 的 predis,Golang 的 go-redis/redis,Java 的 jedis 等)。
然而,我们实现了 Redis Server 服务的主从切换之后,又引入了一个新的问题,即 Redis Sentinel 本身也是个单点服务,一旦 Sentinel 进程挂了,那么客户端就没办法链接 Sentinel 了。所以说,方案 2 的配置无法实现高可用性。
方案3:主从同步 Redis Server,双实例 Sentinel
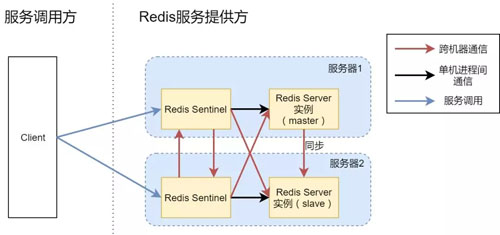
为了解决方案 2 的问题,我们把 Redis Sentinel 进程也额外启动一份,两个 Sentinel 进程同时为客户端提供服务发现的功能。
对于客户端来说,它可以连接任何一个 Redis Sentinel 服务,来获取当前 Redis Server 实例的基本信息。
通常情况下,我们会在 Client 端配置多个 Redis Sentinel 的链接地址,Client 一旦发现某个地址连接不上,会去试图连接其他的 Sentinel 实例。
这当然也不需要我们手动实现,各个开发语言中比较热门的 Redis 连接库都帮我们实现了这个功能。
我们预期是:即使其中一个 Redis Sentinel 挂掉了,还有另外一个 Sentinel 可以提供服务。
然而,愿景是美好的,现实却是很残酷的。如此架构下,依然无法实现 Redis 服务的高可用。
方案 3 示意图中,红线部分是两台服务器之间的通信,而我们所设想的异常场景(异常2)是:某台服务器整体宕机,不妨假设服务器 1 停机,此时,只剩下服务器 2 上面的 Redis Sentinel 和 slave Redis Server 进程。
这时,Sentinel 其实是不会将仅剩的 slave 切换成 master 继续服务的,也就导致 Redis 服务不可用,因为 Redis 的设定是只有当超过 50% 的 Sentinel 进程可以连通并投票选取新的 master 时,才会真正发生主从切换。
本例中两个 Sentinel 只有一个可以连通,等于 50% 并不在可以主从切换的场景中。
你可能会问,为什么 Redis 要有这个 50% 的设定?假设我们允许小于等于 50% 的 Sentinel 连通的场景下也可以进行主从切换呢?
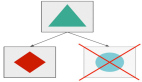
试想一下异常 3,即服务器 1 和服务器 2 之间的网络中断,但是服务器本身是可以运行的,如下图所示:
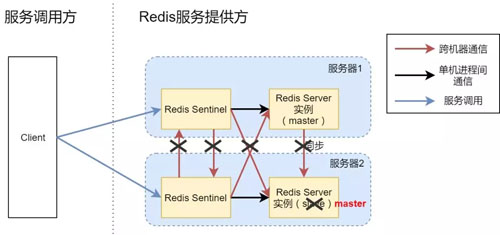
实际上对于服务器 2 来说,服务器 1 直接宕机和服务器 1 网络连不通是一样的效果,都是突然就无法进行任何通信了。
假设网络中断时我们允许服务器 2 的 Sentinel 把 slave 切换为 master,结果就是你现在拥有了两个可以对外提供服务的 Redis Server。
Client 做任何的增删改操作,有可能落在服务器 1 的 Redis 上,也有可能落在服务器 2 的 Redis 上(取决于 Client 到底连通的是哪个 Sentinel),造成数据混乱。
即使后面服务器1和服务器2之间的网络又恢复了,我们也无法把数据统一了(两份不一样的数据,到底该信任谁呢?),数据一致性完全被破坏。
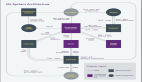
方案4:主从同步 Redis Server,三实例 Sentinel
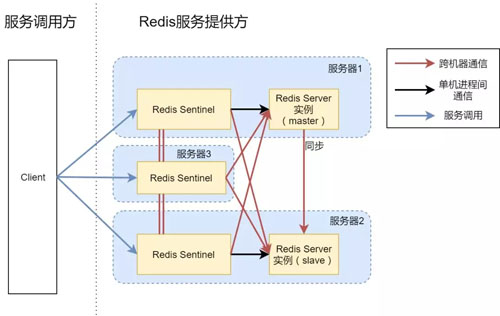
