“一致性”这个词经常出现在分布式系统相关的描述中,究竟指的是什么呢?
写在前面
在分布式存储系统(包括OceanBase这样的分布式数据库)的使用中,我们经常会提到“一致性”这个词,但是这个术语1在不同的系统、不同人的心目中有不同的内涵,很容易造成混淆。
想象一个最简单的存储系统,只有一个客户端(单进程)和一个服务端(单进程服务)。客户端顺序发起读写操作,服务端也顺序处理每个请求,那么无论从服务器视角还是从客户端视角,后一个操作都可以看到前一个操作的结果。
然后,系统变的复杂一些,系统还是单个服务进程(单副本),但是有多个客户端并发进行操作。这个模型下,多个客户端的操作会互相影响,比如一个客户端会读到不是自己写的数据(另一个客户端写入的)。一般单机并发程序就是这样的模型,比如多个线程共享内存的程序中。
然后,系统向另外一个方向变的复杂一些,为了让后端存储系统更健壮(目的不仅如此),我们可以让两个不同的服务进程(位于不同的机器上)同时存储同一份数据的拷贝,然后,通过某种同步机制让这两个拷贝的数据保持一致。这就是我们所说的“多副本”。假设还是一个客户端进程顺序发起读写操作,每个操作理论上可以发给两个副本所在的任意一个服务。那么,如果副本之间是数据同步不及时,就可能发生前面写入的数据读不到,或者前面读到的数据后面读不到等情况。
结合前两种模型,在一类真实的系统中,实际存在多个同时执行读写操作的客户端同时读写多个副本的后端存储服务。如果这些不同客户端的读写操作涉及到同一个数据项(比如,文件系统中,同一个文件的同一个位置范围;或者数据库系统中同一个表的同一行),那么他们的操作会互相影响。比如,A、B两个客户端,操作同一行数据,A修改这行,是不是要求B立即能够读到这个最新数据呢?在多副本的系统中,如果不要求上述保证,那么可能可以允许A和B分别操作不同的副本。
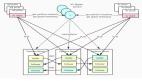
更进一步,前面的系统模型中,假设每个服务进程拥有和管理着一份“全量”的数据。而更复杂的系统中,每个服务进程中,只服务整个数据集的一个子集。例如在OceanBase类似的系统中,单机往往是无法容纳全部数据的一份副本的,所以,数据库表和表的分区是分散在多机上提供服务,每个服务进程只负责某些表分区的一个副本。在这样的系统中,如果一个读写操作涉及到的多个分区位于多个服务进程中,可能出现更复杂的读写语义的异常情况。比如,一个写操作W中修改了两个不同服务进程的两个不同的分区的副本上的两个不同的数据项,随后的一个读取这两个数据项的读操作,是否允许读到W对一个数据项的修改,而读不到对另一个数据项的修改?
综上,我们要讨论的通用的分布式存储系统具有如下特性:
数据分为多个分片存储在多台服务节点上
每个分片有多个副本,存储在不同的服务节点上
许多客户端并发访问系统,执行读写操作,每个读写操作在系统中需要花费不等的时间
除非下文中特别注明和讨论,读写操作是原子的
与数据库事务一致性的差异
数据库事务的ACID的中也有一个一致性(consistency),但彼一致性非此一致性。ACID中的一致性是指,数据库的事务的执行,或者说事务观察到的数据,总是要满足某些全局的 一致性 约束条件,如唯一性约束,外键约束等。这个概念和数据库的数据是否多副本没关系。而本文的一致性在多副本的语境下才有意义。所以,数据库事务的一致性,是指数据项之间总是满足某些约束条件,或者说整个数据库在满足约束条件的意义上是 正确 的。
