大数据文摘作品
编译:傅一洋、汪小七、张南星、GAO Ning、夏雅薇
高级的编程是逻辑思维的流露,会编程只代表你懂了这门语言的语法,但是会写清晰简洁易懂可迭代的代码才是程序员该追求的境界。编程入门已经不容易,但是如果能够在早期树立一些正确的“代码观”,或许可以让你的编程之路升级得更快。作者苦口婆心地给出了25条建议,句句真言。
首先我要声明的是:如果你是编程新手,本文并不是要让你对自己犯的错误感到愧疚,而是要你对这些错误有更好的认知,并避免在未来再犯。
当然,这些错误我也经历过,但是从每个错误中都学到了一些新东西。现在,我已经养成了一些好的编程习惯,我相信你也可以!
下面是这些常见的错误,顺序不分先后。
1. 写代码前缺少规划
一般来说,创作一篇高质量的文章不易,因为它需要反复推敲研究,而高质量的代码也不例外。
编写高质量代码是这样一个流程:思考、调研、规划、编写、验证、修改。(貌似没办法编成一个好记的顺口溜)
按照这样的思路走,你会逐渐形成良好的编程习惯。
新手最大的错误之一就是太急于写代码,而缺乏足够的规划和研究。虽然对于编写小程序而言是没多大问题的,但对于大项目的开发,这样做是很不利的。
为了防止代码写完之后发现重大问题,写之前的深思熟虑是必不可少的。代码只是你想法的流露。
| 生气的时候,在开口说话前先数到十。如果非常生气,就数到一百。
——托马斯·杰斐逊 |
我把它改成针对写代码的版本:
| 审查代码时,重构每一行之前,先数到十。如果代码还没有测试,就数到一百。
——Samer Buna |
编程的过程主要是研读之前的代码,思考还需要修改什么,如何适应当前系统,并规划尽量小的改动量。而实际编写代码的过程只占整个过程时间花费的10%。
不要总认为编程就是写代码。编程是基于逻辑的创造,慢工出细活。
2. 写代码之前规划过度
虽说写代码前充分规划是好,但凡事都有个度,还没开始做,就思考太多,也是不可取的。
不要期望世界上存在完美的规划,至少编程的世界中是不存在。好的规划可以作为起点,但实际情况是,规划是会随后续进行而改变的,规划的好处只是能让程序结构条理更清晰,而规划太多只会浪费时间。
瀑布式开发是一种系统线性规划的开发方法,它严格遵循预先计划的需求、分析、设计、编码、测试的步骤顺序进行,步骤成果作为进度的衡量标准。在这种方法中,规划是重中之重。如果只是编写小程序,也完全可以采用这种方法,但要对于大的项目,这种方法完全不可取。任何复杂的事情都需要根据实际情况随机应变。
编程是一个随时需要根据实际情况作出改变的工作。你后续可能会因为一些原因要添加或删除的某些功能,但这些情况瀑布计划中可能你永远也想不到。所以,你需要敏捷的开发模式。
但是,每一步之前是要有所规划的,只不过规划的过少或过多都会影响代码的质量,代码的质量非常重要。
3. 低估代码质量的重要性
如果你无法兼顾代码的多项质量指标,至少要保证它的可读性。凌乱的代码就相当于废品,而且不可回收。
永远不要低估代码质量的重要性。你要将代码看作沟通的一种方式,作为程序员,你的任务是交代清楚目前任务是如何实施的。
我最喜欢一句编程俚语是:
| 写代码的时候可以这样想,维护你代码的家伙是一个知道你住在哪里的暴力精神病患者。
——John Woods |
很形象是不是?
