此文展示了基于RNN的生成模型在歌词和钢琴音乐上的应用。
介绍
在这篇博文中,我们将在歌词数据集上训练RNN字符级语言模型,数据集来自最受欢迎以及最新发布的艺术家的作品。模型训练好之后,我们会选出几首歌曲,这些歌曲将会是不同风格的不同艺术家的有趣混合。之后,我们将更新模型使之成为一个条件字符级RNN,使我们能够从艺术家的歌曲中采样。最后,我们通过对钢琴曲的midi数据集的训练来总结。
在解决这些任务的同时,我们将简要地探讨一些有关RNN训练和推断的有趣概念,如字符级RNN,条件字符级RNN,从RNN采样,经过时间截断的反向传播和梯度检查点。
所有的代码和训练模型都已在 github 上开源,并通过 PyTorch 实现。这篇博文同样也可用jupyter notebook 阅读。如果你已经熟悉字符级语言模型和循环神经网络,可以随意跳过各个部分或直接进入结果部分。
字符级语言模型
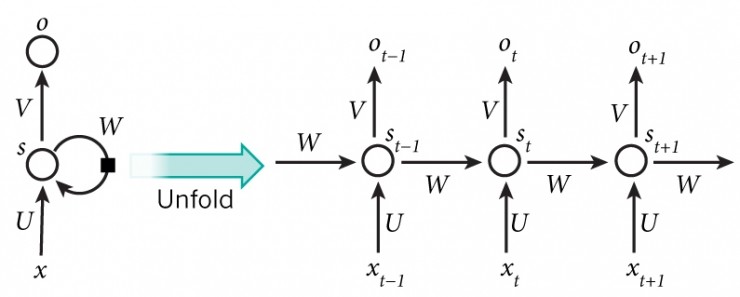
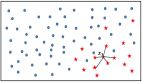
在选择模型前,让我们仔细看看我们的任务。基于现有的字母和所有之前的字母,我们将预测下一个字符。在训练过程中,我们只使用一个序列,除了最后一个字符外,序列中的其他字符将作为输入,并从第二个字符开始,作为groundtruth(见上图:源)。我们将从最简单的模型开始,在进行预测时忽略所有前面的字符,然后改善这个模型使其只考虑一定数量的前面的字符,最后得到一个考虑所有前面的字符的模型。
我们的语言模型定义在字符级别。我们将创建一个包含所有英文字符和一些特殊符号(如句号,逗号和行尾符号)的字典。每个字符将被表示为一个独热编码的张量。有关字符级模型和示例的更多信息,推荐此资源。
有了字符后,我们可以生成字符序列。即使是现在,也可以通过随机抽样字符和固定概率p(any letter)=1和字典大小p(any letter)=1dictionary size来生成句子。这是最简单的字符级语言模型。可以做得更好吗?当然可以,我们可以从训练语料库中计算每个字母的出现概率(一个字母出现的次数除以我们的数据集的大小),并且用这些概率随机抽样。这个模型更好但是它完全忽略了每个字母的相对位置。
举个例子,注意你是如何阅读单词的:你从第一个字母开始,这通常很难预测,但是当你到达一个单词的末尾时,你有时会猜到下一个字母。当你阅读任何单词时,你都隐含地使用了一些规则,通过阅读其他文本学习:例如,你从单词中读到的每一个额外的字母,空格字符的概率就会增加(真正很长的单词是罕见的),或者在字母"r"之后的出现辅音的概率就会变低,因为它通常跟随元音。有很多类似的规则,我们希望我们的模型能够从数据中学习。为了让我们的模型有机会学习这些规则,我们需要扩展它。
让我们对模型做一个小的逐步改进,让每个字母的概率只取决于以前出现的字母(马尔科夫假设)。所以,基本上我们会有p(current letter|previous letter)。这是一个马尔科夫链模型(如果你不熟悉,也可以尝试这些交互式可视化)。我们还可以从训练数据集中估计概率分布p(current letter|previous letter)。但这个模型是有限的,因为在大多数情况下,当前字母的概率不仅取决于前一个字母。
我们想要建模的其实是p(current letter|all previous letters)。起初,这个任务看起来很棘手,因为前面的字母数量是可变的,在长序列的情况下它可能变得非常大。结果表明,在一定程度上,利用共享权重和固定大小的隐藏状态,循环神经网络可以解决这个问题,因此引出下一个讨论RNNs的部分。
循环神经网络
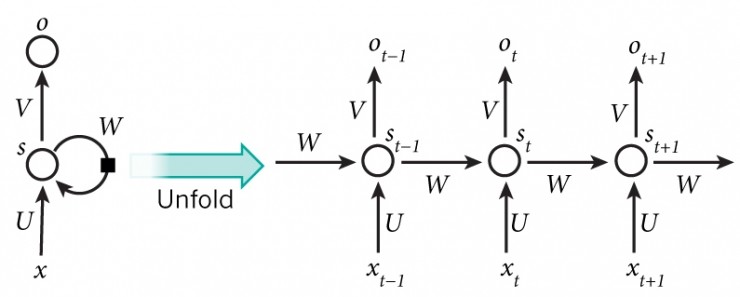
循环神经网络是一族用于处理序列数据的神经网络,与前馈神经网络不同,RNNs可以使用其内部存储器来处理任意输入序列。
