我做容器的研究和容器化几年了,从最初对于容器的初步认识,到积攒了大量的容器迁移经验。
在和客户解释了容器技术之后,才发现原来他对于容器的理解有大量的误解,而且容器并非虚拟机的替代,它是有十分具体的应用场景的。
容器的六大理解误区
误区一:容器启动速度快,秒级启动
这是很多人布道容器的时候经常说的一句话,往往人们会启动一个 Nginx 之类的应用,的确很快就能够启动起来了。
容器为啥启动快,一是没有内核,二是镜像比较小。
然而容器是有主进程的,也即 Entrypoint,只有主进程完全启动起来了,容器才算真正的启动起来。
用一个比喻:容器更像人的衣服,人站起来了,衣服才站起来,人躺下了,衣服也躺下了。衣服有一定的隔离性,但是隔离性没那么好。衣服没有根(内核),但是衣服可以随着人到处走。
所以按照一个 Nginx 来评判一个容器的启动速度有意义么?对于 Java 应用,里面安装的是 Tomcat,而 Tomcat 的启动,加载 War,并且真正的应用启动起来。
如果你盯着 Tomcat 的日志看的话,还是需要一些时间的,根本不是秒级;如果应用启动起来要一两分钟,仅仅谈容器的秒级启动是没有意义的。
现在 OpenStack 中 VM 的启动速度也优化的越来越快了,启动一个 VM 的时候,原来需要从 Glance 下载虚拟机镜像。
后来有了一个技术,是在 Glance 和系统盘共享 Ceph 存储的情况下,虚拟机镜像无需下载,启动速度就快很多。
而且容器之所以启动速度快,往往建议使用一个非常小的镜像,例如 alpine,里面很多东西都裁剪掉了,启动的速度就更快了。
OpenStack 的虚拟机镜像也可以经过大量的裁剪,实现快速的启动。

我们可以精细的衡量虚拟机启动的每一个步骤,裁剪掉相应的模块和启动的过程,大大降低虚拟机的启动时间。
例如在 UnitedStack 的一篇博客里面 https://www.ustack.com/blog/build-block-storage-service,我们可以看到这样的实现和描述:
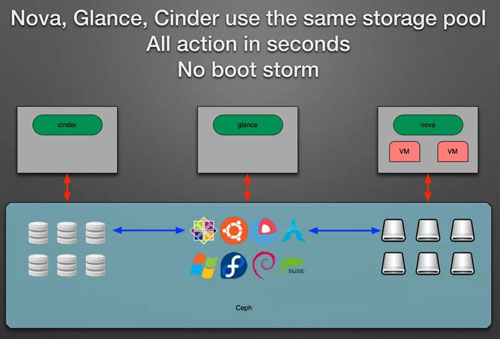
使用原生的 OpenStack 创建虚拟机需要 1~3 分钟,而使用改造后的 OpenStack 仅需要不到 10 秒钟时间。
这是因为 nova-compute 不再需要通过 HTTP 下载整个镜像,虚拟机可以通过直接读取 Ceph 中的镜像数据进行启动。
所以对于虚拟机的整体启动时间,现在优化的不错的情况下,一般能够做到十几秒到半分钟以内。
这个时间和 Tomcat 的启动时间相比较,其实不算是负担,和容器的启动速度相比,没有质的差别,可能有人会说启动速度快一点也是快。
尤其是对于在线环境的挂掉自修复来讲,不是分秒必争么?关于自修复的问题,我们下面另外说。
然而虚拟机有一个好处,就是隔离性好,如果容器是衣服,虚拟机就是房子,房子立在那里,里面的人无论站着还是躺着,房子总是站着的,房子也不会跟着人走。
使用虚拟机就像人们住在公寓里面一样,每人一间,互不干扰,使用容器像大家穿着衣服挤在公交车里面,看似隔离,谁把公交弄坏了,谁都走不了。
综上所述,容器的启动速度不足以构成对 OpenStack 虚拟机的明显优势,然而虚拟机的隔离性,则秒杀容器。
误区二:容器轻量级,每个主机会运行成百上千个容器
