












paddle 简单介绍
paddle 是百度在2016年9月份开源的深度学习框架。
就我最近体验的感受来说的它具有几大优点:
1. 本身内嵌了许多和实际业务非常贴近的模型比如个性化推荐,情感分析,词向量,语义角色标注等模型还有更多实际已经内嵌了但是目前还没有出现在官方文档上的模型比如物体检测,文本生成,图像分类,ctr预估等等,可以快速应用到项目中去
2. 就实际体验来看,训练的速度相比于调用keras,在同等数据集上和相同网络架构上要快上不少。当然也是因为keras本身也是基于在tensorflow或者theano上面的,二次调用的速度不如paddle直接调用底层迅速。
缺点也有很多:
1. 一开始的安装对新手极其的不友好,使用docker安装感觉这个开源框架走不长久,所幸这个问题已经解决。
2. 目前很多的文档并不完善,也许百度系的工程师目前对这方面其实并不是很重视,新手教程看起来并非那么易懂。
3. 层的封装并不到位,很多神经网络层得自己去写,感觉非常的不方便。
***希望借由本文,可以让你快速上手paddle。
一分钟安装paddle
docker 安装
之前paddle的安装方式是使用docker安装,感觉非常的反人类。
安装命令:
- docker pull paddlepaddle/paddle:latest
pip 安装
现在已经支持pip 安装了。对(OS: centos 7, ubuntu 16.04, macos 10.12, python: python 2.7.x) 可以直接使用
- pip install paddlepaddle 安装cpu 版本。
- pip install paddlepaddle-gpu 安装gpu 版本。
安装完以后,测试的代码
- import paddle.v2 as paddle
- x = paddle.layer.data(name='x', type=paddle.data_type.dense_vector(13))
- y = paddle.layer.fc(input=x, size=1, param_attr=paddle.attr.Param(name="fc.w"))
- params = paddle.parameters.create(y)
- print params["fc.w"].shape
当输出 [13,1],那么恭喜你,已经成功安装了paddle.
遇到的问题
当我在使用pip 安装方式安装了gpu版本的paddle以后,遇到了numpy 版本不兼容的问题。解决的办法是:在把本地的numpy卸载以后,我首先把安装的paddle卸载了,然后重新再安装了一遍paddle。这样在安装的过程当中,可以借由paddle的安装过程来检测你系统的其他python包是否符合paddle需要的环境。其他类似的python包的问题,都可以借由这个办法帮忙解决。
使用paddle中的循环神经网络来生成文本
背景简介
首先paddle实际上已经内嵌了这个项目:
- https://github.com/PaddlePaddle/models/tree/develop/generate_sequence_by_rnn_lm
文本生成有很多的应用,比如根据上文生成下一个词,递归下去可以生成整个句子,段落,篇章。目前主流生成文本的方式是使用rnn来生成文本。
主要有两个原因:
1. 因为RNN 是将一个结构反复使用,即使输入的文本很长,所需的network的参数都是一样的。
2. 因为RNN 是共用一个结构的,共用参数的。可以用比较少的参数来训练模型。这样会比较难训练,但是一旦训练好以后,模型会比较难overfitting,效果也会比较好。
对于RNN使用的这个结构,由于原生的RNN的这个结构本身无法解决长程依赖的问题,目前主要使用Lstm 和GRU来进行代替。但是具体到LSTM 和GRU,因为LSTM需要使用三个门结构也就是通常所说的遗忘门,更新门,输出门。而GRU的表现和LSTM类似,却只需要两个门结构。训练速度更快,对内存的占用更小,目前看起来使用GRU是更好的选择。
项目实战
- 首先
到本地model 目录下
- git clone https://github.com/PaddlePaddle/models/tree/develop/generate_sequence_by_rnn_lm
- 代码结构如下
- .