由于任意大小的输入序列,它们被简洁地描述为一个具有循环周期的图(见上图:源)。但是如果已知输入序列的大小,则可以"展开"。定义一个非线性映射,从当前输入xt 和先前隐藏状态 st−1 到输出ot 和隐藏状态 st。隐藏状态大小具有预定义的大小,存储在每一步更新的特征,并影响映射的结果。
现在,将字符级语言模型的前一张图片与已折叠的RNN图片对齐,以了解我们如何使用RNN模型来学习字符级语言模型。
虽然图片描绘了Vanilla RNN,但是我们在工作中使用LSTM,因为它更容易训练,通常可以获得更好的结果。
为了更详细地介绍RNNs,推荐以下资源。
歌词数据集
在实验中,我们选择了55000+ Song Lyrics Kaggle dataset,其中包含了很多近期的艺术家和更多经典的好作品。它存储为pandas文件,并用python包装,以便用于培训。为了使用我们的代码,你需要自行下载。
为了能够更好地解释结果,我选择了一些我稍微熟悉的艺术家:
- artists = [
- 'ABBA',
- 'Ace Of Base',
- 'Aerosmith',
- 'Avril Lavigne',
- 'Backstreet Boys',
- 'Bob Marley',
- 'Bon Jovi',
- 'Britney Spears',
- 'Bruno Mars',
- 'Coldplay',
- 'Def Leppard',
- 'Depeche Mode',
- 'Ed Sheeran',
- 'Elton John',
- 'Elvis Presley',
- 'Eminem',
- 'Enrique Iglesias',
- 'Evanescence',
- 'Fall Out Boy',
- 'Foo Fighters',
- 'Green Day',
- 'HIM',
- 'Imagine Dragons',
- 'Incubus',
- 'Jimi Hendrix',
- 'Justin Bieber',
- 'Justin Timberlake',
- 'Kanye West',
- 'Katy Perry',
- 'The Killers',
- 'Kiss',
- 'Lady Gaga',
- 'Lana Del Rey',
- 'Linkin Park',
- 'Madonna',
- 'Marilyn Manson',
- 'Maroon 5',
- 'Metallica',
- 'Michael Bolton',
- 'Michael Jackson',
- 'Miley Cyrus',
- 'Nickelback',
- 'Nightwish',
- 'Nirvana',
- 'Oasis',
- 'Offspring',
- 'One Direction',
- 'Ozzy Osbourne',
- 'P!nk',
- 'Queen',
- 'Radiohead',
- 'Red Hot Chili Peppers',
- 'Rihanna',
- 'Robbie Williams',
- 'Rolling Stones',
- 'Roxette',
- 'Scorpions',
- 'Snoop Dogg',
- 'Sting',
- 'The Script',
- 'U2',
- 'Weezer',
- 'Yellowcard',
- 'ZZ Top']
训练无条件的字符级语言模型
第一个实验是在整个语料库上训练我们的字符级语言模型RNN,在训练时没有考虑艺术家的信息。
从RNN采样
在训练完模型之后,我们试着抽出几首歌。基本上,RNN每一步都会输出logits,我们可以利用softmax函数从分布中取样。或者可以直接使用Gumble-Max技巧采样,这和直接使用logits是等价的。
抽样的一个有趣之处是,我们可以对输入序列进行部分定义,并在初始条件下开始采样。举个例子,我们采样以"Why"开头的歌曲:
- Why do you have to leave me?
