












让计算靠近数据,这听起来像是一种绕过存储访问瓶颈的好方法,但由于软件问题以及开发特定硬件和非x86环境的需要,进展十分困难。
随着数据量从TB级增长到PB级以上,将数据带到处理器所需的时间正在成为一个越来越棘手的难题。
所有计算都包括将计算和数据集中在一起、向DRAM中加载来自存储的数据,这样处理器就可以完成它的工作。这不是一种物理上的靠近;处理器距离数据是1厘米还是20厘米无关紧要。重要的是降低数据访问延迟,并提高数据读取或写入存储的速度。
存储和计算之间存在瓶颈,因为存储介质(主要是磁盘)的访问速度很慢。存储网络也很慢,处理存储IO堆栈需要太多周期。有过几次解决这个问题的尝试,其中一些失败了,另一些仍在开发中,特别是将计算添加到SSD。这些是:
- - 将计算带入存储阵列
- - 将存储带入计算
- - 内存系统
- - 将计算带入磁盘驱动器
- - 将计算带入闪存驱动器
- - 绕过NVMeoF的问题
将计算带入存储阵列
Coho Data试图将计算添加到其存储阵列DataStream MicroArray中,该阵列是Coho Data在2015年5月推出的,采用基于英特尔至强处理器的服务器/控制器、PCIe NVMe闪存卡和磁盘存储。然而,该产品未能取得进展,Coho Data在2017年8月停业。
Coho Data DataStream阵列
在这种方法下,计算针对所谓紧密耦合的存储任务,如视频流转码和Splunk式数据分析。
它不是运行在主机服务器上执行的一般应用的。有两个明显的问题:首先必须自己编写软件或者购买软件以运行在阵列上,执行紧密耦合的存储任务。其次,用于启动的主机服务器代码、编排、管理和计算结果的处理必须自己编写或者购买。
之前在服务器(有一个附加存储阵列)上运行的任务,现在必须细分为主机服务器部分和存储阵列部分,然后进行管理。这也适用于其他任何是计算到存储介质的产品。Coho Data的这款阵列使用x86处理器。如果带入存储驱动器的计算系统不是x86的,那么在其上运行的代码将是在x86主流开发路径之外的。
据我们所知,目前没有任何其他尝试将计算带入存储阵列的显著方法。
将存储带入计算
超融合基础设施(HCI)设备将存储带入计算,使其不再需要外部共享存储阵列。
超融合基础设施节点使用的是本地存储,多个节点的存储聚合为一个虚拟SAN。这仍然可以使用标准的存储IO堆栈(如iSCSI)访问,并且需要通过以太网链路等远程节点上访问数据。
因此,这种将计算和存储更紧密地结合在一起的方式并不会取消存储访问IO堆栈或对远程存储的联网访问。超融合基础设施的好处在于其他方面。
内存系统
内存(DRAM)系统试图彻底取消运行时处理的存储。数据从存储加载到内存,然后在内存中使用,比数据存储在磁盘上的访问速度快得多。
GridGain和Hazelcast就是厂商提供软件运行内存系统的两个例子。
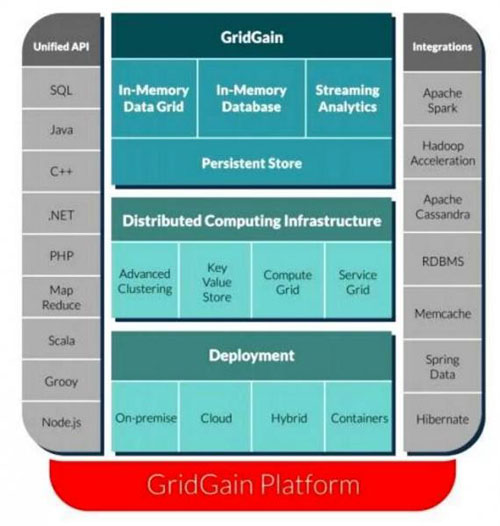
GridGain堆栈
另外一个系统是SAP HANA数据库。磁盘上的源数据很少被访问,以加载内存系统,然后内存数据的更改被写入磁盘,同样频率很低。
或者,对内存数据库的更改将写入保存在磁盘上的事务日志。数据库崩溃的话可以从日志中进行恢复。记录内存交易的的例子包括Redis、Aerospike和Tarantool等产品。
内存系统仅限于使用DRAM,因此在实际尺寸上是有局限性的。
将计算添加到磁盘驱动器的替代方案,旨在提供多TB的容量,而且比DRAM更便宜,提供与存储堆栈和存储网络访问全闪存阵列不同类型的性能提升。
将计算带入磁盘驱动器
希捷的Kinetic技术或多或少地开始实现这一想法——将小型处理器捆绑到磁盘驱动器,并向驱动器添加对象访问协议和存储方案。
希捷Kinetic磁盘驱动器
这么做一部分理由是简化存储访问堆栈处理。但是使用这些驱动器的上游应用进展缓慢,存在软件方面的难题,部分原因是磁盘驱动器仍然是磁盘驱动器,与闪存驱动器相比速度较慢。
OpenIO Arm-y磁盘驱动器
OpenIO已经将ARM CPU添加到磁盘驱动器,将其转变为用于对象存储的纳米节点。
从OpenIO到WDC磁盘驱动器,添加了ARM CPU系统
它有一套Grid for Apps方案,战略负责人Enrico Signoretti说:“硬盘纳米节点适合传统的对象存储用例(例如动态归档),但我们想要复制我们已经在纳米节点x86平台上所做的事情。”
“感谢Grid for Apps [无服务器计算框架],我们已经展示了图像识别和索引、模式检测、接受过程中的数据验证/数据准备、以及一般的数据处理和元数据丰富。借助CPU的动力,我们能够直接在磁盘层面迁移大部分操作,在元数据保存、访问或者更新的时候创造价值。”
他提到了应用领域的一个例子,那就是视频监控:“远程摄像头可以有一个或多个纳米节点保存所有视频流,在本地进行操作(如人脸识别、去除无用部分等等),只将相关信息(包含元数据)发送到核心。所有数据都保存在本地,但只有相关信息被迁移到云端。
“通过这种操作方式,你可以节省大量的网络带宽,同时从中央存储库中删除所有杂乱数据,从而加快操作,降低云中的存储成本。这是一个高级应用,同时也是具有变革意义的。”
他说基于闪存的纳米节点看起来很有前景,因为如果速度更快的话,“目前纳米节点中的硬盘正在限制了应用的范围,因为缺乏IOPS。”
“一旦闪存成为那些以容量驱动的应用的可行选项,我们准备利用我们的无服务器计算框架来运行更接近数据的应用。实时视频编码、人工智能/机器学习、物联网、实时数据分析都是我们密切关注的领域,我们将在接下来的几个月中分享更多信息。”
评论
一般来说,当磁盘IO延迟远远超过存储IO堆栈处理所花费的时间时,用户看不到充足的理由将计算带入磁盘驱动器。这暴露了磁盘速度较慢的特点,而将计算带入速度更快的闪存驱动器(如SSD)看起来更有前景。
就好像它不仅仅需要降低存储网络延迟一样;在将计算带入存储变得有意义之前,有必要消除磁盘驱动器的延迟。