即便是一些细节。例如,你的代码可能会因为排版问题或大小写不一致而不被认可。
- tHIS is
- WAY MORE important
- than
- you think
还需要注意的是避免语句过长。任何超过80个字符的文本都是难以阅读的。你可能想在同一行放置长条件以便看到完整的if语句,这是不可取的,一行永远不要超过80个字符。
这种小问题可以通过linting工具或格式化工具轻松解决。比如在JavaScript中两个完美结合的优秀工具:ESLint和Prettier。多用它们,让工作更轻松。
还有一些与代码质量相关的错误:
- 任何超过10行的函数都太长了。
- 一定不要出现双重否定句。
- 使用简短的,通用的或基于类型的变量命名。尽量保证变量命名能清晰地表述变量。计算机科学领域只有两件难事:缓存失效和变量命名。
- 缺乏描述地插入一些字符串和数字。如果要使用固定的字符串或数值,应该将其定义为常量,并命名。
- “对于简单的问题,担心花费时间而草率地处理”。不要在众多问题中进行跳跃式选择,按部就班地来。
- 认为代码越长越好。其实,大多数情况下,代码越短越好。只有在追求可读性的情况下可适当详细些。比如,不要为了缩短代码而使用很长的单行表达式或嵌套表达式,但也不要增加冗余的代码。最好的是,删去所有不必要的代码。
- 过多使用条件语句。大部分你认为需要条件语句的情况都可以不通过
它来解决。因此,考虑尽可能多的备选方案,根据可读性进行挑选。除非你知道如何测试代码性能,否则,不要试图优化。还有就是:避免Yoda条件或条件嵌套。
4. 选择1号方案
当我刚开始编程时,一旦遇到问题,我会立刻寻找解决方案并重新运行我的程序。而不是先考虑我的头号方案复杂性和潜在的失败原因。
虽然1号方案极具诱惑性,但在研究了所有解决方案后,通常能发现更好的。如果无法想出多种方案,说明你对问题了解不够。
作为专业程序员,你的工作不是找到办法,而是找到最简捷的办法。“简捷”的意思是方案必须正确,可执行,且足够简单,易读,又便于理解和维护。
| 软件设计有两种方法。一种是设计的足够简单,没有瑕疵,另一种是设计的足够复杂,没人看得出明显瑕疵。
——C.A.R.霍尔 |
5. 吊死在一棵树上
这是我常犯的错误,即便确定了我的头号方案并不是最简单的解决方案,仍然不放手。这可能与我的性格有关。大多数情况下这是一种很好的心态,但不适用于编程。事实上,正确的编程心态是,将早期失败和经常性失败看成一种常态。
当你开始怀疑某个方案的时候,你应该考虑放下它并重新思考,不管你之前在它这里投入了多少精力。学会利用像GIT这样的源代码管理工具,它可以帮助你实现代码分支,尝试多种方案。
不要认为你付出了精力的代码就是必须采用的。错误的代码要摒弃。
6. 闭门造车
很多次,在解决问题需要查阅资料时,我却直接尝试解决问题,浪费了很多时间。
除非你正在使用的是某种尖端技术,否则,遇到问题时,谷歌一下吧,因为一定会有人也遇到了同样的问题,并找到了解决方法,这样,能节省很多时间。
有时候谷歌之后,你会发现你所认为的问题并不是问题,你需要做的不是修复而是接受。不要认为你了解一切,Google会让你大吃一惊的。
不过,要谨慎地使用谷歌。新手会犯的另一个错误是,在不理解代码的情况下,原样照搬。尽管这可能成功解决了你的问题,但还是不要使用自己不完全了解的代码。
如果想成为一名创造性的程序员,就永远不要认为,自己对在做的事情了如指掌。
| 作为一个有创造力的人,最危险的想法是认为自己知道自己在做什么。
——布雷特·维克多 |
7. 不使用封装
这一点不只是针对使用面向对象语言的例子,封装总是有用的,如果不使用封装,会给系统的维护带来很大的困难。
在应用程序中,每个功能要与用来处理它的对象一一对应。在构建对象时,除了保留被其他对象调用时必须传递的参数,其他内容都应该封装起来。
这不是出于保密,而是为减少应用程序不同部分之间的依赖。坚持这个原则,可以使你在对类,对象和函数的内部进行更改时,更加的安全,无需担心大规模的毁坏代码。
对每一个逻辑概念单元或者块都应该构建对应的类。通过类能够勾画出程序的蓝图。这里的类可以是一个实际对象或一个方法对象,你也可以将它称作模块或包。
在每个类中,其包含的每套任务要有对应的方法,方法只针对这一任务的执行,且能成功的完成。相似的类可共同使用一种方法。
