paddlepaddle图像分类
很早之前,有写过关于TensorFlow, MXNet中如何训练一个靠谱的图像分类器,这里我会先使用paddlepaddle官方的例子,来学习下如何使用paddlepaddle构建一个靠谱的分类器。
数据介绍
官方文档上使用的数据是flowers-102,这个数据集早在当初tflearn学习深度学习网络的时候就有接触过,还是比较简单的,paddlepaddle把它写成数据接口
模型介绍
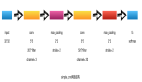
paddlepaddle的模型介绍model overview。这里我们在实验当中使用大名鼎鼎的resnet-50:
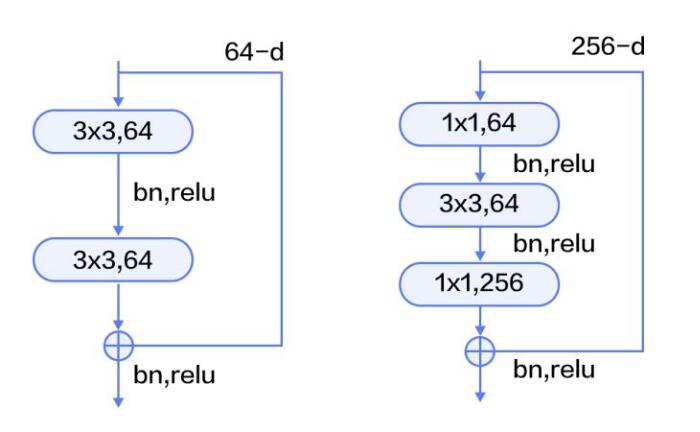
import paddle.v2 as paddle __all__ = ['resnet_imagenet', 'resnet_cifar10'] def conv_bn_layer(input, ch_out, filter_size, stride, padding, active_type=paddle.activation.Relu(), ch_in=None): tmp = paddle.layer.img_conv( input=input, filter_size=filter_size, num_channels=ch_in, num_filters=ch_out, stride=stride, padding=padding, act=paddle.activation.Linear(), bias_attr=False) return paddle.layer.batch_norm(input=tmp, act=active_type) def shortcut(input, ch_out, stride): if input.num_filters != ch_out: return conv_bn_layer(input, ch_out, 1, stride, 0, paddle.activation.Linear()) else: return input def basicblock(input, ch_out, stride): short = shortcut(input, ch_out, stride) conv1 = conv_bn_layer(input, ch_out, 3, stride, 1) conv2 = conv_bn_layer(conv1, ch_out, 3, 1, 1, paddle.activation.Linear()) return paddle.layer.addto( input=[short, conv2], act=paddle.activation.Relu()) def bottleneck(input, ch_out, stride): short = shortcut(input, ch_out * 4, stride) conv1 = conv_bn_layer(input, ch_out, 1, stride, 0) conv2 = conv_bn_layer(conv1, ch_out, 3, 1, 1) conv3 = conv_bn_layer(conv2, ch_out * 4, 1, 1, 0, paddle.activation.Linear()) return paddle.layer.addto( input=[short, conv3], act=paddle.activation.Relu()) def layer_warp(block_func, input, ch_out, count, stride): conv = block_func(input, ch_out, stride) for i in range(1, count): conv = block_func(conv, ch_out, 1) return conv def resnet_imagenet(input, class_dim, depth=50): cfg = { 18: ([2, 2, 2, 1], basicblock), 34: ([3, 4, 6, 3], basicblock), 50: ([3, 4, 6, 3], bottleneck), 101: ([3, 4, 23, 3], bottleneck), 152: ([3, 8, 36, 3], bottleneck) } stages, block_func = cfg[depth] conv1 = conv_bn_layer( input, ch_in=3, ch_out=64, filter_size=7, stride=2, padding=3) pool1 = paddle.layer.img_pool(input=conv1, pool_size=3, stride=2) res1 = layer_warp(block_func, pool1, 64, stages[0], 1) res2 = layer_warp(block_func, res1, 128, stages[1], 2) res3 = layer_warp(block_func, res2, 256, stages[2], 2) res4 = layer_warp(block_func, res3, 512, stages[3], 2) pool2 = paddle.layer.img_pool( input=res4, pool_size=7, stride=1, pool_type=paddle.pooling.Avg()) out = paddle.layer.fc(input=pool2, size=class_dim, act=paddle.activation.Softmax()) return out def resnet_cifar10(input, class_dim, depth=32): # depth should be one of 