本文主要讲了神经进化是深度学习的未来,以及如何用进化计算方法(EC)优化深度学习(DL)。
过去几年时间里,我们有一个完整的团队致力于人工智能研究和实验。该团队专注于开发新的进化计算方法(EC),包括设计人工神经网络架构、构建商业应用程序,以及使用由自然进化激发的方法来解决具有挑战性的计算问题。这一领域的发展势头非常强劲。我们相信进化计算很可能是人工智能技术的下一个重大课题。
EC与Deep Learning(DL)一样都是几十年前引入的,EC也能够从可用的计算和大数据中得到提升。然而,它解决了一个截然不同的需求:我们都知道DL侧重于建模我们已知的知识,而EC则专注于创建新的知识。从这个意义上讲,它是DL的下个步骤:DL能够在熟悉的类别中识别对象和语音,而EC使我们能够发现全新的对象和行为-最大化特定目标的对象和行为。因此,EC使许多新的应用成为可能:为机器人和虚拟代理设计更有效的行为,创造更有效和更廉价的卫生干预措施,促进农业机械化发展和生物过程。
前不久,我们发布了5篇论文来报告在这一领域上取得了显著的进展,报告主要集中在三个方面:(1)DL架构在三个标准机器学习基准测试中已达到了最新技术水平。(2)开发技术用于提高实际应用发展的性能和可靠性。(3)在非常困难的计算问题上证明了进化问题的解决。
本文将重点介绍里面的第一个领域,即用EC优化DL架构。
Sentient揭示了神经进化的突破性研究