作为新手,我无法本能地为每一个概念单元创建一个新类,而且经常无法确定哪些单元是独立的。因此,如果你看到一套代码中到处充斥着“Util”类,这套代码一定是新手编写的。或者,你做了个简单的修改,发现很多地方也要进行相应地修改,那么,这也是新手写的。
在类中添加方法或在方法中添加更多功能前,兼顾自己的直觉,花时间仔细思考。不要认为过后有机会重构而马虎跳过,要在第一次就做对。
总而言之,希望你的代码能具有高内聚性和低耦合性,这是一个特定术语。意思就是将相关的代码放在一起(在一个类中),减少不同类之间的依赖。
8. 试图规划未知
在目前项目还正在编写的时候,总是去想其他的解决方案,这是忌讳的。所有的谜团都会随着代码的一行行编写而逐一解开。如果,对于测试边缘案例进行假设,是件好事,但如果总想要满足潜在需求,是不可取的。
你要明确你的假设属于哪一类,避免编写目前并不需要的代码,也不要空想什么计划。
仅凭空想,就认为未来会需要某种功能,因而尝试编写代码,是不可取的。
根据目前的项目,始终寻求最少的代码量。当然,边缘情况是要考虑的,但不要过早落实到代码中。
| 为了增长而增长是癌细胞的意识形态。
——Edward Abbey |
9. 错误使用数据结构
在准备面试的时候,新手往往太过于关注算法。掌握好的算法并在需要时使用它们固然不错,但记住,这与你的所谓“编程天赋资质”无关。
然而,掌握你所用语言中各种数据结构的优缺点,对你成为一名优秀的开发者大有裨益。
一旦你的代码中使用了错误的数据结构,那明摆着,你就是个新手。
尽管本文并不是要教你数据结构,但我还是要提几个错误示例:
(1) 使用list(数组)来替代map(对象)
最常见的数据结构错误是,在管理记录表时,使用了list而非map。其实,要管理记录表,是应该使用map的。
例如,在JavaScript中,最常见的列表结构是数组,最常见的map结构是对象(最新JavaScript版本中也包含图结构)。
因此,用list来表示map结构的数据是不可取的。虽然这种说法只是针对于大型数据集,但我认为,任何情况下都应如此,几乎没有什么情况,list能比map更好了,而且,这些极端情况在新版本的语言中也逐渐消失了。所以,只使用map就好。
这一点很重要。主要是由于访问map中的元素会比访问list中的元素快得多,访问元素又是常有的过程。
在以前,list结构是很重要的,因为它能保证元素的顺序,但现在,map结构同样能实现这个功能。
(2) 不使用栈
在编写任何需要递归的代码时,总是去使用递归函数。但是,这样的递归代码难以优化,特别在单线程环境下。
而且,优化递归代码还取决于递归函数返回的内容。比如,优化两个或多个返回的递归函数,就要比优化单个返回值的递归函数困难得多。
新手常常忽略了使用栈来替代递归函数的做法。其实,你可以运用栈,将递归函数的调用变为压栈过程,而回溯变为弹栈过程。
10. 把目前的代码变得更糟
想象一下,给你这样一间凌乱的房间:
然后,要求你在房间里再增加一个物件。既然已经一团糟了,你可能会想,把它放在任何地方都可以吧。因此,很快就能完成任务。
但是,在编写代码时,这样做只会让代码越来越糟糕!你要做的是,保证代码随着开发的进行,变得越来越清晰。
所以,对于那间凌乱的房间,正确的做法是:做必要的清理,以便能将新增的物品放置在正确的位置。比如,你要在衣柜中添置一件衣服,那就需要先清理好地面,留出一条通向衣柜的路,这是必要的一步。
以下是一些错误的做法,通常会使代码变得更糟糕(只举了一部分例子):
- 复制代码。如果你贪图省事而复制代码,那么,只会让代码更加混乱。就好比,要在混乱的房间中,添加一把新椅子,而不是调整现有椅子的高度。因此,头脑中始终要有抽象的概念,并尽可能地去使用它。
- 不使用配置文件。如果你的某个值在不同时间、不同环境下是不一样的,则该值应写入配置文件中。或者,你需要在代码中的多个位置使用某值,也应将它写入配置文件。这样的话,当你引入一个新的值时,只需要问自己:该值是否已经存在于配置文件?答案很可能是肯定的。
- 使用不必要的条件语句或临时变量。每个if语句都包含逻辑上的分支,需要进行双重测试。因此,在不影响可读性的情况下,尽量避免使用条件语句。与之相关的一个错误就是,使用分支逻辑来扩展函数,而不去引入新函数。每当你认为你需要一个if语句或一个新的函数变量时,先问问自己:是否在将代码往正确的方向推进?有没有站在更高的层面去思考问题?