20, 32, 44, 56, 110, 1202 assert (depth - 2) % 6 == 0 n = (depth - 2) / 6 nStages = {16, 64, 128} conv1 = conv_bn_layer( input, ch_in=3, ch_out=16, filter_size=3, stride=1, padding=1) res1 = layer_warp(basicblock, conv1, 16, n, 1) res2 = layer_warp(basicblock, res1, 32, n, 2) res3 = layer_warp(basicblock, res2, 64, n, 2) pool = paddle.layer.img_pool( input=res3, pool_size=8, stride=1, pool_type=paddle.pooling.Avg()) out = paddle.layer.fc(input=pool, size=class_dim, act=paddle.activation.Softmax()) return out - 1.
运行
进入对应目录后
python train.py resnet - 1.
即可完成
但是事实上其实不是这样的,paddlepaddle安装whl和tensorflow一样,gpu版本都会对应不同的cuda和cudnn,经常会出一些配置问题,所以直接在系统中安装其实是一个不好的选择,所以***是不要选择直接安装,而是使用nvidia-docker,同理在tensorflow,mxnet中,感觉nvidia-docker也是很好的。
nvidia-docker安装
- 安装cuda、cudnn,***的;
- 根据系统选择对应版本的docker;
- 安装nvidia-docker:
docker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f sudo apt-get purge -y nvidia-docker docker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f sudo apt-get purge -y nvidia-docker curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - curl -s -L https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update sudo apt-get install -y nvidia-docker2 sudo pkill -SIGHUP dockerd - 1.
- 拉paddlepaddle镜像
docker pull paddlepaddle/paddle:latest-gpu - 进入docker,
nvidia-docker run -it -v $PWD:/work -v /data:/data paddlepaddle/paddle:latest-gpu /bin/bash。这里稍微注意下,paddlepaddle的官方镜像源里面缺少一些必须的包,比如opencv,好像有点问题,还有vim啥的也都没有装,这里为了运行***把这些环境一次性都解决,然后docker commit,保存对镜像的修改。
基本这样,你就可以在本机上有一个完全干净的docker环境,你就可以随便折腾啦。这里如果有运行不起来的问题,可在下方评论,我具体也不记得缺哪些东西,不过都很好解决的
docker中运行
这里我运行过很长时间的一个demo,但是因为没有保存好信息,被覆盖了,所以只能暂时演示一下。
使用自己的数据集来训练模型
实验完官方的flower-102之后,我们这里使用自己的数据集来训练模型,数据集是之前收集到的鉴黄数据,数据集主要包括三类:porn\sexy\normal,大概有500w张左右。 首先,我们需要生成如下格式,格式为图像路径+"\t"+label,其中label为0表示normal,1表示sexy,2表示porn。 生成脚本如下:
import random import os import codecs import sys def gen_datalist(data_dir, class_label, data_type="train", shuffle=True, suffix_list=["jpg", "jpeg", "JPEG", "jpg"]): all_files = [] for root, dirs, files in os.walk(data_dir): print "processing {0}".format(root) for file_name in files: file_name = os.path.join(root, file_name) suffix = file_name.split(".")[-1] if suffix in suffix_list: all_files.append(file_name) if shuffle: print "shuffle now" random.shuffle(all_files) print "begin to write to {0}".format(data_type+"_"+class_label+".lst") with codecs.open(data_type+"_"+class_label+".lst", "w", encoding="utf8") as fwrite: for each_file in all_files: fwrite.write(each_file+"\t"+class_label+"\n") if __name__ == "__main__": argv = sys.argv data_dir = argv[1] class_label = argv[2] gen_datalist(data_dir, class_label) - 1.
