1.背景
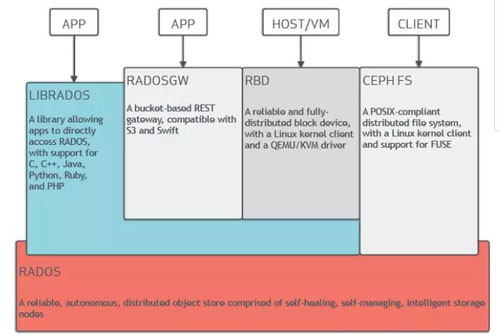
毫无疑问,乘着云计算发展的东风,Ceph已经是当今最火热的软件定义存储开源项目。如下图所示,它在同一底层平台之上可以对外提供三种存储接口,分别是文件存储、对象存储以及块存储,本文主要关注的是对象存储即radosgw。
基于Ceph可方便快捷地搭建安全性好、可用性高、扩展性好的私有化存储平台。私有化存储平台虽然以其安全性的优势受到越来越多的关注,但私有化存储平台也存在诸多弊端。 例如在如下场景中,某跨国公司需要在国外访问本地的业务数据,我们该如何支持这种远距离的数据访问需求呢。如果仅仅是在私有化环境下,无非以下两种解决方案:
- 直接跨地域去访问本地数据中心中的数据,毫无疑问,这种解决方案会带来较高的访问延迟

在国外自建数据中心,不断将本地的数据异步复制到远程数据中心,这种解决方案的缺点是成本太高
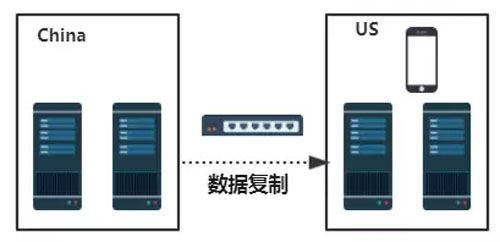
在这种场景下,单纯的私有云存储平台并不能很好的解决的上面的问题。但是,通过采用混合云解决方案却能较好地满足上述需求。对于前文所述远距离数据访问的场景,我们完全能借助公有云在远程的数据中心节点作为存储点,将本地数据中心的数据异步复制到公有云,再通过终端直接访问公有云中的数据,这种方式在综合成本和快捷性方面具备较大优势,适合这种远距离的数据访问需求。
2.发展现状:RGW Cloud Sync发展历程
基于Ceph对象存储的混合云机制是对Ceph生态的良好补充, 基于此,社区将在Mimic这个版本上发布RGW Cloud Sync特性,初步支持将RGW中的数据导出到支持s3协议的公有云对象存储平台,比如我们测试中使用的腾讯云COS,同Mulsite中的其他插件一样,RGW Cloud Sync这个特性也是做成了一个全新的同步插件(目前称之为aws sync module),能兼容支持S3协议。RGW Cloud Sync特性的整体发展历程如下:
- Suse公司贡献了初始版本,这个版本仅支持简单上传
- Red Hat在这个初始版本之上实现了完整语义的支持,比如multipart上传、删除等,考虑到同步大文件的时候可能会造成内存爆炸的问题,还实现了流式上传
对于Ceph社区即将在M版本发布的这个公有云同步特性,进行了实际落地测试使用,并根据其中存在的问题进行了反馈及开发。在实际测试过程中,我们搭建了如下所示的运行环境:
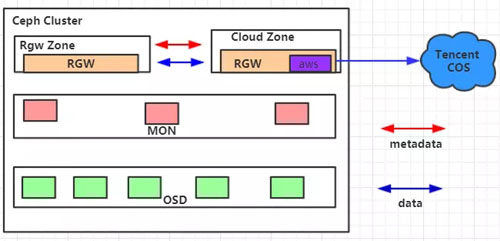
其中,Cloud Zone内部包含一个公有云同步插件,它被配置为只读zone,用以将Rgw Zone中写入的数据跨地域同步至腾讯云公有云对象存储平台COS之上。顺利实现将数据从RGW中同步备份至公有云平台,并且支持自由定制来实现将数据导入至不同云端路径,同时我们还完善了同步状态显示功能,能较快监测到同步过程中发生的错误以及当前落后的数据等。
3.核心机制
Multisite
RGW Cloud Sync这个特性本质上是基于Multisite之上的一个全新的同步插件(aws sync module)。首先来看Multisite的一些核心机制。Multisite是RGW中数据远程备份的一种解决方案,本质上来说它是一种基于日志的异步复制策略,下图为一个Multisite的示意图。
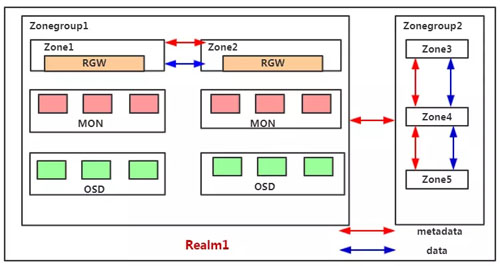
Multisite中主要有以下基本概念:
- Zone:存在于一个独立的Ceph集群,由一组rgw提供服务,对应一组后台的pool
- Zonegroup:包含至少一个Zone,Zone之间同步数据和元数据
- Realm:一个独立的命名空间,包含至少一个Zonegroup,Zonegroup之间同步元数据