关于不必要的if语句的问题,参考一段代码:
- function isOdd(number) {
- if (number % 2 === 1) {
- return true;
- } else {
- return false;
- }
- }
上面的isOdd函数是存在一些问题的,你能看出最明显问题吗?
那就是,它使用了一个不必要的if语句。以下为其等效的代码:
- function isOdd(number) {
- return (number % 2 === 1);
- };
11. 注释泛滥
我已经学会了,尽量不去写注释。因为大多数的注释可以通过对变量更好的命名来代替。
例如以下代码:
- // This function sums only odd numbers in an array
- const sum = (val) => {
- return val.reduce((a, b) => {
- if (b % 2 === 1) { // If the current number is even
- a+=b; // Add current number to accumulator
- }
- return a; // The accumulator
- }, 0);
- };
其实,也可以写成这样没有注释的,效果相同:
- const sumOddValues = (array) => {
- return array.reduce((accumulator, currentNumber) => {
- if (isOdd(currentNumber)) {
- return accumulator + currentNumber;
- }
- return accumulator;
- }, 0);
- };
所以,每次写注释前,先思考一下:能否通过改善参数的命名来避免写注释呢?
但有一些情况下,是必须写注释的。比如,当你用需要注释来表述代码的目的,而不是代码在做什么时。
如果你实在想写注释的话,那就不要描述那些过于明显的问题。以下是一些无用注释的例子,它们只会干扰代码的阅读:
- // create a variable and initialize it to 0
- let sum = 0;
- // Loop over array
- array.forEach(
- // For each number in the array
- (number) => {
- // Add the current number to the sum variable
- sum += number;
- }
- );
所以,不要成为这样的程序员,也不要接受这样的代码。如果必须处理这些注释的话,那就删掉好了。要是碰巧你雇佣的程序员总是写出这样的代码的话,快点解雇他们。
12. 不写测试
我认同这一点:如果你自认为是专家,且有信心在不测试的情况下编写代码,那么在我看来,你就是个新手。
如果不编写测试代码,而用手动方式测试程序,比如你正在构建一个Web应用,在每写几行代码后就刷新并与应用程序交互的话,我也这样做过,这没什么问题。
但是,手动测试代码,是为了更明确如何在之后进行自动测试。如果成功测试了与应用的交互,那就应该返回到代码编辑页,编写自动测试代码,以便下次向项目添加更多代码时,自动执行完全相同的测试。
毕竟,作为人类,每次更改代码后,难免会有忘记去重新测试曾经成功过的代码,所以,还是把它交给计算机完成吧!
如果可以,就在编写代码之前,先猜测或设计测试的过程。测试驱动开发(TDD)这种方法不仅仅是流行,它还能使你对功能的看法发生积极的变化,以及为它们提供更好的设计方案。
TDD并不适合每个人,每个项目,但是,至少要会用它。
13. 认为不出错就是正确的
看看这个实现了sumOddValues功能的函数,有什么问题吗?
- const sumOddValues = (array) => {
- return array.reduce((accumulator, currentNumber) => {
- if (currentNumber % 2 === 1) {
- return accumulator + currentNumber;
- }
- return accumulator;
- });
- };
- console.assert(
- sumOddValues([1, 2, 3, 4, 5]) === 9
- );
测试通过,一切顺利,但情况真是如此?
上述代码问题在于,没有考虑到所有情况。尽管,它能正确地处理一部分的情况(测试时恰好命中这些情况之一)。来看看其中的几个问题:
问题#1:没有考虑输入为空的情况。在没有传递任何参数的情况下调用函数,会发生什么?会出现如下所示的错误:
- TypeError: Cannot read property 'reduce' of undefined.