- ├── data
- │ └── train_data_examples.txt # 示例数据,可参考示例数据的格式,提供自己的数据
- ├── config.py # 配置文件,包括data、train、infer相关配置
- ├── generate.py # 预测任务脚本,即生成文本
- ├── beam_search.py # beam search 算法实现
- ├── network_conf.py # 本例中涉及的各种网络结构均定义在此文件中,希望进一步修改模型结构,请修改此文件
- ├── reader.py # 读取数据接口
- ├── README.md
- ├── train.py # 训练任务脚本
- └── utils.py # 定义通用的函数,例如:构建字典、加载字典等
运行说明
- 首先执行python train.py 开始训练模型,待模型训练完毕以后。
- 执行python generate.py 开始运行文本生成代码。(默认的文本输入为data/train_data_example.txt,生成文本保存为data/gen_result.txt)
代码解析
- paddle 的使用有几个固定需要遵守的流程。
- 大致需要4步。1:初始化,2:定义网络结构,3:训练,4:预测。
- 其中定义网络结构具体需要定义 1:定义具体的网络结构,2:定义所需要的参数,3:定义优化的方法,4:定义event_handler 打印训练信息。
- 总体来说,paddle 的代码上手难度其实对新手挺大的,但思路非常的清晰,耐心阅读应该可以明白。下面我们具体介绍:
1. 首先需要加载paddle 进行初始化:
import paddle.v2 as paddle import numpy as np paddle.init(use_gpu=False)
2. 定义网络结构
- # 变量说明
- # vocab_dim: 输入变量的维度数.
- # type vocab_dim: int
- # emb_dim: embedding vector的维度数
- # type emb_dim: int
- # rnn_type: RNN cell的类型.
- # type rnn_type: int
- # hidden_size: hidden unit的个数.
- # type hidden_size: int
- # stacked_rnn_num: 堆叠的rnn cell的个数.
- # type stacked_rnn_num: int
- # 定义输入层
- input = paddle.layer.data(
- name="input", type=paddle.data_type.integer_value_sequence(vocab_dim))
- if not is_infer:
- target = paddle.layer.data(
- name="target",
- type=paddle.data_type.integer_value_sequence(vocab_dim))
- # 定义embedding层
- # 该层将上层的输出变量input 做为本层的输入灌入embedding层,将输入input 向量化,方便后续处理
- input_emb = paddle.layer.embedding(input=input, size=emb_dim)
- # 定义rnn层
- # 如果 rnn_type 是lstm,则堆叠lstm层
- # 如果rnn_type 是gru,则堆叠gru层
- # 如果 i = 0的话,先将 input_emb做为输入,其余时刻则将上一时刻的rnn_cell作为输入进行堆叠
- # stack_rnn_num 等于多少就堆叠多少个 rnn层
- if rnn_type == "lstm":
- for i in range(stacked_rnn_num):
- rnn_cell = paddle.networks.simple_lstm(
- input=rnn_cell if i else input_emb, size=hidden_size)
- elif rnn_type == "gru":
- for i in range(stacked_rnn_num):
- rnn_cell = paddle.networks.simple_gru(
- input=rnn_cell if i else input_emb, size=hidden_size)
- else:
- raise Exception("rnn_type error!")
- # 定义全联接层
- # 将上层最终定义得到的输出rnn_cell 做为输入灌入该全联接层
- output = paddle.layer.fc(
- input=[rnn_cell], size=vocab_dim, act=paddle.activation.Softmax())<br data-filtered="filtered">
- # ***一层cost中记录了神经网络的所有拓扑结构,通过组合不同的layer,我们即可完成神经网络的搭建。
- cost = paddle.layer.classification_cost(input=output, label=target)
paddle的网络结构从这里可以看出其实定义起来需要自己写非常多的代码,感觉非常的冗余,虽然同样也是搭建积木自上而下一层层来写,代码开发的工作量其实蛮大的。
3. 训练模型
在完成神经网络的搭建之后,我们首先需要根据神经网络结构来创建所需要优化的parameters(也就是网络结构的参数),并创建optimizer(求解网络结构参数的优化方法比如Sgd,Adam,Rmstrop)之后,我们可以创建trainer来对网络进行训练。在这里我们使用adam算法来作为我们优化的算法,L2正则项来作为正则项。并根据cost 中记录的网络拓扑结构来创建神经网络所需要的参数。
- # create optimizer
- adam_optimizer = paddle.optimizer.Adam(
- learning_rate=1e-3,
- regularization=paddle.optimizer.L2Regularization(rate=1e-3),
- model_average=paddle.optimizer.ModelAverage(
- average_window=0.5, max_average_window=10000))