深度学习的大部分取决于网络的规模和复杂性。随着神经进化,DL体系结构(即网络拓扑、模块和超参数)可以在人类能力之外进行优化。我们将在本文中介绍三个示例:Omni Draw、Celeb Match和Music Maker(语言建模)。在这三个例子中,Sentient使用神经进化成功地超越了最先进的DL基准。
音乐制作(语言建模)
在语言建模领域,系统被训练用来预测“语言库”中的下一个单词,例如《华尔街日报》几年内的大量文本集合,在网络做出预测结果后,这个输入还可以被循环输入,从而网络可以生成一个完整的单词序列。有趣的是,同样的技术同样适用于音乐序列,以下为一个演示。用户输入一些初始音符,然后系统根据该起始点即兴创作一首完整的旋律。通过神经元进化,Sentient优化了门控周期性(长期短期记忆或LSTM)节点(即网络的“记忆”结构)的设计,使模型在预测下一个音符时更加准确。
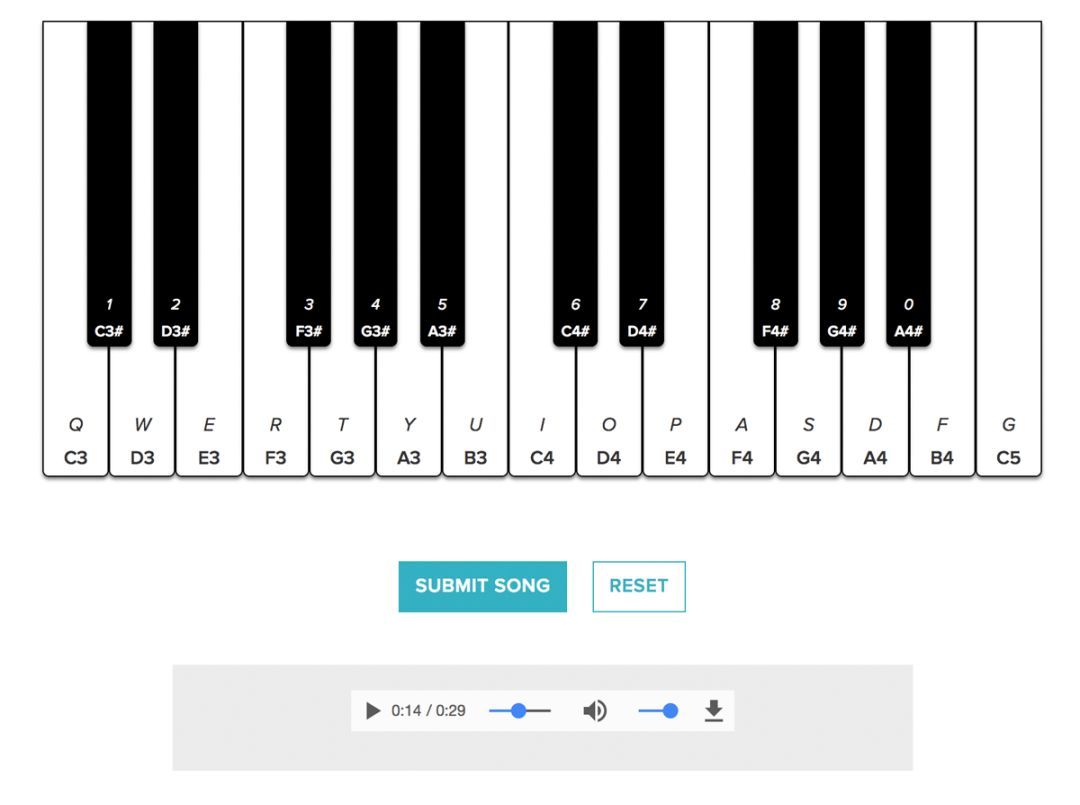
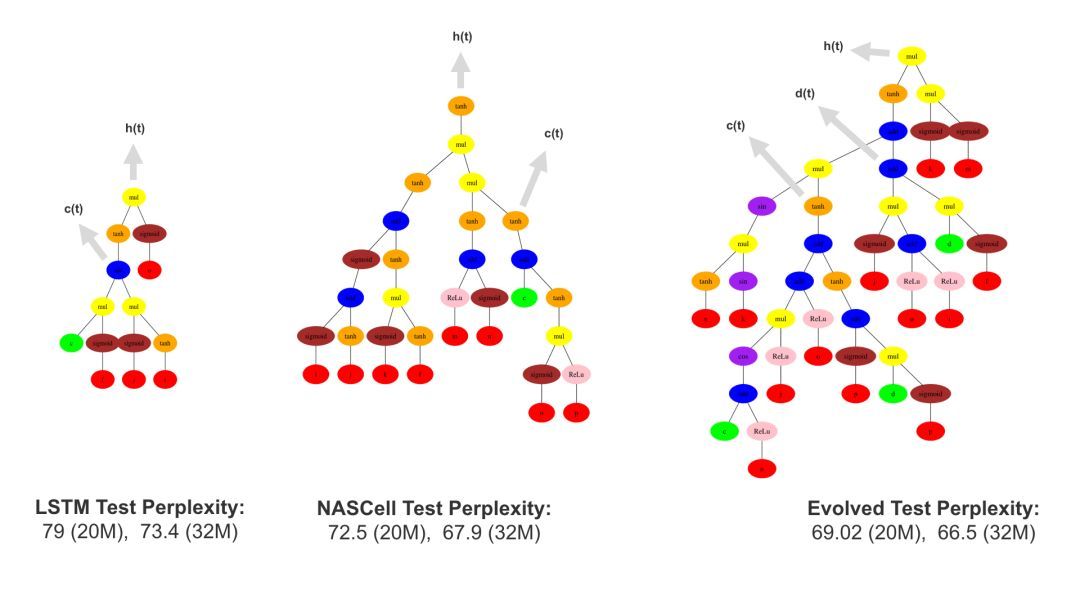
在语言建模领域(在一个叫Penn Tree Bank的语言语料库中预测下一个词),基准是由困惑点定义的,用来度量概率模型如何预测真实样本。当然,数字越低越好,因为我们希望模型在预测下一个单词时“困惑”越少越好。在这种情况下,感知器以10.8的困惑点击败了标准的LSTM结构。值得注意的是,在过去25年内,尽管人类设计了一些LSTM变体,LSTM的性能仍然没有得到改善。事实上,我们的神经进化实验表明,LSTM可以通过增加复杂性,即记忆细胞和更多的非线性、平行的途径来显著改善性能。