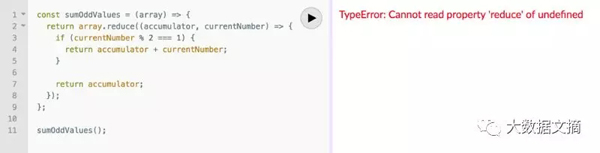
这通常是个坏兆头,原因主要有二:
- 用户无法看到函数内部,不知其如何实现的。
- 异常提示对用户没有任何帮助,但你的函数又无法满足用户需求。倘若异常提示表述的更明确些,用户就能知道自己是如何错误地调用了函数。比如,可以在函数中,设计抛出一个异常,提示用户定义出错了,如下所示:
- TypeError: Cannot execute function for empty list.
也可以不抛出异常,忽略空输入并返回0的总和。但是,无论如何,必须对这些情况有所处理。
问题#2:没有处理无效输入的情况。如果传入的参数是字符串,整数或对象而不是数组,会发生什么情况?
出现了下面的情况:
- sumOddValues(42);
- TypeError: array.reduce is not a function
那么,很不幸,因为array.reduce确实是定义过的!
我们命名了函数的参数数组,因此,在函数中,将所有调用该函数的对象(42)标记为数组。所以,就会抛出异常:42.reduce不是一个函数。
这个错误很令人困惑不是?也许,更值得注意的错误是:
- TypeError: 42 is not an array, dude.
问题#1和#2被称为边缘情况,他们都是常见的边缘案例。但通常,有一些不太明显的边缘案例也是需要考虑的。例如,我们传入负数,会发生什么?
- sumOddValues([1, 2, 3, 4, 5, -13]) // => still 9
-13是奇数,但结果是你想要的吗?或许它应该抛出异常?求和过程是否应该包括参数中的负数?还是应该忽略?也许你意识到,该函数应命名为sumPositiveOddNumbers。
这种情况处理起来很容易,但是,更重要的一点,如果不写一个测试文档来记录测试案例的话,后续的维护者也将对此毫无线索,甚至认为忽视负数是故意的或是出现了疏忽。
问题#3:测试没有涵盖所有的一般情况。除了边缘情况,函数也有可能无法正确处理某个合理、有效的情况:
- sumOddValues([2, 1, 3, 4, 5]) // => 11
上例中,不应将2计入总和。
原因很简单:reduce函数是将第二个参数作为累加器的初始值的,如果该参数为空(如代码所示),reduce将使用数组中第一个值作为累加器的初始值。这就是为什么在上面测试用例中,第一个偶数值也包含在了总和中。
即便你在编写的过程中就发现了这个问题(并解决了),也是要编写相应的测试案例并记录的,测试记录还应包含其他测试用例,如全偶数的情况,列表中存在0的情况,列表为空的情况。
如果测试记录很少,又忽略了很多情况,忽视了边缘情况,那么,这一定是新手干的。
14. 对已经存在的代码不再质疑
除非你是超级程序员,可以独当一面。否则,毫无疑问你会碰到许多愚蠢的代码。新手往往意识不到这些,他们会认为,既然作为代码库一部分,又用了很长时间的代码,一定是没有问题的。
更糟的是,如果这些代码中存在不妥,新手可能就会在其他地方重复这些不妥。因为他们认为,代码库中的代码是没有问题的,从中学到的方法也是没有问题的。
还有一些代码,看起来很糟糕,但是,它可能包含着某种特殊的情况,从而迫使开发人员必须这么写。这些地方,常常会有详细的注释,以将情况告知给新手,并说明,代码为何要这么写。
作为新手,你应该假设任何不明白或不正规的代码都是不好的。然后,去提问,去质疑,去查他的git blame记录!
如果代码的作者无处可寻,那就仔细研究代码本身,理解其中的所有。只有当你完全理解后,才能形成自己的观点(不论好与坏)。在此之前,不要草率地对代码下结论。
15. 沉迷于最佳实践
我认为“最佳实践”这个词着实不好,它意味着无需再深入研究,这已经是最好的结果了,毋庸置疑!