- I think I know I'm not the only one
- I don't know if I'm gonna stay awake
- I don't know why I go along
- I don't know why I can't go on
- I don't know why I don't know
- I don't know why I don't know
- I don't know why I keep on dreaming of you
那么,这听起来像是一首歌。
让我们来看一下以“Well”开头的歌曲:
- Well, I was a real good time
- I was a rolling stone
- I was a rock and roller
- Well, I never had a rock and roll
- There were times I had to do it
- I had a feeling that I was found
- I was the one who had to go
采样过程中使用的"temperature"参数控制采样过程的随机性。当这个参数接近零时,采样等于argmax,当它接近无穷时,采样等同于均匀分布的采样。可以看一下相关论文中的图(Jang et al):
当τ=1时,分布不受影响。如果我们减少 τ,分布变得更加明显,意味着有更大概率质量的值会增加。当τ 接近零时,采样将相当于argmax,因为该值的概率接近于1。当我们开始增加τ 时,分布变得越来越均匀。
之前的样本是在"temperature"参数等于0.5的情况下生成的,让我们看看当我们增加到1.0时会发生什么:
- Why can't we drop out of time?
- We were born for words to see.
- Won't you love this. You're still so amazing.
- This could be that down on Sunday Time.
- Oh, Caroline, a lady floor.
- I thought of love, oh baby.
让我们进一步增加:
- Why - won't we grow up naked?
- We went quietly what we would've still give
- That girl you walked before our bedroom room
- I see your mind is so small to a freak
- Stretching for a cold white-heart of crashing
- Truth in the universal daughter
- I lose more and more hard
- I love you anytime at all
- Ah come let your help remind me
- Now I've wanted waste and never noticed
- I swear I saw you today
- You needed to get by
- But you sold a hurricane
- Well out whispered in store
我们为什么不直接一次性增加呢?
那么,你可以看到这样的趋势:当我们增加"temperature"时,采样的句子变得越来越随机。
训练有条件的字符级语言模型
想象一下,如果我们能够以某种特定艺术家的风格生成歌词。让我们改变我们的模型,以便在训练期间使用这些信息。
我们将通过为我们的RNN增加一个额外的输入来做到这一点。到目前为止,我们的RNN模型只接受每步包含one-hot编码字符的张量。
对我们的模型的扩展将是非常简单的:我们将拥有和额外的一个热点编码张量来代表艺术家。所以每一步RNN都会接受一个张量,这个张量由代表人物和艺术家的连续张量组成。更多信息可以点击此处查看
从有条件语言模型RNN中抽样
训练结束后,我们抽取了一些艺术家的歌曲,部分结果如下所示:
Him:
- My fears
- And the moment don't make me sing
- So free from you
- The pain you love me yeah
- Whatever caused the warmth
- You smile you're happy
- You sit away
- You say it's all in vain
似乎真的有可能,尤其是使用了痛苦这个词,这在艺术家的歌词中是很常见的事实。
ABBA:
- Oh, my love it makes me close a thing
- You've been heard, I must have waited
- I hear you
- So I say
- Thank you for the music, that makes me cry
- And you moving my bad as me, ah-hang wind in the hell
- I was meant to be with you, I'll never be playing up
Bob Marley:
- Mercy on judgment, we got so much
- Alcohol, cry, cry, cry
- Why don't try to find our own
- I want to know, Lord, I wanna give you
- Just saving it, learned
- Is there any more?