为什么这个突破很重要?语言是人类强大而复杂的智能构造。语言建模,即预测文本中的下一个单词,是衡量机器学习方法如何学习语言结构的基准。因此,它是构建自然语言处理系统的代理,包括语音和语言接口、机器翻译,甚至包括DNA序列和心率诊断等医学数据。而在语言建模基准测试中我们可以做得更好,可以使用相同的技术建立更好的语言处理系统。
Omni Draw
Omniglot是一种可以识别50种不同字母字符的手写字符识别基准,包括像西里尔语(书面俄语)、日语和希伯来语等真实语言,以及诸如Tengwar(《指环王》中的书面语言)等人工语音。
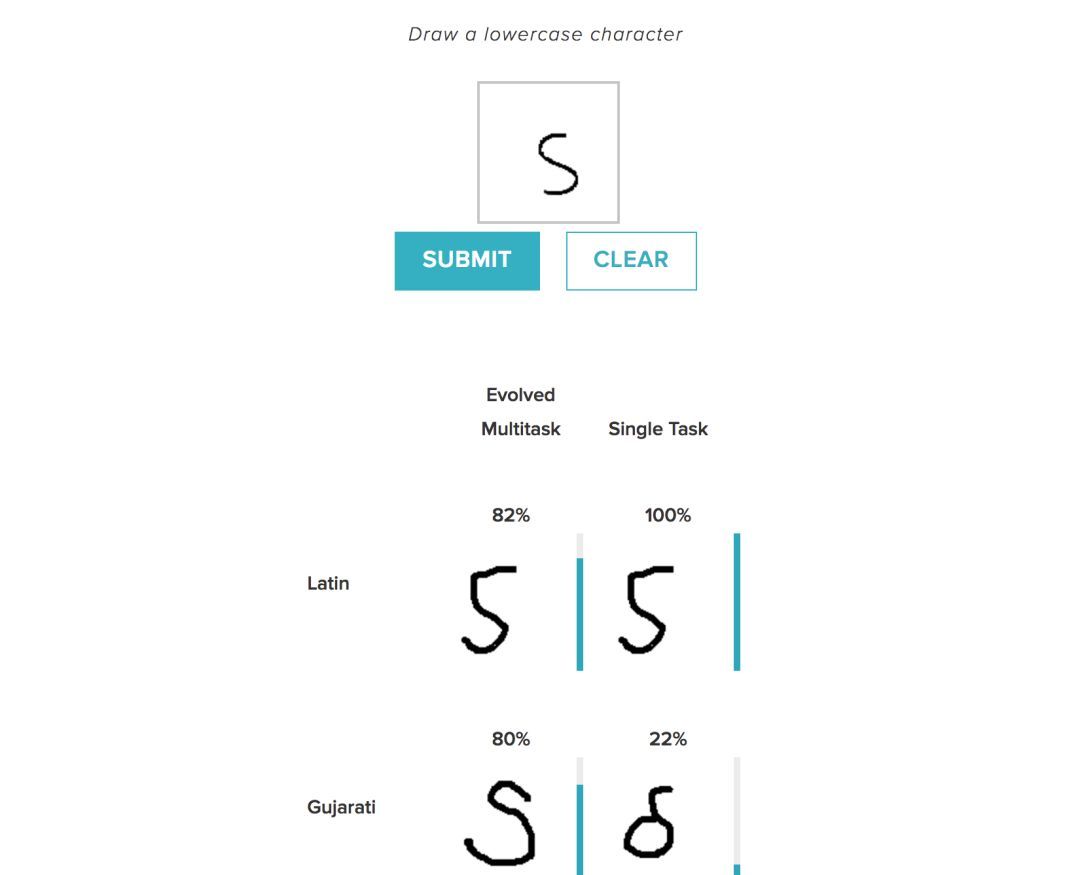
上图示例展示了多任务学习,模型可以同时学习所有语言,并利用不同语言中字符之间的关系。例如,用户输入图像,系统根据匹配输出不同语言的含义,“这将是拉丁语中的X,日语中的Y以及Tengwar中的Z等等”——利用日本、Tengwar和拉丁语之间的关系找出哪些角色是最好的匹配。这与单一任务学习环境不同,单一环境下模型只对一种语言进行训练,并且不能在语言数据集上建立相同的连接。
虽然Omniglot是一个数据集的例子,但每个语言的数据相对较少。例如它可能只有几个希腊字母,但很多都是日语。它能够利用语言之间关系的知识来寻找解决方案。为什么这个很重要?对于许多实际应用程序来说,标记数据的获取是非常昂贵或危险的(例如医疗应用程序、农业和机器人救援),因此可以利用与相似或相关数据集的关系自动设计模型,在某种程度上可以替代丢失的数据集并提高研究能力。这也是神经进化能力的一个很好的证明:语言之间可以有很多的联系方式,并且进化发现了将他们的学习结合在一起的最佳方式。