但编程中没有最好只有更好,只能说对某种程序而言,目前这已经是比较好的方案了。
甚至某些我们以前认为的最佳实践,现在已经不是最好的解决方案了。
只要你肯花时间去研究,总能发现更好的方案,所以不要再执着于最佳实践,尽你努力做到最好即可。
不要因为你在某个地方读到的一句名言,或是你看到别人这么做了,或是听人说这是最佳实践就去做某件事。
16. 沉迷于性能优化
| 在编程中过早优化是万恶之源(至少大部分是)。
——Donald Knuth (1974年) |
自从Donald Knuth发表了以上观点之后,编程就发生了很大的变化,至今为止,我认为这个观点都是有价值的。
记住一条好的规则:如果你不能有效地量化代码中的问题,那就别试图去优化它。
如果在执行代码前已经在优化了,那么你很可能过早的进行了优化,这是完全没必要的,只是在浪费时间。
当然在你写新代码之前一些明显需要优化的内容还是要考虑优化的。例如,在Node.js中,你要确保你的代码中没有泛滥的使用循环或阻止调用堆栈,这些是非常重要的,这是你必须牢记要提前优化的一个例子。所以在编写过程中,可以时常问问自己:我准备写的代码会阻止调用堆栈吗?
应该避免对任何不能量化的代码进行任何不明显的优化,否则反而会不利。可能你认为你这样做会带来性能上的提升,但事实上这会成为新的不可预料的bug来源。
因此,不要浪费时间去优化那些不能量化的性能问题。
17. 不以最终的用户体验为目标
在应用程序中添加特性最简单的方法是什么?从你自己的角度看,或许是看它如何适应当前的用户界面,对吧?如果这个功能是要捕获用户输入的,那么把它加到已有的那些表单中。如果这个功能是要添加一个页面链接,那就把它加到已有的嵌套链接菜单中。
不要自以为是。要站在终端用户角度来开发,这样才是真正的专业人员。这样的开发者才会去思考有这个功能诉求的用户需要什么,用户又会如何操作。而且他们会考虑如何能让用户更便捷地找到和使用这个功能,而不是只考虑如何在应用程序中添加这个功能,而不考虑这个功能的可发现性和可用性。
18. 工作时没有选对适合的工具
每个人在完成编程的相关活动中,都有一套自己喜欢使用的工具。其中有一些很好用,也有一些不好用,但是大多数工具只是对某一项特定任务很棒,而对其他任务来说都没有那么好。
如果要把钉子钉在墙上,锤子确实是把好工具,但如果要用锤子来旋螺丝钉,那就是很糟糕的工具了。不能只是因为你“喜欢”锤子,就用它来旋螺丝钉。也不能因为锤子是亚马逊中最受欢迎的工具,用户评价得分5.0,就用它来旋螺丝钉。
根据受欢迎程度来选择工具,而不是针对问题的适用性来选择工具是新手的一个标志。
对于新手而言,另一个问题是:你也许根本不知道对一项特定工作来说什么工具“更好”。在你当前的认知范围内,也许某一种工具就是你所知道的最好的工具。但是,跟其他工具相比时,它并不是首选。你需要熟悉所有可用的工具,并且对刚开始使用的新工具保持开放的心态。
一些程序员是拒绝使用新工具的,他们对于现有的工具很满意,而且他们可能也不想去学习任何新的工具。我明白,我也能理解,但是这显然是不对的。
工欲善其事,必先利其器。你可以用原始工具建造一个小屋,并享受你的甜蜜时光;你也可以投入时间和资金去获得好工具,这样你就可以更快地建造一座更好的房子。工具是不断更新的,而你也需要习惯去不断学习并使用它们。
19. 不理解代码问题会造成数据问题
一个程序非常重要的一方面就是某种格式数据的管理,该程序将是添加新记录、删除旧记录和修改其他记录的界面。
程序的代码即使有一点点的小问题,都会给其管理的数据带来不可预估的后果,尤其当你所有的数据验证都是通过那个漏洞程序完成时,则更是如此。
当涉及到代码和数据的关系时,初学者可能不会立即将这些点联系起来。他们可能觉得在生产中继续使用一些错误代码也是可以的,因为特征X是不用运行的,它没那么重要。但问题是错误代码可能会不断地导致数据完整性问题,虽然这些问题在一开始的时候并不明显。
更糟糕的是,在修复漏洞时,并没有修复漏洞所导致的细微的数据问题,就这样交付代码只会积累更多的数据问题,且这样的问题会被贴上“不可修复”的标签。