有了脚本运行之后,发现了一些cv2库中none 没有shape的问题,调试之后发现,原来收集的数据中,有部分大小为0或者很小的图像,这部分应该是有问题的数据,写了个滤除脚本,删除这些数据之后就妥了
from paddle.v2.image import load_and_transform import paddle.v2 as paddle def filter_imgs(file_path = "train.lst", write_file = "valid_train.lst"): fwrite = open(write_file, "w") with open(file_path, 'r') as fread: error=0 for line in fread.readlines(): img_path = line.strip().split("\t")[0] try: img = paddle.image.load_image(img_path) img = paddle.image.simple_transform(img, 256, 224, True) fwrite.write(line) except: error += 1 print error filter_imgs() - 1.
从头开始训练模型
在paddlepaddle中训练模型
image = paddle.layer.data( name="image", type=paddle.data_type.dense_vector(DATA_DIM)) conv, pool, out = resnet.resnet_imagenet(image, class_dim=CLASS_DIM) cost = paddle.layer.classification_cost(input=out, label=lbl) parameters = paddle.parameters.create(cost) optimizer = paddle.optimizer.Momentum( momentum=0.9, regularization=paddle.optimizer.L2Regularization(rate=0.0005 * BATCH_SIZE), learning_rate=learning_rate / BATCH_SIZE, learning_rate_decay_a=0.1, learning_rate_decay_b=128000 * 35, learning_rate_schedule="discexp", ) train_reader = paddle.batch( paddle.reader.shuffle( # flowers.train(), # To use other data, replace the above line with: reader.train_reader('valid_train0.lst'), buf_size=1000), batch_size=BATCH_SIZE) def event_handler(event): if isinstance(event, paddle.event.EndIteration): if event.batch_id % 1 == 0: print "\nPass %d, Batch %d, Cost %f, %s" % ( event.pass_id, event.batch_id, event.cost, event.metrics) if isinstance(event, paddle.event.EndPass): with gzip.open('params_pass_%d.tar.gz' % event.pass_id, 'w') as f: trainer.save_parameter_to_tar(f) result = trainer.test(reader=test_reader) print "\nTest with Pass %d, %s" % (event.pass_id, result.metrics) trainer.train( reader=train_reader, num_passes=200, event_handler=event_handler) - 1.
- 需要配置resnet网络,确定好input和out,配置cost函数,构建parameter;
- 构建optimizer,使用momentum的sgd;
- 构建reader,设置训练数据读取,配置上文提到的图片路径\tlabel的文件;
- event_handler是用来记录batch_id\pass的事件处理函数,传入train函数,训练过程中会完成相应工作;
pretrain model + finetuning
resnet官方提供一个在imagenet上训练好的pretrained model,运行model_download.sh。
sh model_download.sh ResNet50 - 1.
会下载Paddle_ResNet50.tar.gz, 这个文件是paddlepaddle在ImageNet上训练的模型文件,我们这里使用这个文件的参数做初始化,我们需要在代码,参数初始化的时候,使用这里的参数,修改代码如下:
if args.retrain_file is not None and ''!=args.retrain_file: print("restore parameters from {0}".format(args.retrain_file)) exclude_params = [param for param in parameters.names() if param.startswith('___fc_layer_0__')] parameters.init_from_tar(gzip.open(args.retrain_file), exclude_params) - 1.