更让人崩溃的是,事务的隔离性也容易和这里的一致性混淆,因为它和一致性模型类似,限定了某种并发操作的执行顺序。事务的隔离性是指并发执行的事务,能以多大的程度看到看到彼此。这个概念也和数据是否多副本没有关系,单副本的单机数据库也需要支持不同的隔离级别。比如,如果数据库设定为可串行化(serializable)隔离级别,那么并发事务的执行结果,必须等价为让这些事务以某种顺序串行执行的结果。事务的隔离性,是为了并发程序(客户端程序)正确性而生的一种编程抽象,可以类比多线程程序访问共享数据时候需要解决的竞争。在实际系统中,事务是由一系列读写操作组成的,原子的事务的中间状态是可能被并发的其他事务“观察”到的。而在一致性模型的讨论中,我们假设读写操作在服务端是“瞬时”完成的,也就是说,读写操作本身是原子的。
客户端视角一致性模型
在多副本的存储系统中,无论采用什么样的多副本同步协议,为了保证多个副本能够一致,本质上都要求做到:
- 同一份数据的所有副本,都能够接收到全部写操作(无论需要花费多久时间)
- 所有副本要以某种确定顺序执行这些写操作
客户视角的一致性模型定义了下面4种不同的保证。
- 单调读。如果一个客户端读到了数据的某个版本n,那么之后它读到的版本必须大于等于n。
- 读自己所写。如果一个客户端写了某个数据的版本n,那么它之后的读操作必须读到大于等于版本n的数据。
- 单调写。单调写保证同一个客户端的两个不同写操作,在所有副本上都以他们到达存储系统的相同的顺序执行。单调写可以避免写操作被丢失。
- 读后写。读后写一致性,保证一个客户端读到版本n数据后(可能是其他客户端写入的),随后的写操作必须要在版本号大于等于n的副本上执行。
系统对外提供的不同的一致性级别,实际上提供了这其中某几个保证。不同的一致性级别,限定了系统允许的操作执行顺序,以及允许读到多旧的数据。
为什么要定义不同的一致性级别呢?对用户来说,当然越严格的一致性越好,在异常和复杂场景下,严格的一致性级别可以极大地简化应用的复杂度。但是天下没有免费的午餐,一般来说,越严格的一致性模型,意味着性能(延迟)、可用性或者扩展性(能够提供服务的节点数)等要有所损失。
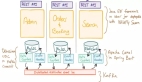
CosmosDB 的一致性级别
Azure Cosmos DB2是一个支持多地部署的分布式NoSQL数据库服务。它提供了丰富的可配置的一致性级别。以下五种一致性级别,从前向后可以提供更低的读写延迟,更高的可用性,更好的读扩展性。
1.强一致性
- 保证读操作总是可以读到最新版本的数据(即可线性化)
- 写操作需要同步到多数派副本后才能成功提交。读操作需要多数派副本应答后才返回给客户端。读操作不会看到未提交的或者部分写操作的结果,并且总是可以读到最近的写操作的结果。
- 保证了全局的(会话间)单调读,读自己所写,单调写,读后写
- 读操作的代价比其他一致性级别都要高,读延迟最高
2.有界旧一致性(bounded staleness)
- 保证读到的数据最多和最新版本差K个版本
- 通过维护一个滑动窗口,在窗口之外,有界旧一致性保证了操作的全局序。此外,在一个地域内,保证了单调读。
3.会话一致性
- 在一个会话内保证单调读,单调写,和读自己所写,会话之间不保证
- 会话一致性能够提供把读写操作的版本信息维护在客户端会话中,在多个副本之间传递
会话一致性的读写延迟都很低
4.前缀一致性
- 前缀一致保证,在没有更多写操作的情况下,所有的副本最终会一致
- 前缀一致保证,读操作不会看到乱序的写操作。例如,写操作执行的顺序是`A, B, C`,那么一个客户端只能看到`A`, `A, B`, 或者`A, B, C`,不会读到`A, C`,或者`B, A, C`等。
- 在每个会话内保证了单调读
5.最终一致性.
