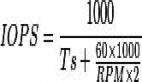记得在网上曾经看到过这么一句话:
明天和意外不知道哪一个先来,在天灾面前我们都很渺小。
假如把这句话与运维工作关联起来,多数的意外,也许不是天灾,而是人祸。
今天分享的就是在主备机房迁移后,由于在虚拟化上缺乏经验,外加跨团队间的沟通盲区,最终引爆了一场分布式缓存的性能悲剧。
- 01. 故障发生 -
在机房切换后的第一个工作日,无论是APP端,还是PC端,所有用户均出现登录、开户、交易缓慢的现象,甚至有部分用户直接收到错误码返回。
在未能实现 “理论完美型” 监控体系之前,任何一个分布式系统的故障定位都是相当费力而复杂的,由于系统是分布化的,故障也是分布化的,尤其是基础共享服务,一旦引爆,将一触即溃。
言归正传,在人肉运维与半自动工具的努力之下,最终确定了瓶颈点,下面通过简单的示意图进行展示。
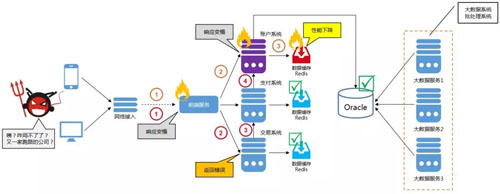
图1. 部分相关系统访问流程示意图
根据上面的示意图,引发故障的罪魁祸首是「账户系统的缓存切片发生 ‘莫名’ 的性能下降,导致产生了阻塞」。
账户系统,在整个系统链路中更为基础,所以一旦性能、稳定性下降,将引发多米诺骨牌式效应。
图中上链路:1、2、3点,直接影响开户、登录等业务场景。
图中下链路:1、2、3、4点,间接影响交易、支付等业务场景。
为在最短时间内恢复,我们采取了如下2个临时缓释手段。
暴力降级:将一部分的应用请求从Redis切到Oracle集群。
暴力限流:将一部分的网络接入进行拦截,从而减小对数据库造成的压力。
然而,在PaaS、容错及动态伸缩等机制都不完善的情况下,当出现类似故障时,除采取 “舍卒保车” 的暴力手段之外,也没有更立竿见影的方法。
- 02. 故障原因 -
简而言之,在故障发生之时,在懵逼的同时,我们的脑海中闪过一些猜测
网络问题:新机房带宽拥塞……是不是网络有问题?
硬件问题:交换机坏了? 虚拟机资源 “超卖”?
安全问题:被黑客攻击?DDoS?
架构问题:Redis、Sentinel、Proxy哪里又出BUG了?
随着这四个问题被陆续排除之后,我们又通过 “访问链路监控” 的分析功能进行排查,结果发现了蹊跷。
可能导致性能下降的原因。下图来自 ELK 的 日志分析。
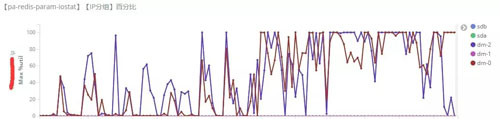
图2. 账户系统 - 某Redis节点的iostat情况
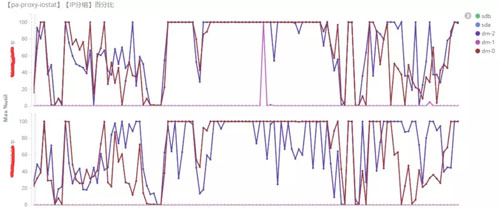
图3. 账户系统 - 某Proxy节点的iostat情况

图5. 账户系统 - 缓存链路的某时间段监控数据
跟着这条线索,再进入服务器进行查看。下图来自 Linux 的 命令行。
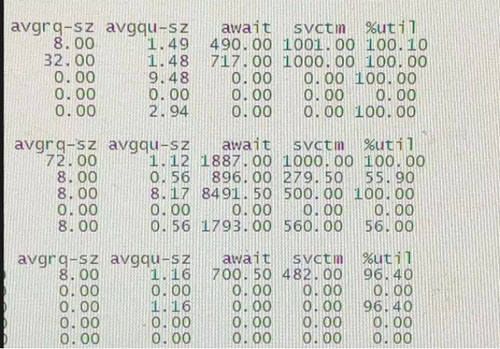
图6. 账户系统 - 某Redis节点的iostat命令结果
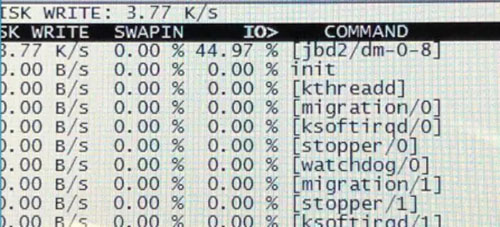