下面来看Multisite中的一些工作机制,分别是Data Sync、Async Framework、Sync Plugin这三部分。其中Data Sync部分主要分析Multisite中的数据同步流程,Async Framework部分会介绍Multisite中的协程框架,Sync Plugin部分会介绍Multisite中的一些同步插件。
Data Sync
Data Sync用以将一个Zonegroup内的数据进行备份,一个Zone内写入的数据会最终同步到Zonegroup内所有Zone上,一个完整的Data Sync流程包含如下三步:
- Init:将远程的source zone与local zone建立日志分片对应关系,即将远程的datalog映射到本地,后续通过datalog就知道有没有数据需要更新
- Build Full Sync Map:获取远程bucket的元信息并建立映射关系来记录bucket的同步状态,如果配置multisite的时候source zone是没有数据的,则这步会直接跳过
- Data Sync:开始object数据的同步,通过RGW api来获取source zone的datalog并消费对应的bilog来同步数据
下面以一个bucket中数据的增量同步来阐述Data Sync的工作机制。了解RGW的人都应该知道,一个bucket实例至少包含一个bucket shard,Data Sync是以bucket shard为单位来同步的,每个bucket shard有一个datalog shard 及bilog shard与之对应。
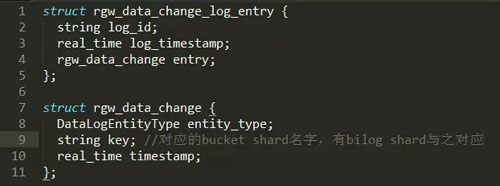
在建立完对应关系及进行完全量同步之后,本地Zone会记录Sourcezone每个datalog 分片对应的sync_marker。此后local zone会定期将sync_marker与远程datalog的max_marker比对,若仍有数据未同步,则通过rgw消费datalog entry,datalog entry中记录了对应的bucket shard,消费bucket shard对应的bilog则可进行数据同步。如下面这个图所示,远程的datalog是以 gw_data_chang_log_entry这样一种格式来存储日志的,我们可发现,每条datalog entry中包含rgw_data_change这样一个域,而rgw_data_change中包括的key这个域则是bucket shard的名字,之后就可以找到与之对应的bilog shard,从而消费bilog来进行增量同步。而全量同步其实就是没有开始这个sync_marker,直接从头开始消费datalog来进行数据同步。
Async Framework
RGW中使用的异步执行框架是基于boost::asio::coroutine这个库来开发的,它是一个stackless coroutine,和常见的协程技术不同,Async Framework没有使用ucontext技术来保存当前堆栈信息来支持协程,而是使用宏的技巧来达到类似效果,它通过 reenter/yield/fork 几个伪关键字(宏)来实现协程。 RGWCoroutine是RGW中定义的关于协程的抽象类,它本身也是boost::asio::coroutine 的子类,它是用于描述一个任务流的,包含一个待实现的隐式状态机。RGWCoroutine可以call其他RGWCoroutine,也可以spawn一个并行的RGWCoroutine。
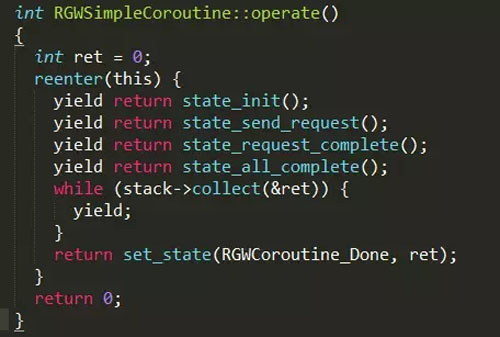