- 最终一致性保证,在没有更多写操作的情况下,所有的副本最终会一致
- 最终一致性是很弱的一致性保证,客户端可以读到比之前发生的读更旧的数据
- 最终一致性可以提供最低的读写延迟和最高的可用性,因为它可以选择读取任意一个副本
Cosmos DB的文档中提到了一个有趣的数字。大约有73%的用户使用会话一致性级别,有20%的用户使用有界旧一致性级别。
Cassandra的一致性级别
Cassandra 是一个使用多数派协议的NoSQL存储系统,通过控制读写操作访问的副本数和副本的位置,可以实现不同的一致性级别。注意,作为NoSQL系统,Cassandra只提供单行操作的原子性,多行操作不是原子的。下面的读写操作,都是指单行操作。
对于NoSQL系统,一般支持的写操作叫做PUT(有些系统叫做UPSERT)。这个操作的含义是,如果这行存在(通过唯一主键查找),则修改它;如果这行不存在,则插入。这个语义,可以近似(在不考虑二级索引的时候)等价于关系数据库的INSERT ON DUPLICATE KEY UPDATE语句。本文前面所讲的“写操作”也是泛指这种语义。这个语义有什么特殊之处呢? 第一, 它是幂等的 。所以PUT操作可以重复执行,不怕消息重传。第二, 它是覆盖(overwrite)语义 。所以,NoSQL系统的最终一致性,允许对于同一行数据的写操作可以乱序,只要写操作不断,最终各个副本会一致。而关系数据库的insert和update等修改语句,内部实现都是即需要读也需要写。所以,关系数据库的多副本一致性,假设简单地把SQL修改语句同步到多个副本的方式来实现,必须要以相同的顺序执行才能保证结果一致(当然,实际系统不能这么实现)。
写操作配置
写操作一致性配置定义了对于写操作在哪些副本上成功之后,才能返回给客户端。
- ALL: 写操作需要同步到所有副本并应用到内存中。提供了最强的一致性保证,但是单点故障会引起写入失败,造成系统不可用。
- EACH_QUORUM: 在每个机房(数据中心)中,写操作同步到多数派副本节点中。在多数据中心部署的集群中,可以在每个数据中心提供QUORUM一致性保证。
- QUORUM: 写操作同步到多数派副本节点中。当少数副本宕机的时候,写操作可以持续服务。
- LOCAL_QUORUM: 写操作必须同步到协调者节点所在数据中心的多数派副本中。这种模式可以避免多数据中心部署时,跨机房同步引起的高延迟。在单机房内,可以容忍少数派宕机。
- ONE: 写操作必须写入最少一个副本中。
- TWO: 写操作必须写入至少两个副本中。
- THREE: 写操作必须写入至少三个副本中。
- LOCAL_ONE: 写操作必须写入本地数据中心至少一个副本中。在多机房部署的集群中,可以达到和ONE相同的容灾效果,并且把写操作限制在本地机房。
读操作配置
- 每个读操作可以设定如下不同的一致性配置。
- ALL: 读操作在全部副本节点应答后才返回给客户端。单点单机会引起写操作失败,造成系统不可用。
- QUORUM: 读操作在多数派副本返回应答后返回给客户端。
- LOCAL_QUORUM: 读操作在本机房多数派副本返回应答后返回给客户端。可以避免跨机房访问的高延迟。
- ONE: 最近的一个副本节点应答后即返回给客户端。可能返回旧数据。
- TWO: 两个副本节点应答后即返回给客户端。
- THREE: 三个副本节点应答后返回给客户端。
- LOCAL_ONE: 本机房最近的一个副本节点应答后返回客户端。
系统一致性级别
从系统层面来看,Cassandra提供了强一致性和最终一致性两种一致性级别。不考虑多机房因素,通过设置上述读写操作的一致性配置,当写入副本数与读取副本数之和大于总副本数的时候,可以保证读操作总是可以读取最新被写入的数据,即强一致性保证。如果写入副本数与读取副本数之和小于总副本数的时候,读操作可能无法读到最新的数据,而且读操作可能读到比之前发生的读操作更旧的数据,所以这种情况下是最终一致性。
而副本位置是选择整个集群、每个机房还是本地机房等因素,是为了在不同的容灾场景下,对跨机房通讯引入的高延迟进行优化,固有的一致性级别并不受影响。例如,写操作用EACH_QUORUM,读操作用LOCAL_QUORUM,还是提供了强一致性保证,但是不同机房的读操作都变成本地的了,读延迟较低。但是,和写操作用QUORUM模式相比,某个机房发生了多数派宕机(总副本数还是少数派),就会导致写操作失败。再如,读写操作都用LOCAL_QUORUM,那么协调者节点所在机房内是强一致性的,与协调者节点不在一个机房的读操作则可能读到旧数据。
OceanBase的一致性级别