很多人会做实验,甚至会跟客户说,容器平台多么多么牛,你看我们一台机器上可以运行成百上千个容器,虚拟机根本做不到这一点。
但是一个机器运行成百上千个容器,有这种真实的应用场景么?对于容器来讲,重要的是里面的应用,应用的核心在于稳定性和高并发支撑,而不在于密度。
我在很多演讲的会议上遇到了很多知名的处理双十一和 618 的讲师,普遍反馈当前的 Java 应用基本上 4 核 8G 是标配,如果遇见容量不足的情况,少部分通过纵向扩容的方式进行,大部分采用横向扩容的方式进行。
如果 4 核 8G 是标配,不到 20 个服务就可以占满一台物理服务器,一台机器跑成百上千个 Nginx 有意思么? 这不是一个严肃的使用场景。
当然现在有一个很火的 Serverless 无服务架构,在无服务器架构中,所有自定义代码作为孤立的、独立的、常常细粒度的函数来编写和执行,这些函数在例如 AWS Lambda 之类的无状态计算服务中运行。
这些计算服务可以是虚拟机,也可以是容器。对于无状态的函数来讲,需要快速的创建可删除,而且很可能执行一个函数的时间本身就非常短,在这种情况下容器相比于虚拟机还是有一定优势的。
目前无服务架构比较适用于运行一些任务型批量操作,利用进程级别的横向弹性能力来抵消进程创建和销毁带来的较大的代价。
在 Spark 和 Mesos 的集成中,有一个 Fine-Grained 模式,在大数据的执行时候,任务的执行进程早就申请好了资源,与等在那里分配资源不同,这种模式是当任务分配到的时候才分配资源。
好处就是对于资源的弹性申请和释放的能力,坏处是进程的创建和销毁还是粒度太大,所以这种模式下 Spark 运行的性能会差一些。
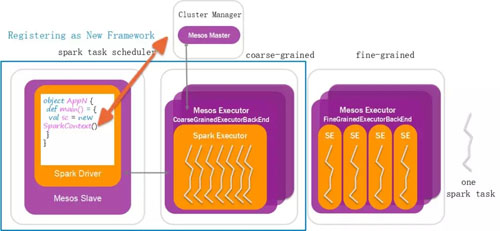
Spark 的这种做法思想类似无服务架构,你会发现我们原来学操作系统的时候,说进程粒度太大,每次都创建和销毁进程会速度太慢。
为了高并发,后来有了线程,线程的创建和销毁轻量级的多,当然还是觉得慢,于是有了线程池,事先创建在了那里,用的时候不用现创建,不用的时候交回去就行。
后来还是觉得慢,因为线程的创建也需要在内核中完成,所以后来有了协程,全部在用户态进行线程切换。
例如 AKKA,Go 都使用了协程,你会发现趋势是为了高并发,粒度是越来越细的,现在很多情况又需要进程级别的,有种风水轮流转的感觉。
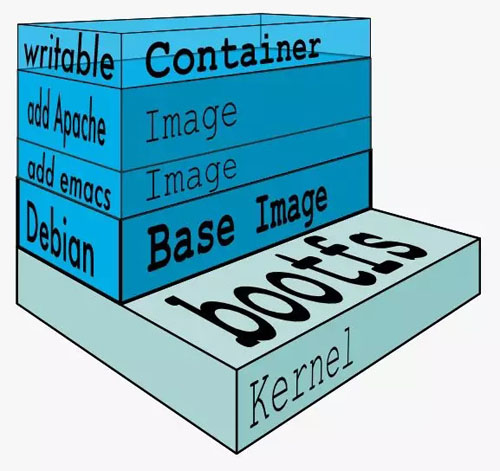
误区三:容器有镜像,可以保持版本号,可以升级和回滚
容器有两个特性,一个是封装,一个是标准。有了容器镜像,就可以将应用的各种配置,文件路径,权限封装起来,然后像孙悟空说“定”,就定在了封装好的那一刻。
镜像是标准的,无论在哪个容器运行环境,将同样的镜像运行起来,都能还原当时的那一刻。
容器的镜像还有版本号,我们可以根据容器的版本号进行升级,一旦升级有错,可以根据版本号进行回滚,回滚完毕则能够保证容器内部还是原来的状态。
但是 OpenStack 虚拟机也是有镜像的,虚拟机镜像也是可以打 snapshot 的,打 snapshot 的时候,也会保存当时的那一刻所有的状态,而且 snapshot 也可以有版本号,也可以升级和回滚。

似乎容器有的这些特性 OpenStack 虚拟机都有,二者有什么不同呢?