首先,我们需要指定init_from_tar的参数文件为Paddle_ResNet50.tar.gz, 大家知道ImageNet是在1000类上的一个模型,它的输出为1000个节点,所以我们这里需要稍作修改,我们增加一个exclud_params,指定***一层___fc_layer_0__的参数,不要从文件当中初始化.
pretrain model + freeze layers + finetuning
查了文档和代码知道,只需要在某层增加is_static=True,就可以freeze掉该层的参数,使该层参数不更新,但是我在使用这部分时遇到了bug,提了issue (core dumped with is_static=True)[https://github.com/PaddlePaddle/Paddle/issues/8355],出现core的问题,无法正常使用,后面能够搞定了,再更新这部分内容。
代码改进
examples里面的代码reader部分在处理data.lst时,太过粗糙,没有考虑到数据如果出现一些问题时,训练代码会直接挂掉,这部分的代码至少要保证足够的鲁棒性
def train_reader(train_list, buffered_size=1024): def reader(): with open(train_list, 'r') as f: lines = [line.strip() for line in f] for line in lines: try: img_path, lab = line.strip().split('\t') yield img_path, int(lab) except: print "record in {0} get error".format(train_list) continue return paddle.reader.xmap_readers(train_mapper, reader, cpu_count(), buffered_size) - 1.
visualDL实践
可视化acc\loss
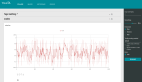
之前有在小的demo上体验过visualDL,在比较大的数据训练过程上没试验过,这次鉴黄数据上测试,打印出loss和acc看看,当小数量的step的时候,看起来是没有问题的 。
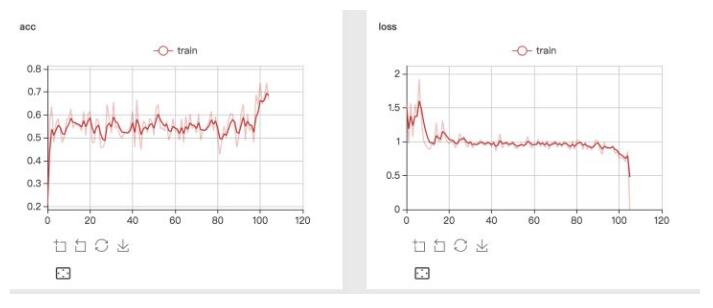
但是但step较大的时候,acc打印不出来了,同样的代码,出错信息也看不出来,各种莫名的报错,看样子和使用的代码没有什么关系,应该是visualDL本身的容错做的不够。
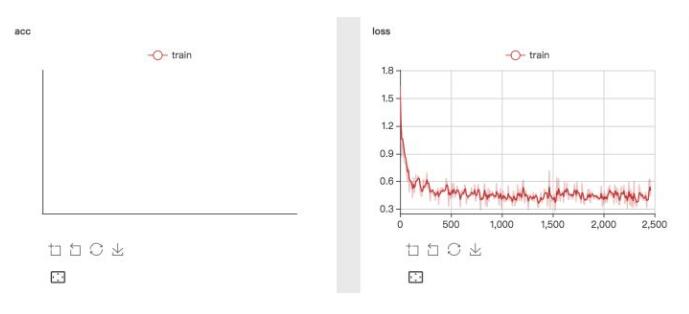
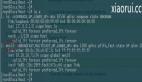
出错提示:

这部分和之前提过的一个issue很类似: Unexpected error: <type 'exceptions.RuntimeError'> 因为信息量不够,其实很难自己这边做问题分析,希望visualDL把这块容错做好一些。
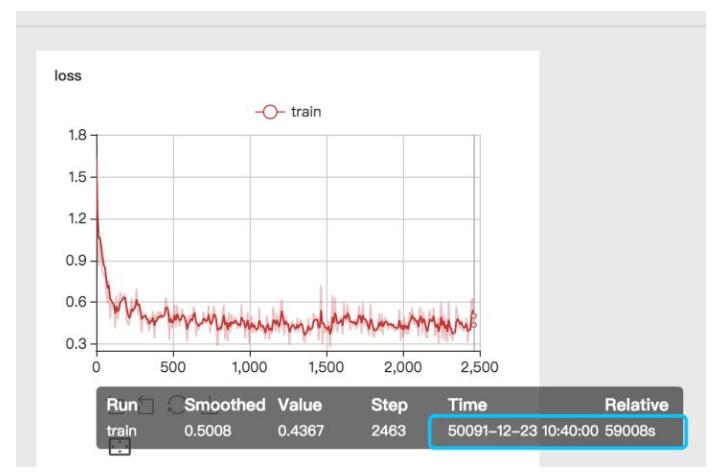
这块时间应该有些问题,我也不知道,我总觉的有点问题 是我用的姿势不对吗 ?