- All that damage done
- That's all reason, don't worry
- Need a hammer
- I need you more and more
Coldplay:
- Look at the stars
- Into life matter where you lay
- Saying no doubt
- I don't want to fly
- In my dreams and fight today
- I will fall for you
- All I know
- And I want you to stay
- Into the night
- I want to live waiting
- With my love and always
- Have I wouldn't wasted
- Would it hurt you
Kanye West:
- I'm everywhere for you
- The way that it couldn't stop
- I mean it too late and love I made in the world
- I told you so I took the studs full cold-stop
- The hardest stressed growin'
- The hustler raisin' on my tears
- I know I'm true, one of your love
看起来很酷,但请记住,我们没有跟踪验证的准确性,所以一些样本行可能已经被rnn模型记住了。一个更好的方法是选择一个模型,在训练期间给出最好的验证分数(见下一节我们用这种方式进行训练的代码)。
我们也注意到了一件有趣的事情:当你想用一个指定的起始字符串进行采样时,无条件模型通常更好地表现出来。我们的直觉是,当从一个具有特定起始字符串的条件模型中抽样时,我们实际上把两个条件放在我们的模型开始字符串和一个艺术家之间。而且我们没有足够的数据来模拟这个条件分布(每个歌手的歌曲数量相对有限)。
我们正在使代码和模型可用,并且即使没有gpu,也可以从我们训练好的模型中采样歌曲,因为它计算量并不大。
Midi 数据集
接下来,我们将使用由大约700首钢琴歌曲组成的小型midi数据集。我们使用了诺丁汉钢琴数据集(仅限于训练分割)。
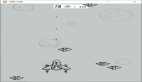
任何MIDI文件都可以转换为钢琴键轴,这只是一个时频矩阵,其中每一行是不同的MIDI音高,每一列是不同的时间片。因此,我们数据集中的每首钢琴曲都会被表示成一个大小的矩阵88×song_length,88 是钢琴音调的个数。下图是一个钢琴键轴矩阵的例子:
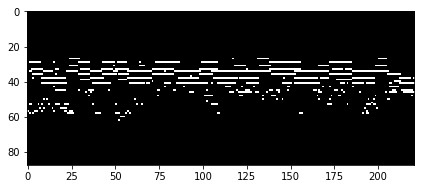
即使对于一个不熟悉音乐理论的人来说,这种表现方式也很直观,容易理解。每行代表一个音高:高处的行代表低频部分,低处的行代表高频部分。另外,我们有一个代表时间的横轴。所以如果我们在一定时间内播放一定音调的声音,我们会看到一条水平线。总而言之,这与YouTube上的钢琴教程非常相似。
现在,我们来看看字符级模型和新任务之间的相似之处。在目前的情况下,给定以前播放过的所有音调, 我们将预测下一个时间步将要播放的音调。所以,如果你看一下钢琴键轴的图,每一列代表某种音乐字符,给定所有以前的音乐字符,预测下一个音乐字符。我们注意依一下文字字符与音乐字符的区别。回忆一下,语言模型中的每个字符都是由one-hot向量表示的(意思是我向量中只有一个值是1,其他都是0)。对于音乐字符,可以一次按下多个键(因为我们正在处理复音数据集)。在这种情况下,每个时间步将由一个可以包含多个1的向量表示。
培养音高水平的钢琴音乐模型
在开始训练之前,根据在前面讨论过的不同的输入,需要调整我们用于语言模型的损失函数。在语言模型中,我们在每个时间步上都有one-hot的编码张量(字符级)作为输入,用一个one-hot的编码张量作为输出(预测的下一个字符)。由于预测的下一个字符时使用独占,我们使用交叉熵损失。