那么如何避免让自己发生这些问题呢?你可以简单地使用多层次的数据完整性验证,不只依赖于单个用户界面,应该在前端、后端、网络通信和数据库中都创建验证。如果你不想这么做,那么请至少使用数据库级别的约束。
要熟练掌握数据库约束,并学会在数据库中添加新列或新表时使用它们:
- NOT NULL是对列的空值约束,表示该列不允许使用空值。如果你的应用程序中设定某个字段必须有值,那么在数据库中它的源数据就应该定义为not null。
- UNIQUE是对列的单一约束,表示在整个表中该列不允许有重复值。比如,用户信息表的用户姓名或者电子邮件字段,就适合使用这个约束。
- CHECK约束是一个自定义表达式,对于满足条件的数据,计算结果为True。例如,如果有一列值必须是介于0到100之间的百分比,则可以使用CHECK约束来强制执行。
- PRINARY KEY(主键)约束表示某一列的值必须不为空,且不重复。你可能一直在用这个约束,数据库中的每个表都必须有一个主键来识别不同的记录。
- FOREIGN KEY(外键)约束表示某一列的值必须与另一个表的某一列值相匹配,通常来说外键约束也会是主键约束。
对于新手来说,另一个与数据完整性相关的问题是缺乏对事务处理(transactions)的思考。如果多个操作需要更改同一个数据源,且它们相互依赖时,则必须把它们包装在一个事务当中,这样当其中一个操作失败时就可以进行回滚。
20. 推倒重来
这是一件很麻烦的事情。编程过程中,有时的确是需要推倒重来。编程不是一个界限分明的领域,变化层出不穷,新需求提出的速度远超于任何团队可以应对的能力范围。
打个比方,基于当前的速度,如果你需要不同种类的轮胎,除了改进我们都熟悉且喜爱的轮胎以外,也许我们需要换一种角度思考。然而,除非真的需要特殊设计的轮胎,否则没有必要推倒重来。就将就用用原来的轮胎吧。
不要浪费宝贵的时间在寻找所谓的最好的轮胎之上。快速搜索,然后使用所寻找到的内容。只有在这些轮胎真的没法像宣传的那样好好工作时,再进行更换。
编程最酷的一件事就是大多数轮胎都是透明的,你可以看到它内部的构造,能够非常容易地判断代码的质量高低。
所以尽量使用开源代码。开源包的缺陷更容易解决,更容易被替代,也更容易从内部支持。然而,当你需要一个轮子时,不要买一个全新的车,然后把你现在的车放在那辆新车上。
也就是说,不要在代码里加载一整个包,然后只使用里面的一两个函数。最好的例子就是JavaScript中的lodash程序包。如果你只是想随机排列一个数组,只需要加载shuffle方法就好,不要加载一整个令人绝望的lodash程序包。
21. 厌恶代码审查
新程序员们的一个明显特征就是把代码审查当做批评,他们不喜欢、不珍惜,甚至是恐惧代码审查。
大错特错,如果你也有同样的感受,那么你需要立刻改变你的态度。把每次代码审查都看做是学习机会,用开放的心态欢迎、珍惜它们,并且从中学习。更为重要的是,要向给你提供了指导的审查员们表示感谢。
你需要接受一个事实——每个人都是终生代码学习者。大多数代码审查都能教给一些你以前可能不知道的知识,所以请将代码审查当做是一项学习资源吧。
有时,审查员也会犯错误,这时候就轮到你去教他们一些东西了。然而,如果审查出来的问题不仅仅是由于你的代码导致的错误,那么也许还是需要进行代码修改。如果无论如何你都需要教审查员一些东西的话,那么谨记:教授别人是你作为程序员最有收获的一件事。
22. 不使用源代码控制
新手们有时会低估一个好的源代码/版本控制系统,所谓好的系统,我指的是Git。
源代码控制并不仅仅是指把代码修改推送给别人,然后进行版本变更,这个行为的意义远不止如此。源代码控制的主要目的在于清晰的历史记录。
代码需要时常进行回顾,而代码的修改过程的记录将会极大助力于一些疑难杂症的解决,这也是为什么我们会很在意提交信息。代码控制同样也是一个沟通实施信息的渠道,使用这些零碎的提交历史,能够帮助未来的代码维护人员了解代码的发展情况以及现在所处的状态。
常常提交、尽早提交,并且出于对连贯性的尊重,请在提交标题中使用现在时态。信息最好尽量详尽,但谨记它们应该是经过提炼总结的。如果你需要好几行来阐述想表达的内容,也许意味着你的提交信息太长了。重来吧!