可视化graph
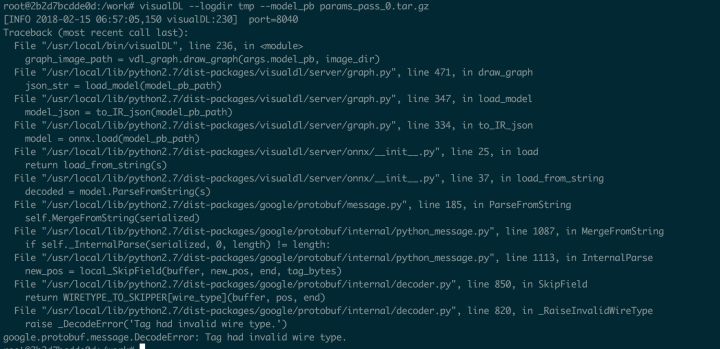
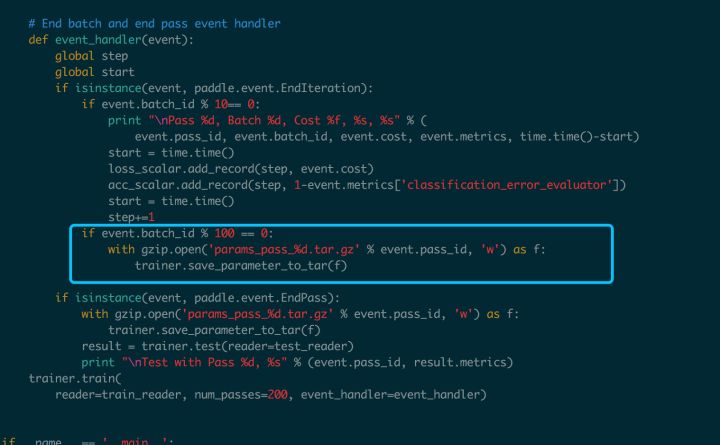
使用有问题,使用paddlepaddle保存好的模型指定给model_pb 出现如下问题, 看了repo中的这部分的demo都是直接curl下来一个model.pb的文件,然后可视化,没有找到能直接导出paddlepaddle保存模型的导入到visualdl中, 可能是我的使用方式有问题, 保存模型方式如下图:
莫非需要先把paddlepaddle模型转换为onnx格式?
可视化image
有问题,暂时没有测试,之后更新后同步
总结
paddlepaddle现在在dl这块还只是刚开始,example里面的demo和tensorflow最开始一样,并不能完全hold住实际业务需求,当初tensorflow的时候也有种种的问题,后来经过社区的帮助,到现在很多源码几乎都是开箱即用,paddlepaddle现在可能在文档与demo上还是0.7版本的tensorflow,不过希望能更加努力,毕竟作为同行,在参与了一些分布式dl模型的工作之后,深知其中的艰辛。visualdl相当棒的工具,支持onnx的模型可视化,虽然在测试过程中感觉有些瑕疵,但是十分支持,希望能快速发展,个人也在阅读这部分源码学习, histogram的相关功能没有测试,挺有用的 尤其在训练跑偏的时候可以快速可视化参数的分布。***,强烈希望visualdl能把文档弄的更友好一些,加油。
另外,大年三十,祝大家新年快乐,狗年跑模型妥妥的收敛