鉴于方案 3 并没有办法做到高可用,我们最终的版本就是上图所示的方案 4 了,实际上这就是我们最终搭建的架构。
我们引入了服务器 3,并且在 3 上面又搭建起一个 Redis Sentinel 进程,现在由三个 Sentinel 进程来管理两个 Redis Server 实例。
这种场景下,不管是单一进程故障、还是单个机器故障、还是某两个机器网络通信故障,都可以继续对外提供 Redis 服务。
实际上,如果你的机器比较空闲,当然也可以把服务器 3 上面也开启一个 Redis Server,形成 1 master + 2 slave 的架构。
每个数据都有两个备份,可用性会提升一些。当然也并不是 slave 越多越好,毕竟主从同步也是需要时间成本的。
在方案 4 中,一旦服务器 1 和其他服务器的通信完全中断,那么服务器 2 和 3 会将 slave 切换为 master。
对于客户端来说,在这么一瞬间会有 2 个 master 提供服务,并且一旦网络恢复了,那么所有在中断期间落在服务器 1 上的新数据都会丢失。
如果想要部分解决这个问题,可以配置 Redis Server 进程,让其在检测到自己网络有问题的时候,立即停止服务,避免在网络故障期间还有新数据进来(可以参考 Redis 的 min-slaves-to-write 和 min-slaves-max-lag 这两个配置项)。
至此,我们就用 3 台机器搭建了一个高可用的 Redis 服务。其实网上还有更加节省机器的办法,就是把一个 Sentinel 进程放在 Client 机器上,而不是服务提供方的机器上。
只不过在公司里面,一般服务的提供方和调用方并不来自同一个团队。两个团队共同操作同一个机器,很容易因为沟通问题导致一些误操作,所以出于这种人为因素的考虑,我们还是采用了方案 4 的架构。
并且由于服务器 3 上面只跑了一个 Sentinel 进程,对服务器资源消耗并不多,还可以用服务器 3 来跑一些其他的服务。
易用性:像使用单机版 Redis 一样使用 Redis Sentinel
作为服务的提供方,我们总是会讲到用户体验问题。在上述方案当中始终有一个让 Client 端用的不是那么舒服的地方。
对于单机版 Redis,Client 端直接连接 Redis Server,我们只需要给一个 ip 和 port,Client 就可以使用我们的服务了。
而改造成 Sentinel 模式之后,Client 不得不采用一些支持 Sentinel 模式的外部依赖包,并且还要修改自己的 Redis 连接配置,这对于“矫情”的用户来讲显然是不能接收的。
有没有办法还是像在使用单机版的 Redis 那样,只给 Client 一个固定的 ip 和 port 就可以提供服务呢?
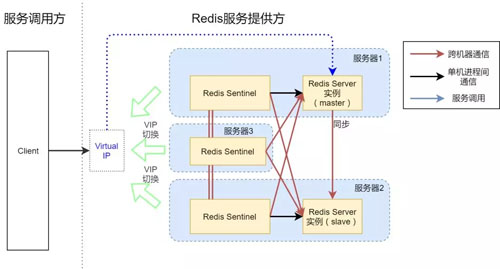
答案当然是肯定的。这可能就要引入虚拟 IP(Virtual IP,VIP),如上图所示。
我们可以把虚拟 IP 指向 Redis Server master 所在的服务器,在发生 Redis 主从切换的时候,会触发一个回调脚本,回调脚本中将 VIP 切换至 slave 所在的服务器。
这样对于 Client 端来说,他仿佛在使用的依然是一个单机版的高可用 Redis 服务。
结语
搭建任何一个服务,做到“能用”其实是非常简单的,就像我们运行一个单机版的 Redis。
不过一旦要做到“高可用”,事情就会变得复杂起来。业务中使用了额外的两台服务器,3 个 Sentinel 进程+1 个 Slave 进程,只是为了保证在那小概率的事故中依然做到服务可用。
在实际业务中我们还启用了 supervisor 做进程监控,一旦进程意外退出,会自动尝试重新启动。