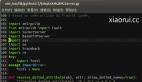
linux arm 内存分布总览
地址范围大小,虚拟转物理的接口函数,各个区域对应的分配函数,该区域有什么作用,使用场合等等。
首先开始第一个区域:CPUvector page null pointer trap
该区域的大小是一个page页的大小,对于那些不支持中断向量重映射的cpu,该区域用来存储对应的中断向量表;
对于那些支持中断向量重映射的cpu,该区域用来扑获0地址的非法访问,即null指针。针对arm体系,他是支持中断向量重映射,该区域一般保留不用,用来扑获null指针。

上图是linux的arm的虚拟地址分布总览,我们按从低地址到高地址的顺序逐个描述,每项的描述包括如下的内容的组和:
第二个区域:应用程序地址空间
地址大小范围属于[0x1000, 0xbf000000],我知道每个应用进程都有如下几个段:text段即存储代码段,data段即存储初始化的数据段,bss段即存储未初始化的数据段,堆(malloc,free),栈(往下生长)。他们的地址分布如下:
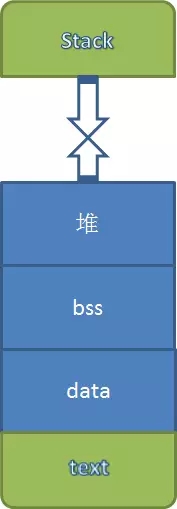
图1
在应用程序加载到内存后,会为每个段,分一个vma的内核结构体,并且为每个段都分配了虚拟地址(虚拟地址和大小都存储在vma结构体中),当可执行程序的各个段在加载的时候,就会给其分配虚拟地址,每个段对应内核的一个vma结构,程序所有段对应的vma,都挂在程序对应的进程的struct mm结构中,但并未给他分配实际的物理地址,待cpu实际去访问它时,才会去实际建立物理到vma指定的虚拟地址映射,并且将对应的段内容从elf文件中拷贝到相应的物理内存中。
譬如当cpu要访问text段时,这个时候并未建立相应的映射表,所以会产生page fault异常,从而在异常处理中,linux的内存管理系统会为其分配物理内存, 并从二进制可执行程序的elf文件读取text段到物理内存,并且为该进程对应的页表建立该物理页到虚拟地址的映射,这样cpu就可以访问该进程的text段,并且执行对应的指令了。
stack跟heap都一样,在cpu有实际的访问时,才会分配物理内存,并建立物理到对应的虚拟地址(在程序加载时,vma中就已经分配了虚拟地址)映射。这样做,就可以节省程序运行时实际物理内存的使用。而不是程序一开始就建立了所有物理到虚拟的映射,从而导致物理内存被大量不必要的消耗。
第三个区域:模块地址
该区域用来为内核模块分配地址,譬如在insmod一个驱动模块时,会通过如下的流程:sysinit_module-->load_module-->layout_and_allocate-->move_module-->module_alloc_update_bounds-->module_alloc来为模块的各个段分配虚拟地址