虚拟机镜像大,而容器镜像小。虚拟机镜像动不动就几十个 G 甚至上百 G,而容器镜像多几百 M。
虚拟机镜像不适合跨环境迁移。例如开发环境在本地,测试环境在一个 OpenStack 上,开发环境在另一个 OpenStack 上,虚拟机的镜像的迁移非常困难,需要拷贝非常大的文件。
而容器就好的多,因为镜像小,可以很快的从不同的环境之间迁移。
虚拟机镜像不适合跨云迁移。当前没有一个公有云平台支持虚拟机镜像的下载和上传(安全的原因,盗版的原因),因而一个镜像在不同的云之间,或者同一个云不同的 Region 之间,无法进行迁移,只能重新做一个镜像,这样环境的一致性就得不到保障。
而容器的镜像中心是独立于云之外的,只要能够连上镜像中心,到哪个云上都可以下载,并且因为镜像小,下载速度快,镜像是分层的,每次只需要下载差异的部分。
OpenStack 对于镜像方面的优化,基本上还是在一个云里面起作用,一旦跨多个环境,镜像方便的多。
误区四:容器可以使用容器平台管理自动重启实现自修复
容器的自修复功能是经常被吹嘘的。因为容器是衣服,人躺下了,衣服也躺下了,容器平台能够马上发现人躺下了,于是可以迅速将人重新唤醒工作。
而虚拟机是房子,人躺下了,房子还站着。因而虚拟机管理平台不知道里面的人能不能工作,所以容器挂了会被自动重启,而虚拟机里面的应用挂了,只要虚拟机不挂,很可能没人知道。
这些说法都没错,但是人们慢慢发现了另外的场景,就是容器里面的应用没有挂,所以容器看起来还启动着,但是应用已经不工作没有反应了。
当启动容器的时候,虽然容器的状态起来了,但是里面的应用还需要一段时间才能提供服务。
所以针对这种场景,容器平台会提供对于容器里面应用的 health check,不光看容器在不在,还要看里面的应用能不能用,如果不能,可自动重启。
一旦引入了 health check,和虚拟机的差别也不大了,因为有了 health check,虚拟机也能看里面的应用是否工作了,不工作也可以重启应用。
还有就是容器的启动速度快,秒级启动,如果能够自动重启修复,那就是秒级修复,所以应用更加高可用。
这个观点当然不正确,应用的高可用性和重启的速度没有直接关系。高可用性一定要通过多个副本来实现,在任何一个挂掉之后,不能通过这一个应用快速重启来解决,而是应该靠挂掉的期间,其他的副本马上把任务接过来进行解决。
虚拟机和容器都可以有多副本,在有多个副本的情况下,重启是 1 秒还是 20 秒,就没那么重要了,重要的是挂掉的这段时间内,程序做了什么。
如果程序做的是无关紧要的操作,那么挂了 20 秒,也没啥关系;如果程序正在进行一个交易和支付,那挂掉 1 秒也不行,也必须能够修复回来。
所以应用的高可用性要靠应用层的重试,幂等去解决,而不应该靠基础设施层重启的快不快来解决。
对于无状态服务,在做好重试的机制的情况下,通过自动重启修复是没有问题的,因为无状态的服务不会保存非常重要的操作。
对于有状态服务,容器的重启不但不是推荐的,而且可能是灾难的开始。
一个服务有状态,例如数据库,在高并发场景下,一旦挂了,哪怕只有 1 秒,我们必须要弄清楚这 1 秒都发生了什么,哪些数据保存了,哪些数据丢了,而不能盲目的重启,否则很可能会造成数据的不一致性,后期修都没法修。
例如高频交易下的数据库挂了,按说 DBA 应该严格审核丢了哪些数据,而不是在 DBA 不知情的情况下,盲目的重启了,DBA 还觉得没什么事情发生,最终很久才能发现问题。
所以容器是比较适合部署无状态服务的,随便重启都可以。
而容器部署有状态容器不是不能,而是要非常小心,甚至都是不推荐的。
虽然很多的容器平台都支持有状态容器,然而平台往往解决不了数据问题,除非你对容器里面的应用非常非常熟悉。
当容器挂了,你能够准确的知道丢了哪些,哪些要紧,哪些不要紧,而且要写代码处理这些情况,然后才能支持重启。
网易这面的数据库在主备同步的情况下,是通过修改 MySQL 源代码,保证主备之间数据完全同步,才敢在主挂了的情况下,备自动切换主。
而宣传有状态容器的自动重启,对于服务客户来讲是很不经济的行为,因为客户往往没有那么清楚应用的逻辑,甚至应用都是买的。
如果使用有状态容器,任凭自动重启,最终客户发现数据丢失的时候,还是会怪到你的头上。
所以有状态的服务自动重启不是不可用,需要足够专业才行。
误区五:容器可以使用容器平台进行服务发现
容器平台 Swarm,Kubernetes,Mesos 都是支持服务发现的,当一个服务访问另一个服务,都会有服务名转化为 VIP,然后访问具体的容器。

然而人们会发现,基于 Java 写的应用,服务之间的调用多不会用容器平台的服务发现,而是用 Dubbo 或者 Spring Cloud 的服务发现。
因为容器平台层的服务发现,还是做的比较基础,基本是一个域名映射的过程,对于熔断,限流,降级都没有很好的支持。
然而既然使用服务发现,还是希望服务发现中间件能够做到这一点,因而服务之间的服务发现之间使用容器平台的少,越是需要高并发的应用,越是如此。
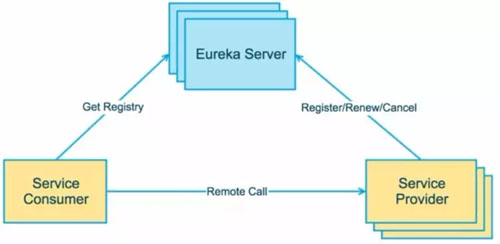
那容器平台的服务发现没有用了么?不是,慢慢你会发现,内部的服务发现是一方面,这些 Dubbo 和 Spring Cloud 能够搞定,而外部的服务发现就不同了。
比如访问数据库,缓存等,到底是应该配置一个数据库服务的名称,还是 IP 地址呢?
