人工智能(AI)已经成为新一轮产业变革的关键领域。麦肯锡今年6月发布的报告指出,以机器学习为主要实现方式的人工智能,有望在15-20年内成为世界所有主要经济体中主要产业的基础支撑方式,为人类带来14万亿的直接经济效益。
计算资源的运维困扰
UCloud的这位用户是人工智能领域的一家数据分析公司,研发总部位于北京,主要服务对象为东欧等亚欧板块国家,通过算法模型,可快速将不同场景或大量数据整合、分析,并输出可视化的分析图,从而帮助客户找到所需答案。
该公司所有的数据源都来自最终客户,但为了验证模型的准确性和通用性,依旧需要使用自己收集的公共数据来训练一个通用的模型。而对于一家几乎都是由数据科学家组成的公司来说,管理和维护所需要的计算资源是一个巨大的问题。
UAI-Train的充足计算能力
最近,UCloud发布了UAI-Train在线训练产品,解决包括代码管理、运行环境维护、GPU管理维护、数据管理等模型训练过程中的每个环节,提供一站式PaaS解决方案。
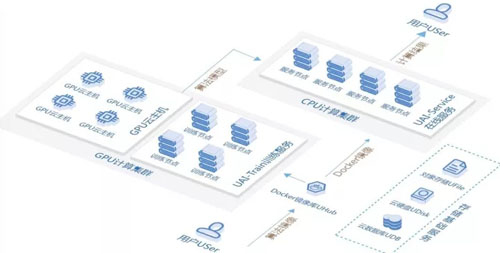
(图:UAI-Train 产品架构图)
UAI-Train是面向AI训练任务的大规模分布式计算平台,基于UCloud性能强大的GPU云主机集群构建,为AI训练任务提供充足的计算能力。该平台提供一站式训练任务托管服务,自动实现计算节点调度、训练环境准备、数据上传下载以及任务容灾。
AI训练服务按照实际计算消耗付费,普遍适用于常见的AI模型训练场景,如图像识别、自然语言处理、语音识别等。
使用后的意外收获
该公司近期在UCloud平台上运行的是地点分类的训练任务,共计12个城市,总训练图片量在十万张左右,测试图片在2000张,总计30G的图片数据集,用inceptionv3网络进行训练。
(UAI-Train模型训练场景:通过照片识别所在城市)
本次训练***epoch是50,在15个epochs左右发生了early stop。UAI-Train使用了4张Nvidia P40 GPU资源,总计训练耗时在5小时10分钟;对比原来使用6台CPU资源,训练速度大概是之前的12倍。
UCloud打造全新计算资源租赁模式
UCloud的AI训练服务是一种全新的计算资源租赁模式,用户无须购买或租赁昂贵的虚拟GPU服务器,只需要提供Docker镜像和训练数据,UAI-Train能够自动为其训练任务创建运行环境(Docker容器),并调用GPU计算资源为用户提供高性能计算服务。
用户能够以低廉的价格,按需使用GPU计算资源,甚至无需担心因训练超时或忘记关停而浪费租金。在训练的同时,UAI-Train可以通过TensorBoard或控制台日志的方式监控训练过程。事实上,以Docker容器方式部署的UAI-Train服务可以使用任何用户熟悉的编程语言和框架进行建模。