图2
line42可见:就指定了模块的虚拟地址范围为:[MODULES_VADDR,MODULES_END] = [0xbf000000,0xbfe00000],总计14MB。注意此时__vmalloc_node_range进行了实际的物理内存分配,并且建立了物理到虚拟地址的映射。
第四个区域:PKMAP地址段
该区域跟fixmap区域都是用来将高端物理内存页映射到内核的线性地址范围,以使内核能够访问他。但为什么还要分两个区域呢?他们有什么异同?
kmap和fixmap驱动的地址范围都是有限的,所以不能长久持有,最好使用完后,就尽快的释放。
其中kmap区域的API函数为:kmap/kunmap,该函数可以休眠,在地址资源紧张的时候就会发生休眠。
fixmap区域的api函数为:kmap_atomic/__kunmap_atomic,该函数为每个cpu都保留一个地址槽,并且该函数是原子的,不会休眠。使用kmap_atomic影射高端物理内存页,处理完后(并且该处理不应该休眠,同时kmap_atomic还会禁止抢占),就应该尽快调用__kunmap_atomic进行释放。所以该函数可以在中断上下文中使用
kmap地址段的开始虚拟地址和大小在trunk/arch/arm/mm/mmu.c中的kmap_init函数就指定了。
关于kmap的详细分析,见我的另一篇blog文章。
第五个区域:内核地址空间的直接映射区,即linux内核的低端内存区
该区域也称为内核逻辑地址空间 是指从PAGE_OFFSET(3G)到high_memory之间的线性地址空间,是系统物理内存映射区,它映射了全部或部分(如果系统包含高端内存)物理内存。内核逻辑地址空间与系统RAM内存物理地址空间是一一对应的,内核逻辑地址空间中的地址与RAM内存物理地址空间中对应的地址只差一个固定偏移量(3G),如果RAM内存物理地址空间从0x00000000地址编址,那么这个偏移量就是PAGE_OFFSET(0xc0000000)。
系统初始化过程中将低端内存永久映射到了内核逻辑地址空间,为低端内存建立了虚拟映射页表。低端内存内物理内存的物理地址与线性地址之间的转换可以通过__pa(x)和__va(x)两个宏来进行:
#define __pa(x) ((unsigned long)(x)-PAGE_OFFSET) __pa(x)将内核逻辑地址空间的地址x转换成对应的物理地址,相当于__virt_to_phys((unsigned long)(x)),
__va(x)则相反,把低端物理内存空间的地址转换成对应的内核逻辑地址,相当于((void *)__phys_to_virt((unsigned long)(x)))
该区域的内存分配函数:kmalloc/kfree和__get_free_page都是从低端内存来分配内存
第六个区域:高端内存vmalloc区
该区域是属于linux内核的高端内存地址,该区域分配的虚拟地址是连续的,但对应的物理地址则可能是不连续的。该区域的内存分配api函数为:vmalloc/vfree, 该区域的api可以用来分配大片内存,但对应的物理内存可能是不连续的。该函数会修改页目录映射表,因为要为对应的虚拟地址和物理地址建立映射关系。
另外vmalloc区域跟高端内核(high_memory)有一个8MB的保留区域。端内存的物理地址与线性地址之间的转换不能使用上面的__pa(x)和__va(x)宏,关于该区域linux内核的文档:arm/memmory.txt有如下的描述:
- vmalloc() / ioremap() space.
- Memory returned by vmalloc/ioremap will
- be dynamically placed in this region.
- Machine specific static mappings are also
- located here through iotable_init().
- VMALLOC_START is based upon the value
- of the high_memory variable, and VMALLOC_END
- is equal to 0xff000000.
第七个区域:DMA内存映射区
该区域是为DMA分配内存的,该段区域的开始地址和大小在
trunk/arch/arm/mm/dma-mapping.c中已经指定了。
分别由consistent_base,DEFAULT_CONSISTENT_DMA_SIZE,
CONSISTENT_END指定该区域的开始地址,大小,结束地址。
该区域的内存分配api函数为:dma_alloc_coherent/dma_free_coherent,
该分配函数会建立映射表,并且分配出来的物理地址是连续的。
dma_alloc_coherent的核心函数为:__dma_alloc。具体详细的流程,
请见我的另外一篇blog。在调用这个api进行dma内存分配时,
虚拟地址是从CONSISTENT_END高地址往consistent_base低地址方向分配的,
即第一次dma_alloc_coherent调用的返回值>第二次dma_alloc_coherent
调用的返回值。请看图3一个实际的系统dma分配的内存情况
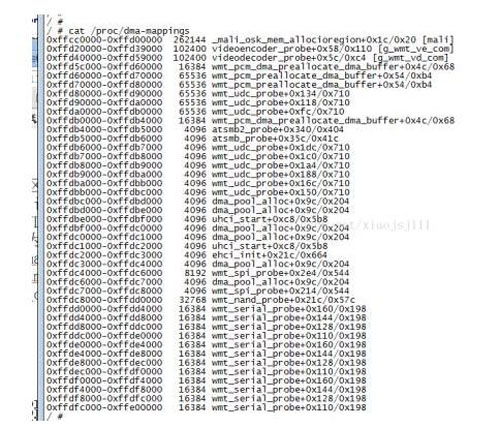
另外dma分配函数分配的物理页是属于低端内存,但他会通过__dma_alloc_remap函数,将该物理页重新映射到dma所属的地址范围。所以同一个物理页存在两个虚拟地址映射,因为该物理页对应的低端内存地址在内核初始化的时候,就已经映射建立好了。
第八个区域:Fixmap映射区
该区域的开始地址和大小在trunk/arch/arm/include/asm/fixmap.h文件中指定了,
该区域的地址范围:[0xfff00000,0xfffe0000],该区域是属于最顶部的pte页表中
(set_top_pte),他为系统中的每个cpu都保留了16个page页的虚拟地址。
该区域有两个特殊函数:
- fix_to_virt/virt_to_fix
- #define __virt_to_fix(x)(((x) - FIXADDR_START) >> PAGE_SHIFT)
表示虚拟地址相对FIXADDR_START偏移的页框数,该返回值应该属于
[0,15]之间。
第九个区域:CPUvector page
该区域是用来映射cpu的中断向量表,因为linux arm使用的高端向量,即cpu中断产生时,pc指针会自动跳转到0xffff0000+4*vector_num的地方。
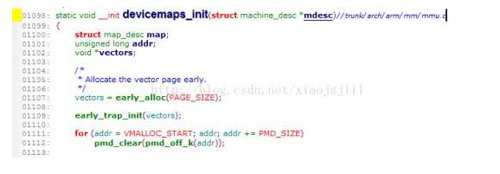
图4
line1107分配一个低端的物理内存页框,line1109 early_trap_init将中断向量表的内容拷贝到这个新分配的物理页框中。

图5
line1149-1153:将line1107行分配的物理页映射到虚拟地址0xffff0000,为cpu中断产生时,做好准备(对应的地址有各自的跳转代码,来处理各自的中断异常)。在这里这个物理页同样是存在两个虚拟地址的映射,一个是低端虚拟地址的影射,一个是高端虚拟地址的映射
最后附一个我们实际使用中的contexA9双核,ram为1GB大小的系统的linux内存分布情况图:
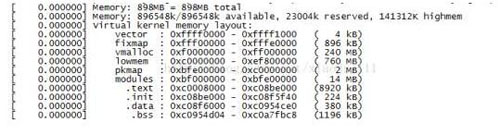
图6
可以结合图1和图6一起分析来加深对linux的内存分布情况的理解,至于图1是怎么来的,就需要看上面每个段的具体分析。