一般来说,NoSQL类数据库,比如HBase, Cassandra4等,仅提供单行操作的原子性保证。而关系数据库的基本操作是一条SQL语句,SQL语句天生是多行操作,而且支持多语句事务和事务的回滚等,在SQL语句级和事务级还都需要提供原子性保证。可以理解,实现相同的一致性级别,分布式关系数据库比NoSQL类系统的复杂度和代价都要高。
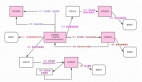
OceanBase使用Multi-Paxos分布式共识算法在多个数据副本之间同步事务提交日志,每个修改事务,要在多数派副本应答以后才认为提交成功。多个副本之间,通过自主投票的机制,选出其中一个副本为主副本(leader),它负责所有修改语句的执行,特别的,达成多数派的事务提交日志要求包含主副本自己。在通常情况下,数据库需要保证强一致性语义(和单机数据库类比),我们的做法是,读写语句都在主副本上执行。当主副本宕机的时候,其余的多数派副本会选出新的主副本。此时,已经完成的每一个事务一定有至少一个副本记录了提交日志的。新的主副本通过和其他副本的通信可以获得所有已提交事务的日志,进而完成恢复,恢复以后继续提供服务。通过这种机制,OceanBase可以保证在少数派宕机的情况下不会丢失任何数据,而强一致性读写服务的宕机恢复时间小于一分钟。
如果一个语句的执行涉及到多个表的分区,在OceanBase中这些分区的主副本可能位于不同的服务节点上。严格的数据库隔离级别要求涉及多个分区的读请求看到的是一个“快照”,也就是说,不允许看到部分事务。这要求维护某种形式的全局读版本号,开销较大。如果应用允许,可以调整读一致性级别,系统保证读到最新写入的数据,但是不同分区上的数据不是一个快照。从一致性级别来看,这也是强一致性级别,但是打破了数据库事务的ACID属性。
在使用数据库的互联网业务中,有很多情况下业务组件还允许读到稍旧的数据,OceanBase提供两种更弱的一致性级别。在最弱的级别下,我们可以利用所有副本提供读服务。在OceanBase的实现中,多副本同步协议只保证日志落盘,并不要求日志在多数派副本上完成回放(写入存储引擎的memtable中)。所以,利用任意副本提供读服务时,即使对于同一个分区的多个副本,每个副本完成回放的数据版本也是不同的,这样可能会导致读操作读到比之前发生的读更旧的数据。也就是说,这种情况下提供的是最终一致性。当任意副本宕机的时候,客户端可以迅速重试其他副本,甚至当多数派副本宕机的时候还可以提供这种读服务。
但是,实际上,使用关系数据库的应用,大多数还是不能容忍乱序读的。通过在数据库连接内记录读版本号,我们还提供了比最终一致性更严格的前缀一致性。它可以在每个数据库连接内,保证单调读。这种模式,一般用于OceanBase集群内读库的访问,业务本身是读写分离的架构。
此外,对于这两种弱一致性级别,用户可以通过配置,控制允许读到多旧的数据。在多地部署OceanBase的时候,跨地域副本数据之间的延迟是固有的。比如,用户配置允许读到30秒内的数据,那么只要本地副本的延迟小于30秒,则读操作可以读取本地副本。如果不能满足要求,则读取主副本所在地的其他副本。如果还不能满足,则会读取主副本。这样的方式可以获得最小的读延迟,以及比强一致性读更好的可用性。这样,在同时保证会话级单调读的条件下,我们提供了有界旧一致性级别。
注意,这些弱一致性级别都是放松了读操作的语义,而所有的写操作都需要写入主副本节点。所以,单调写和读后写总是保证的,但是读自己所写是不保证的。理论上,对于后几种弱一致性级别中的每一种,我们也可以提供读到的数据是不是保证“快照”的两种不同语义,但是这违反了ACID语义,所以并没有提供。
综上所述,OceanBase在保证关系数据库完备的ACID事务语义前提下,提供了强一致性、有界旧一致性、前缀一致性和最终一致性这几种一致性级别。
最后,特别感谢 @杨苏立 阅读本文,并提出宝贵的修改意见。
参考资料
1 Consistency model in Wikipedia. https://en.wikipedia.org/wiki/Consistency_model
2 Tunable data consistency levels in Azure Cosmos DB. https://docs.microsoft.com/en-us/azure/cosmos-db/consistency-levels
3 Configuring data consistency in Apache Cassandra. https://docs.datastax.com/en/archived/cassandra/2.0/cassandra/dml/dml_config_consistency_c.html
4 Cassandra 2.0提供了一种轻量级事务,详见其文档。