但是现在我们的模型输出一个不再是one-hot编码的矢量(可以按多个键)。当然,我们可以将所有可能的按键组合作为一个单独的类来处理,但是这是比较难做的。相反,我们将输出向量的每个元素作为一个二元变量(1表示正在按键,0表示没有按键)。我们将为输出向量的每个元素定义一个单独的损失为二叉交叉熵。而我们的最终损失将是求这些二元交叉熵的平均和。可以阅读代码以获得更好的理解。
按照上述的修改后,训练模型。在下一节中,我们将执行采样并检查结果。
从音调水平的RNN采样
在优化的早期阶段,我们采样了钢琴键轴:
可以看到,模型正在开始学习数据集中歌曲常见的一种常见模式:1首歌曲由2个不同的部分组成。第一部分包含一系列独立播放的节奏,非常易辨,通常是可唱(也称为旋律)。如果看着采样的钢琴键轴图,这部分在底部。如果观察钢琴卷轴的顶部,可以看到一组通常一起演奏的音高 - 这是伴随着旋律的和声或和音(在整个歌曲中一起播放的部分)的进行。
训练结束后,从模型中抽取样本如下图所示:
如图所示,他们和前面章节中的所看到的真实情况相似。
训练结束后,抽取歌曲进行分析。这里有一个有趣的介绍样本。而另一个样本,是具有很好的风格转换。同时,我们生成了一些低速参数的例子,它们导致歌曲的速度慢了:这里是第一个和第二个。可以在这里找到整个播放列表。
序列长度和相关问题
现在让我们从GPU内存消耗和速度的角度来看待我们的问题。
我们通过批量处理我们的序列大大加快了计算速度。同时,随着序列变长(取决于数据集),我们的最大批量开始减少。为什么是这种情况?当我们使用反向传播来计算梯度时,我们需要存储所有对内存消耗贡献最大的中间激活量。随着我们的序列变长,我们需要存储更多的激活量,因此,我们可以用更少的样本在批中。
有时候,我们需要用很长的序列来工作,或者增加批的大小,而你只有1个有少量内存的GPU。在这种情况下,有多种可能的解决方案来减少内存消耗,这里,我们只提到两种解决方案,它们之间需要取舍。
首先是一个截断的后向传播。这个想法是将整个序列拆分成子序列,并把它们分成不同的批,除了我们按照拆分的顺序处理这些批,每一个下一批都使用前一批的隐藏状态作为初始隐藏状态。我们提供了这种方法的实现,以便能更好地理解。这种方法显然不是处理整个序列的精确等价,但它使更新更加频繁,同时消耗更少的内存。另一方面,我们有可能无法捕捉超过一个子序列的长期依赖关系。
第二个是梯度检查点。这种方法使我们有可能在使用更少内存的同时,在整个序列上训练我们的模型,以执行更多的计算。回忆,之前我们提到过训练中的大部分内存资源是被激活量使用。梯度检查点的思想包括仅存储每个第n个激活量,并在稍后重新计算未保存的激活。这个方法已经在Tensorflow和Pytorch中实现。
结论和未来的工作
在我们的工作中,我们训练了简单的文本生成模型,扩展了模型以处理复调音乐,简要介绍了采样如何工作以及温度参数如何影响我们的文本和音乐样本 - 低温提供了更稳定的结果,而高温增加了更多的随机性这有时会产生非常有趣的样本。
未来的工作可以包括两个方向 - 用训练好的模型在更多的应用或更深入的分析上。例如,可以将相同的模型应用于Spotify收听历史记录。在训练完收听历史数据后,可以给它一段前一小时左右收听的歌曲序列,并在当天余下时间为您播放一个播放列表。那么,也可以为你的浏览历史做同样的事情,这将是一个很酷的工具来分析你的浏览行为模式。在进行不同的活动(在健身房锻炼,在办公室工作,睡觉)时,从手机中获取加速度计和陀螺仪数据,并学习分类这些活动阶段。之后,您可以根据自己的活动自动更改音乐播放列表(睡眠 - 冷静的音乐,在健身房锻炼 - 高强度的音乐)。在医学应用方面,模型可以应用于基于脉搏和其他数据检测心脏问题,类似于这项工作。
分析在为音乐生成而训练的RNN中的神经元激励是非常有趣的,链接在这里。看模型是否隐含地学习了一些简单的音乐概念(就像我们对和声和旋律的讨论)。 RNN的隐藏表示可以用来聚集我们的音乐数据集以找到相似的歌曲。
让我们从我们无条件的模型中抽取最后一首歌词来结束这篇文章:D:
- The story ends
- The sound of the blue
- The tears were shining
- The story of my life
- I still believe
- The story of my life