不要在提交信息中不要放入任何不必要的信息。例如,不要列出被加载、被修改或者被删除的文件。
这些列表本身已经包含在提交的代码中了,并且能够通过一些Git命令参数实现,它们只会成为总结信息中的噪音。一些团队喜欢在每个文件改变中都做一次总结,我认为这是另一种提交信息太冗长的标志。
源代码控制和可发现性也有关系。当你遇到一个函数,需要开始了解它的需求或者设计,你可以寻找介绍它的提交信息,然后阅读函数相关内容。
提交信息甚至可以帮你找到程序中导致缺陷的代码是哪些。Git在提交中提供了一个二进制搜索(bisect命令)来精准定位导致缺陷的罪恶源头。
源代码控制也可以在代码变动正式生效之前发挥极大的作用。诸如阶段转换、选择性打补丁、重置、隐藏、修复、应用、区分、撤销以及其他许多对代码编辑有用的工具。所以好好理解、学习、使用并且珍惜他们吧。
你知道的Git特性越少,那么你离文章中所说的新手就越接近。
23. 过度使用共享状态
同样的,这一点并不是在比较函数式编程与其他算法的优劣区别,那是另外一篇文章要谈论的话题。
需要指出的是,共享状态往往是问题的源头,如果可能的话,尽量避免使用它。如果无法避免,那么需要把使用共享状态控制在最低限度。
当我还是编程初学者的时候,我没有意识到我们所定义的每一个变量都是一个共享状态。变量当中包含了数据,并且可以被该变量所处的域内所有元素改变。域的范围越大,那么这个共享状态的范围就越广。尽量把新变量声明维持在一个小范围内,并确保它们不会向上渗透。
情况比较严重的问题就是当共享状态生效、多个源头都会导致同一个事件循环标记发生改变时(在事件循环环境中),会发生争用条件。
事实是:新手有可能会采取计时器作为共享状态争用条件的曲线救国之道,特别是当他们需要处理数据锁定的问题时。
这是在立flag,别这样做。切记,处处留心,并且在代码审查时指出这个问题,绝对不要接受这种情况。
24. 不正确地面对错误
错误是一个好东西,它们的存在意味着进步,意味着你更容易获得成长。
编程大牛们对错误爱不释手,而新手则恨之入骨。
如果看着这些可爱的小小红色错误信息,会让你觉得心烦,那么你需要改变一下态度,把它们视为助手。你需要好好对待它们,并充分发挥它们的作用,促进自己的成长。
有些错误需要升级至异常情况。异常情况是需要你给出解决方法的用户自定义错误。有些错误需要单独进行处理,它们的存在将会让程序崩溃,并且强制退出。
25. 从不休息
程序员也是人类,你的大脑、你的身体都需要休息。常常,当你进入编程状态时,就忘记了休息。我把这一点也视为新手的一个标志。这不是你可以妥协的点。把一些能够强制你休息的内容整合到你的工作流中,然后短暂地休息一下。
离开椅子,在附近走走,同时想想下面需要做的事情。当你回到代码的世界时,就可以用全新的视角看待你的成果。
这篇文章很长,现在你可以休息一下了。
原文链接:
https://medium.com/@samerbuna/the-mistakes-i-made-as-a-beginner-programmer-ac8b3e54c312
【本文是51CTO专栏机构大数据文摘的原创译文,微信公众号“大数据文摘( id: BigDataDigest)”】