如果使用 IP 地址,会造成配置十分复杂,因为很多应用配置之所以复杂,就是依赖了太多的外部应用,也是最难管理的一方面。
如果有了外部的服务发现,配置就会简单很多,也只需要配置外部服务的名称就可以了,如果外部服务地址变了,可以很灵活的改变外部的服务发现。
误区六:容器可以基于镜像进行弹性伸缩
在容器平台上,容器有副本数的,只要将副本数从 5 改到 10,容器就基于镜像进行了弹性伸缩。
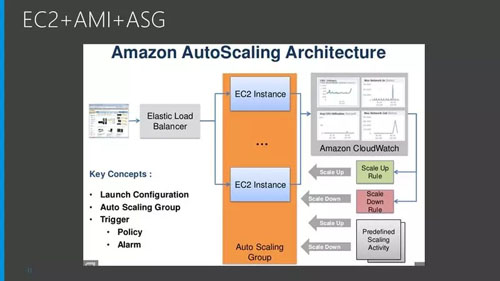
其实这一点虚拟机也能做到,AWS 的 Autoscaling 就是基于虚拟机镜像的,如果在同一个云里面,就没有区别。
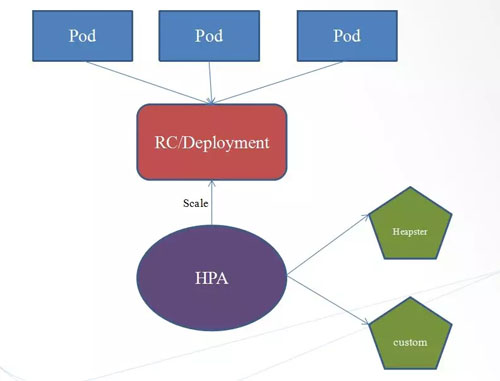
当然如果是跨云无状态容器的弹性伸缩,容器方便很多,可以实现混合云模式,当高并发场景下,将无状态容器扩容到公有云,这一点虚拟机是做不到的。
容器理解误区总结

如上图,左面是经常挂在嘴边的所谓容器的优势,但是虚拟机都能一一怼回去。
如果部署的是一个传统的应用,这个应用启动速度慢,进程数量少,基本不更新,那么虚拟机完全能够满足需求:
- 应用启动慢:应用启动 15 分钟,容器本身秒级,虚拟机很多平台能优化到十几秒,两者几乎看不出差别。
- 内存占用大:动不动 32G,64G 内存,一台机器跑不了几个。
- 基本不更新:半年更新一次,虚拟机镜像照样能够升级和回滚。
- 应用有状态:停机会丢数据,如果不知道丢了啥,就算秒级启动有啥用,照样恢复不了,而且还有可能因为丢数据,在没有修复的情况下,盲目重启带来数据混乱。
- 进程数量少:两三个进程相互配置一下,不用服务发现,配置不麻烦。
如果是一个传统应用,根本没有必要花费精力去容器化,因为白花了力气,享受不到好处。
容器化,微服务,DevOps 三位一体

什么情况下,才应该考虑做一些改变呢?