RGWCoroutine 类会包含一个 RGWCoroutinesStack成员,使用call调用其他RGWCoroutine的时候会将其对应的任务流都存储在堆栈上,直到所有任务流完成之后控制权才会回到调用者处。然而,spawn一个新的RGWCoroutine时候会生成一个新的任务栈来存储任务流,它不会阻塞当前正在执行的任务流。当一个协程需要执行一个异步IO操作的时候,它会标记自身为阻塞状态,而这个IO事件会在任务管理器处注册,一旦IO完成后任务管理器会解锁当前堆栈,从而恢复这个协程的控制。下图为一个简单的协程使用例子,实现了一个有预定周期的请求处理器。
Sync Plugin
前文所述的数据同步过程是将数据从一个ceph zone同步到另一ceph zone,我们完全可以将过程抽象出来,使数据同步变得更加通用,方便添加不同的sync module来实现将数据迁移到不同的目的地。因为上层消费datalog的逻辑都是一致的,只有***一步上层数据到目的地这步是不一样的,因此我们只需实现数据同步和删除的相关接口就可实现不同的同步插件,每个插件在RGW中都被称为一个sync module,目前Ceph中有以下四个sync module:
- rgw:默认sync module,用以在ceph zone之间同步数据
- log:用于获取object的扩展属性并进行打印
- elasticsearch:用于将数据的元信息同步至ES以支持一些搜索请求
- aws:Mimic版本发布,用于导出RGW中的数据到支持S3协议的对象存储平台 4
RGW Cloud Sync
Streaming process
前文讲到Suse公司贡献了RGW Cloud Sync的初始版本,如下图所示,它的一个同步流程逻辑上来说主要分为三步,***通过aws sync module通过http connection将远程的object拉取过来装载至内存中,之后将这个object put到云端,之后云端会返回一个put result。
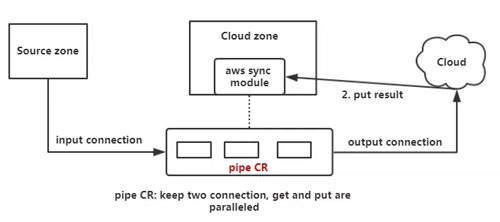
对于小文件来说,这个流程是没问题的,但是如果这个object比较大的情况,全部load到内存中就有问题了,因此Red Hat在此基础之上支持了Streaming process。本质上是使用了一个新的协程,这里称之为pipe CR,它采用类似管道的机制,同时保持两个http connection,一个用于拉取远程object,一个用于上传object,且这两个过程是并行的,这样可以有效防止内存爆炸,具体如下图所示。
Multipart upload
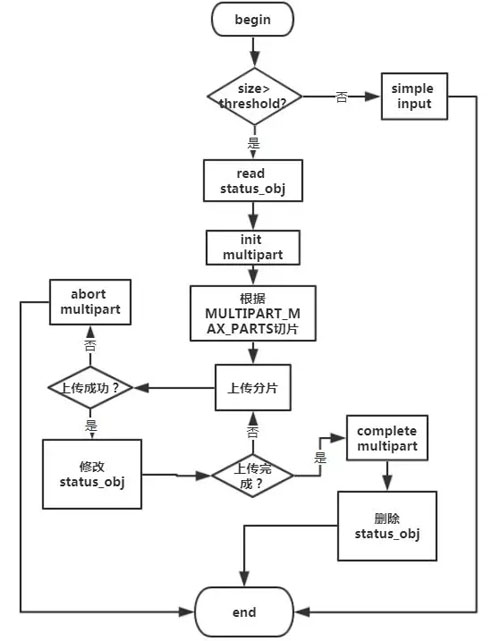
Multipart upload是在Streaming process基础之上用以支持大文件的分片上传。它的整体流程如下:
Json config
公有云存储环境相对来说比较复杂,需要更加复杂的配置来支持aws sync module的使用,因此Red Hat在这个插件上支持了json config。
相对其他插件来说主要增加了三个配置项,分别是host_style, acl_mapping,target_path,其中host_style是配置域名的使用格式,acl_mapping 是配置acl信息的同步方式,target_path是配置元数据在目的处的存放点。如下图所示为一个实际使用的配置,它表示配置了aws zone,采用path-style这种域名格式,target_path是rgw加其所在zonegroup的名字并加上它的user_id,之后是它的bucket名字,最终这个object在云端的路径就是target_path加上object名字。
5.关于RGW Cloud Sync方面的后续工作主要有以下四项:
- 同步状态显示的优化,比如显示落后的datalog、bucket、object等,同时将一些同步过程中发生的错误上报至Monitor
- 数据的反向同步,即支持将公有云的数据同步至RGW
- 支持将RGW的数据导入更多的公有云平台,而不是仅仅支持S3协议的平台
- 在此基础之上以RGW为桥梁来实现不同云平台之间的数据同步