- # create parameters
- parameters = paddle.parameters.create(cost)
- # create trainer
- trainer = paddle.trainer.SGD(
- cost=cost, parameters=parameters, update_equation=adam_optimizer)
其中,trainer接收三个参数,包括神经网络拓扑结构 cost、神经网络参数 parameters以及迭代方程 adam_optimizer。在搭建神经网络的过程中,我们仅仅对神经网络的输入进行了描述。而trainer需要读取训练数据进行训练,PaddlePaddle中通过reader来加载数据。
- # define reader
- reader_args = {
- "file_name": conf.train_file,
- "word_dict": word_dict,
- }
- # 读取训练数据
- train_reader = paddle.batch(
- paddle.reader.shuffle(
- reader.rnn_reader(**reader_args), buf_size=102400),
- batch_size=conf.batch_size)
- # 读取测试数据
- test_reader = None
- if os.path.exists(conf.test_file) and os.path.getsize(conf.test_file):
- test_reader = paddle.batch(
- paddle.reader.shuffle(
- reader.rnn_reader(**reader_args), buf_size=65536),
- batch_size=conf.batch_size)
最终我们可以调用trainer的train方法启动训练:
- # define the event_handler callback
- # event_handler 主要负责打印训练的进度信息,训练的损失值,这里可以自己定制
- def event_handler(event):
- if isinstance(event, paddle.event.EndIteration):
- if not event.batch_id % conf.log_period:
- logger.info("Pass %d, Batch %d, Cost %f, %s" % (
- event.pass_id, event.batch_id, event.cost, event.metrics))
- if (not event.batch_id %
- conf.save_period_by_batches) and event.batch_id:
- save_name = os.path.join(model_save_dir,
- "rnn_lm_pass_%05d_batch_%03d.tar.gz" %
- (event.pass_id, event.batch_id))
- with gzip.open(save_name, "w") as f:
- parameters.to_tar(f)
- if isinstance(event, paddle.event.EndPass):
- if test_reader is not None:
- result = trainer.test(reader=test_reader)
- logger.info("Test with Pass %d, %s" %
- (event.pass_id, result.metrics))
- save_name = os.path.join(model_save_dir, "rnn_lm_pass_%05d.tar.gz" %
- (event.pass_id))
- with gzip.open(save_name, "w") as f:
- parameters.to_tar(f)
- # 开始训练
- trainer.train(
- reader=train_reader, event_handler=event_handler, num_passes=num_passes)
至此,我们的训练代码定义结束,开始进行训练
- python train.py
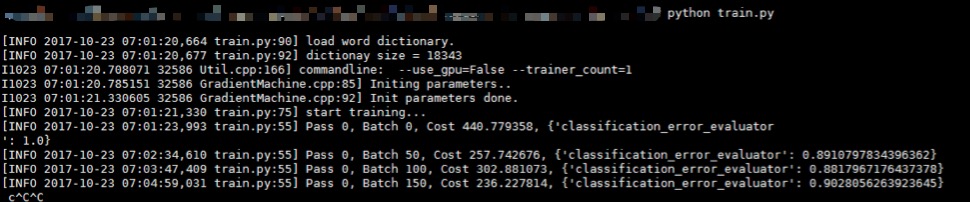
pass 相当于我们平常所使用的 epoch(即一次迭代), batch是我们每次训练加载的输入变量的个数,cost 是衡量我们的网络结构损失函数大小的具体值,越小越好,***一项 classification_error_evaluator 是表明我们目前的分类误差的损失率,也是越小越好。
4.生成文本
当等待若干时间以后,训练完毕以后。开始进行文本生成。
- python generate.py

生成文本展示
- 81 若隐若现 地像 幽灵 , 像 死神
- -12.2542 一样 。 他 是 个 怪物 <e>
- -12.6889 一样 。 他 是 个 英雄 <e>
- -13.9877 一样 。 他 是 我 的 敌人 <e>
- -14.2741 一样 。 他 是 我 的 <e>
- -14.6250 一样 。 他 是 我 的 朋友 <e>
其中:
- ***行
81 若隐若现 地像 幽灵 , 像 死神以\t为分隔,共有两列:- ***列是输入前缀在训练样本集中的序号。
- 第二列是输入的前缀。
- 第二 ~
beam_size + 1行是生成结果,同样以\t分隔为两列:- ***列是该生成序列的对数概率(log probability)。
- 第二列是生成的文本序列,正常的生成结果会以符号
<e>结尾,如果没有以<e>结尾,意味着超过了***序列长度,生成强制终止
总结:
我们这次说明了如何安装paddle。如何使用paddle开始一段项目。总体来说paddle 的文档目前是非常的不规范,阅读的体验也不是很好,需要开发者耐心细致的阅读源代码来掌握paddle的使用方法。第二很多层的封装感觉写法非常的冗余,比如一定要用paddle作为前缀,把python写出了java的感觉。但是瑕不掩瑜,从使用的角度来看,一旦掌握了其使用方法以后,自己定义网络结构感觉非常的方便。训练的速度也是挺快的。



