传统业务突然被互联网业务冲击了,应用老是变,三天两头要更新,而且流量增大了,原来支付系统是取钱刷卡的,现在要互联网支付了,流量扩大了 N 倍。
没办法,一个字:拆
拆开了,每个子模块独自变化,少相互影响。拆开了,原来一个进程扛流量,现在多个进程一起扛。
所以称为微服务。

微服务场景下,进程多,更新快,于是出现 100 个进程,每天一个镜像。
容器乐了,每个容器镜像小,没啥问题,虚拟机哭了,因为虚拟机每个镜像太大了。
所以微服务场景下,可以开始考虑用容器了。

虚拟机怒了,老子不用容器了,微服务拆分之后,用 Ansible 自动部署是一样的。
这样说从技术角度来讲没有任何问题,然而问题是从组织角度出现的。
一般的公司,开发会比运维多的多,开发写完代码就不用管了,环境的部署完全是运维负责,运维为了自动化,写 Ansible 脚本来解决问题。
然而这么多进程,又拆又合并的,更新这么快,配置总是变,Ansible 脚本也要常改,每天都上线,不得累死运维。
所以在如此大的工作量情况下,运维很容易出错,哪怕通过自动化脚本。这个时候,容器就可以作为一个非常好的工具运用起来。
除了容器从技术角度,能够使得大部分的内部配置可以放在镜像里面之外,更重要的是从流程角度,将环境配置这件事情,往前推了,推到了开发这里,要求开发完毕之后,就需要考虑环境部署的问题,而不能当甩手掌柜。
这样做的好处就是,虽然进程多,配置变化多,更新频繁,但是对于某个模块的开发团队来讲,这个量是很小的,因为 5-10 个人专门维护这个模块的配置和更新,不容易出错。
如果这些工作量全交给少数的运维团队,不但信息传递会使得环境配置不一致,部署量会大非常多。
容器是一个非常好的工具,就是让每个开发仅仅多做 5% 的工作,就能够节约运维 200% 的工作,并且不容易出错。
然而本来运维该做的事情开发做了,开发的老大愿意么?开发的老大会投诉运维的老大么?
这就不是技术问题了,其实这就是 DevOps,DevOps 不是不区分开发和运维,而是公司从组织到流程,能够打通,看如何合作,边界如何划分,对系统的稳定性更有好处。
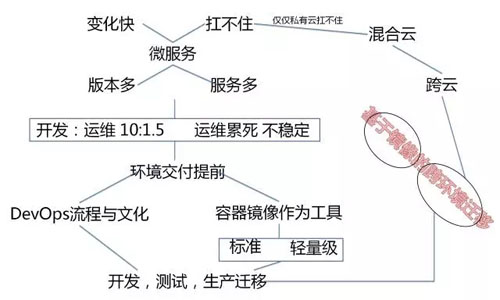
所以微服务,DevOps,容器是相辅相成,不可分割的。
不是微服务,根本不需要容器,虚拟机就能搞定,不需要 DevOps,一年部署一次,开发和运维沟通再慢都能搞定。
所以,容器的本质是基于镜像的跨环境迁移。
镜像是容器的根本性发明,是封装和运行的标准,其他什么 namespace,cgroup,早就有了,这是技术方面。
在流程方面,镜像是 DevOps 的良好工具。容器是为了跨环境迁移的,***种迁移的场景是开发,测试,生产环境之间的迁移。
如果不需要迁移,或者迁移不频繁,虚拟机镜像也行,但是总是要迁移,带着几百 G 的虚拟机镜像,太大了。
第二种迁移的场景是跨云迁移,跨公有云,跨 Region,跨两个 OpenStack 的虚拟机迁移都是非常麻烦,甚至不可能的,因为公有云不提供虚拟机镜像的下载和上传功能,而且虚拟机镜像太大了,一传传一天。
所以跨云场景下,混合云场景下,容器也是很好的使用场景。这也同时解决了仅仅私有云资源不足,扛不住流量的问题。
容器的十大正确使用场景
根据以上的分析,我们发现容器推荐使用在下面的场景下:
- 部署无状态服务,同虚拟机互补使用,实现隔离性。
- 如果要部署有状态服务,需要对里面的应用十分的了解。
- 作为持续集成的重要工具,可以顺利在开发,测试,生产之间迁移。
- 适合部署跨云,跨 Region,跨数据中心,混合云场景下的应用部署和弹性伸缩。
- 以容器作为应用的交付物,保持环境一致性,树立不可变更基础设施的理念。
- 运行进程基本的任务类型的程序。
- 用于管理变更,变更频繁的应用使用容器镜像和版本号,轻量级方便的多。
- 使用容器一定要管理好应用,进行 health check 和容错的设计。