为保障线上 App 的用户体验,我们一般都会对线上 App 的 crash 率做实时监控,一旦检测到 spike,可以即刻调查原因,但这一切的前提是 crash 日志能够准确上报。
crash 日志上报有两个难点:
crash handler 安装之前的代码要绝对稳定
- 如果日志采集器还没成功启动就 crash 了,自然什么日志也无法采集到。这一点并没有太多技巧可言,只能严格限制 handler 启动之前可以执行的代码。
App ***循环 crash 时上报
- crash 日志上报时,会发送网络请求,如果请求成功之前 App 又发生 crash 该如何处理?用户甚至会陷入***循环的 crash 中。
这篇文章介绍下出现第二种情况时,如何准确上报 crash 日志。
首先我们需要一种比较可靠的方式,可以在 app 启动时判断上次是否发生了启动 crash。介绍一个可行的思路。
如何检测连续闪退
连续闪退包含两个元素,闪退和连续。只有这两个元素同时具备时,才会影响我们的日志上传。闪退的定义可以简单为
- app crash 时间 - app 启动时间 <= 5s (或者其他 threshold)
连续的定义为,至少接连出现两次或者以上。一般 2 次就够了,很多时候用户连续经历两次闪退,就会放弃尝试。
我们可以通过记录若干个特殊的时间点 timestamp 来试图还原 App crash 场景下的生命周期。
App 启动 timestamp,定义为 launchTs
- App 每次启动时,记录当前时间,写入时间数组。
App crash timestamp,定义为 crashTs
- App 每次启动时,通过 crash 采集库,获取上次 crash report 的时间戳,写入时间数组。
App 正常退出 timestamp,定义为 terminateTs
- App 在接收到 UIApplicationWillTerminateNotification 通知时,记录当前时间戳,写入时间数组。注意,还有很多种 App 退出行为的时间戳是无法被准确记录的。
之所以要记录 terminateTs,是为了排除一种特殊情况,即用户启动 App 之后立即手动 kill app。如果我们正确记录了上面三个时间戳,那么我们可以得到一个与 App crash 行为相关的时间线。比如:
- launchTs => crashTs => launchTs => terminateTs
或者
- launchTs => launchTs => launchTs
或者
- launchTs => crashTs => launchTs => crashTs => launchTs
请自行脑洞上面三种时间线的行为特征。很明显,第三种时间线看上去是连续 crash 了两次。我们只需要加上时间间隔判断,就能得知是否为连续两次闪退了。注意,如果两个 crashTs 之间如果存在 terminateTs,则不能被认为是连续闪退。检测代码比较简单,我就不贴了。
这个时间线只是记录与 crash 相关的 App 启动和退出行为,还有很多特殊的时间点没有记录,比如 App 在 前台发生 out of memory(FOOM),App 在前台 main thread 卡住被系统 Watch Dog 杀掉,iOS 系统升级时 App 被强杀,App 从 AppStore 升级时被强杀等等,这些特殊的时间点都没有记录,不过这些并不影响我们的 App 连续闪退检测,所以可以忽略。
这里指的注意的是,因为启动时要从 disk 读取时间线记录,涉及磁盘读写,会对 App 的启动时间产生影响,一个优化点是,在每次写入时间点移除掉较老的 timestamp,比如只记录最近 5 个时间戳。或者在没有读取到 crash 日志时,甚至不用启动连续闪退检测的整个流程。
接下来,我们看假设检测到连续闪退,我们如何继续上传日志。
同步等待 Crash 日志上传
最直白的方式,在 App 的代码继续执行之前,先等待日志上传成功。
把网络请求改成同步的?这会卡住 UI 线程,网络差的场景下会被系统 watch dog 强杀,显然不可取。
我们可以依旧保持异步网络请求,但是,暂时中断 UI 线程的流程,让整个 App 处于 UI 线程的 runloop 等待中,一旦网络请求成功,则跳回到 UI 线程的原有代码流程。
看着简单的实现,有几个细节需要注意。首先我们需要增加一个 App 交互,一旦进入 runloop 等待,展示一个 loading 界面,告知用户耐心等待。其次,这个等待时间不能过长,我个人建议不超过 5s,一旦超过 5s,无论 crash 日志上传的 request 是否成功,都恢复 App 原有代码流程。5s 内日志都无法上传成功的情况应该比较小,除非日志文件过大。
这种做法缺陷也很明显,一是改动比较大(修改了原有代码流程),二是需要增加新的 UI 交互,三是延长了用户的等待时间。
我们来看另一种取巧的做法。
启用后台进程上传 Crash 日志
其实最理想的日志上传,是将上传的 request 放到另一个不同的进程,那么即使 App 又发生闪退,也不会影响到另一个进程代码的执行。
问题是,iOS app 都处于 sandbox 环境下,系统不允许代码 fork 一个新进程。
幸运的是,从 iOS 8 开始,系统对 NSURLSession 新增了一个 background session 特性。这个特性允许 NSURLSession 将网络请求放入到一个单独的进程中执行。我个人感觉,这个特性设计,原本是为了增强某些 App 后台下载音视频等资源的体验。我实际测试下来,发现不管下载或者是上传,我们都可以将网络请求放入另一个进程。代码也很简单,比如我写一段如下的测试代码:
- NSURLSessionConfiguration *config = [NSURLSessionConfiguration backgroundSessionConfigurationWithIdentifier:@"com.mrpeak.background.crashupload"];
- NSURLSession *session = [NSURLSession sessionWithConfiguration:config delegate:self delegateQueue:[NSOperationQueue new]];
- NSURL *url = [NSURL URLWithString:@"https://images.unsplash.com/photo-1515816949419-7caf0a210607?ixlib=rb-0.3.5&ixid=eyJhcHBfaWQiOjEyMDd9&s=f46b60857b4826e733da34993ec26a2f&auto=format&fit=crop&w=1534&q=80"];
- NSURLSessionDownloadTask *task = [session downloadTaskWithURL:url];
- [task resume];
- exit(0);
执行之后,我们可以在 console 中看到如下日志:
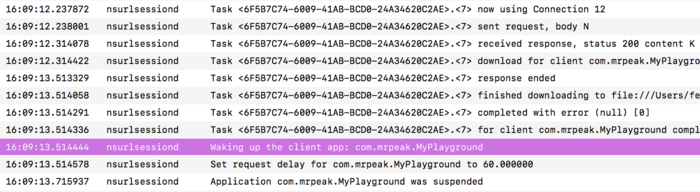
可以清楚的看到 nsurlsessiond 进程如何替我们完成网络请求,并试图唤醒已经异常退出的 App。
当然这种最理想的方式,也有一些细节需要处理。比如如何告知 App 某个 crash 日志上传成功,并从本地移除。由于连续闪退的 App 处于极度不稳定的状态,所以任何代码逻辑都无法确保顺利完成。
我个人感觉一种比较理想的方式是,给后台进程上报的日志加上某个特殊的 flag,然后在后台通过 client request ID 和这个 flag 来做去重和整理。
线上 App 连续闪退是一种极其恶劣和可怕的故障,可怕之处在于,发生大面积连续闪退且无法被监控时,你正哼着小曲敲着代码,老板突然发现自己手机上 App 启动不了了,一打开 AppStore,发现一星差评潮水般涌来,如果是主流 App 甚至还会上科技新闻,不难预料一口黑漆漆的大锅正在成形。下次 App 的升级介绍里一定会出现 "fire peter" 了。
全文完。