Celeb Match
Celeb Match的demo同样适用于多任务学习,但它使用的是大规模数据集。该demo是基于CelebA数据集,它由约20万张名人图像组成,每张图片的标签都由40个二进制标记属性,如“男性与女性”、“有无胡子”等等。每个属性都会产生一个“分类任务”,它会引导系统检测和识别每个属性。作为趣味附加组件,我们创建了一个demo来完成这项任务:用户可以为每个属性设置所需的程度,并且系统会根据进化的多任务学习网络来确定最接近的名人。例如,如果当前的图片为布拉德·皮特的形象,用户可以增加“灰色头发”属性,已发现哪个名人与他相似但是头发不同。
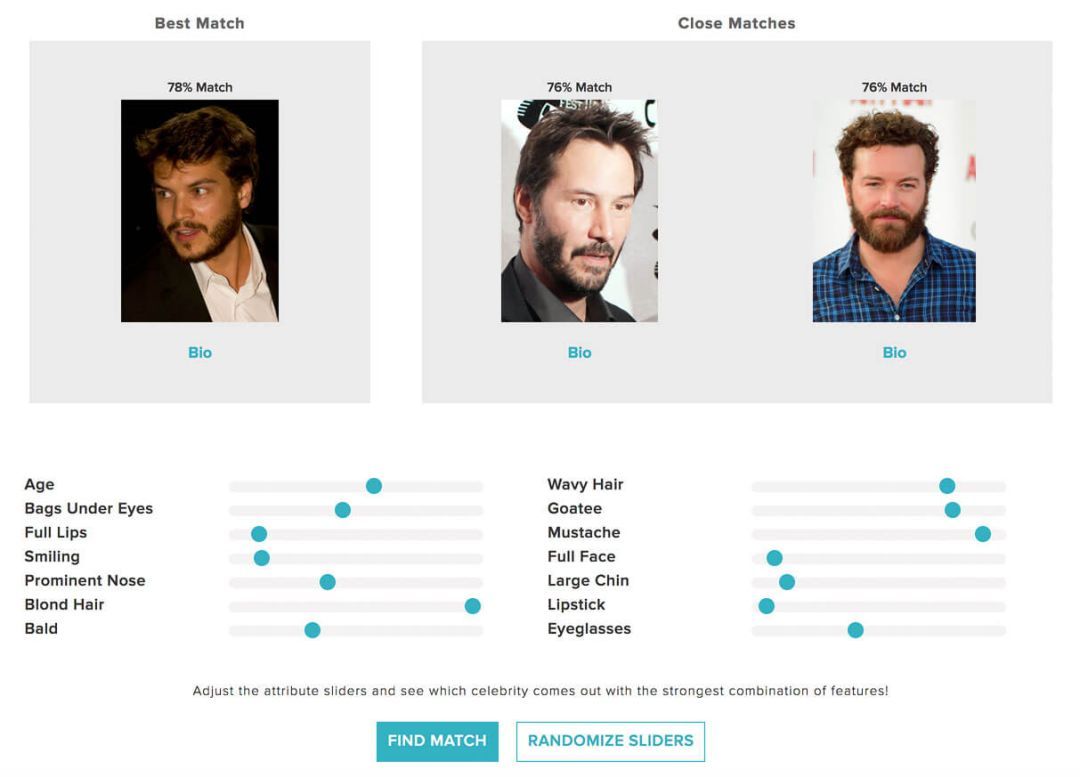
在CelebA多任务人脸分类领域,Sentient使用了演化计算来优化这些检测属性的网络,成功将总体三个模型的误差从8%降到了7.94%。
这一技术使得人工智能在预测人类、地点和物质世界各种属性的能力上提升了一大步。与基于抽象,学习功能找到相似性的训练网络不同,它使相似的语义和可解释性也成为可能。
原文:https://www.sentient.ai/blog/evolution-is-the-new-deep-learning/?spm=a2c4e.11153959.blogcont554768.14.7c4f381flMPfCF