图7. 账户系统 - 某Redis节点I/O飙高时的异常进程
可以基本断定,导致缓存性能下降的“元凶”正是I/O,但在Redis未开启持久化功能项的前提下,原因主要可以归因为以下这些。
1、迁移机房时,磁盘管理模式有变动
原机房:缓存服务使用的是本地磁盘管理模式。
现机房:VSAN-池化共享数据存储,导致某些高I/O应用与缓存服务之间产生I/O交叉影响。
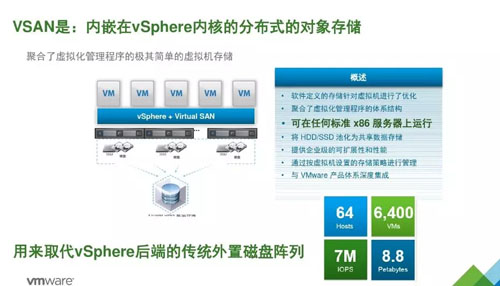
图8. 新机房采用VMWare vSphere 超融合虚拟化磁盘管理模式
2、迁移机房时,虚拟机部署方式有变动
原机房:缓存服务的虚拟机被部署在独立的硬件之上。
现机房:部分Redis与Proxy,与大数据服务的虚拟化节点部署在同一台物理机上,导致产生阶段性资源争抢。
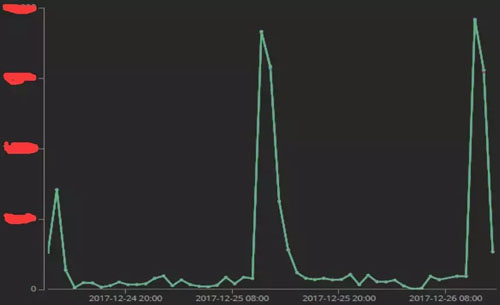
图9. 某虚拟化节点出现的CPU有规律的波动尖峰 - 分析图
根据上面的结论,为了快速解决,我们将账户系统的缓存切片迁移至被临时征调的N台实体机上,并将磁盘切换为本地模式,系统随之恢复正常。
- 03. 事后复盘 -
或许导致一个系统发生故障的因素有许多,除了软件设计,还有硬件部署,当然还包括有效的跨团队沟通。
所以,除了归因分析之外,利用复盘答疑的方式,对整个事件的过程进行了梳理,希望这种梳理能够帮助我们理清思路。
答疑1:为什么架构师在机房迁移前不知道虚拟机与磁盘的变动?
在好买,系统级设备,包括主机、操作系统、数据库、网络、安全以及外围设备,都归属于 “系统运维部” 管理。而中间件的架构设计、研发、运营以及运维部署,则属于 “平台架构部” 的管辖范畴。
基于职责范畴,跨部门沟通会发生 “屁股决定脑袋” 的情况。
架构师:虚拟机与磁盘不归我管,他们会保障的,应该了解我们的场景。
系统运维:这种变动提升了运维效率,也和你们说过了,你们没提出质疑。
再从另一个视角来看,在缺乏虚拟化基础架构(或超融合)实施经验的前提下,架构师也未必能在迁移之初就预判到这种变动会与类似故障产生有必然的关联性。
答疑2:为什么要使用超融合虚拟化的设备(或技术)?本地磁盘不好吗?
通过答疑1可以看出,为更高效的推动基础架构从 “物理化” 至 “虚拟化” 的演变,甚至为 “云化” 搭建通道,在不影响以Oracle为核心数据库的大前提下,采用 “低成本、高效率、保稳定” 的技术选型是一家金融企业优先要考虑的。
我们来看下 超融合虚拟化 - VSAN存储自动化 能带来哪些运维优势。

图10. 相比其他存储的优势
相比本次磁盘,基于 超融合虚拟化 - VSAN存储自动化 方式最大的优点在于其极短的分配与回收时间,并基于磁盘的备份和恢复要比本地磁盘方便得多。
对于分布式缓存这种场景而言,只能算是一种特殊要求。
- 小 结 -
好了,又到了讲大道理的时间了。相信通过这篇案例的分享,您应该已经明白了整个事件的始末原由,此时此刻,或许吐槽声、赞叹声、嘲笑声会游荡在不同人的心中,无论出于哪种目的,希望这篇分享能够给您带来一些帮助。