日前,从微软亚洲研究院官网了解到其研究团队对外宣布,最新研发的机器翻译系统在通用新闻报道测试集newstest2017的中-英测试集上,达到了可与人工翻译媲美的水平。
据称,这是首个在新闻报道的翻译质量和准确率上可以比肩人工翻译的翻译系统。
该系统模型包含了由微软亚洲研究院研发的对偶学习、推敲网络、联合训练和一致性规范技术。机器翻译是自然语言处理领域最具挑战性的研究任务之一。
微软技术院士,负责微软语音、自然语言和机器翻译工作的黄学东称,“这是对自然语言处理领域最具挑战性任务的一项重大突破。在机器翻译方面达到与人类相同的水平是所有人的梦想,我们没有想到这么快就能实现。”
据悉,newstest2017新闻报道测试集由产业界和学术界的合作伙伴共同开发,并于去年秋天在WMT17大会上发布。为了确保翻译结果准确且达到人类的翻译水平,微软研究团队邀请了双语语言顾问将微软的翻译结果与两个独立的人工翻译结果进行了比较评估。
虽然此次突破意义非凡,但研究人员也提醒大家,这并不代表人类已经完全解决了机器翻译的问题,只能说明我们离终极目标又更近了一步。微软亚洲研究院副院长、自然语言计算组负责人周明表示,在WMT17测试集上的翻译结果达到人类水平很鼓舞人心,但仍有很多挑战需要我们解决,比如在实时的新闻报道上测试系统等。
附该系统包含的四大技术——
对偶学习(Dual Learning):
对偶学习的发现是由于现实中有意义、有实用价值的人工智能任务往往会成对出现,两个任务可以互相反馈,从而训练出更好的深度学习模型。例如,在翻译领域,我们关心从英文翻译到中文,也同样关心从中文翻译回英文;在语音领域,我们既关心语音识别的问题,也关心语音合成的问题;在图像领域,图像识别与图像生成也是成对出现。此外,在对话引擎、搜索引擎等场景中都有对偶任务。
一方面,由于存在特殊的对偶结构,两个任务可以互相提供反馈信息,而这些反馈信息可以用来训练深度学习模型。也就是说,即便没有人为标注的数据,有了对偶结构也可以做深度学习。另一方面,两个对偶任务可以互相充当对方的环境,这样就不必与真实的环境做交互,两个对偶任务之间的交互就可以产生有效的反馈信号。因此,充分地利用对偶结构,就有望解决深度学习和增强学习的瓶颈,如“训练数据从哪里来、与环境的交互怎么持续进行”等问题。
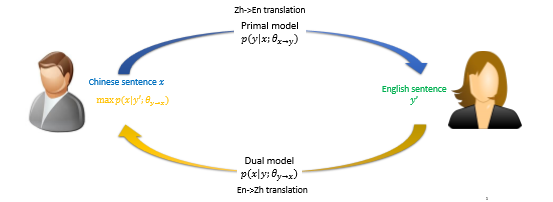
图:对偶无监督学习框架
推敲网络(Deliberation Networks):
“推敲”二字可以认为是来源于人类阅读、写文章以及做其他任务时候的一种行为方式,即任务完成之后,并不当即终止,而是会反复推敲。微软亚洲研究院机器学习组将这个过程沿用到了机器学习中。推敲网络具有两段解码器,其中第一阶段解码器用于解码生成原始序列,第二阶段解码器通过推敲的过程打磨和润色原始语句。后者了解全局信息,在机器翻译中看,它可以基于第一阶段生成的语句,产生更好的翻译结果。
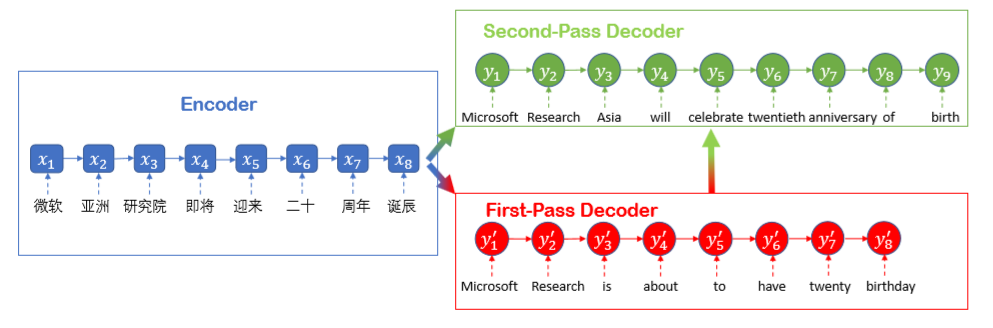
图:推敲网络的解码过程
联合训练(Joint Training):
这个方法可以认为是从源语言到目标语言翻译(Source to Target)的学习与从目标语言到源语言翻译(Target to Source)的学习的结合。中英翻译和英中翻译都使用初始并行数据来训练,在每次训练的迭代过程中,中英翻译系统将中文句子翻译成英文句子,从而获得新的句对,而该句对又可以反过来补充到英中翻译系统的数据集中。同理,这个过程也可以反向进行。这样双向融合不仅使得两个系统的训练数据集大大增加,而且准确率也大幅提高。
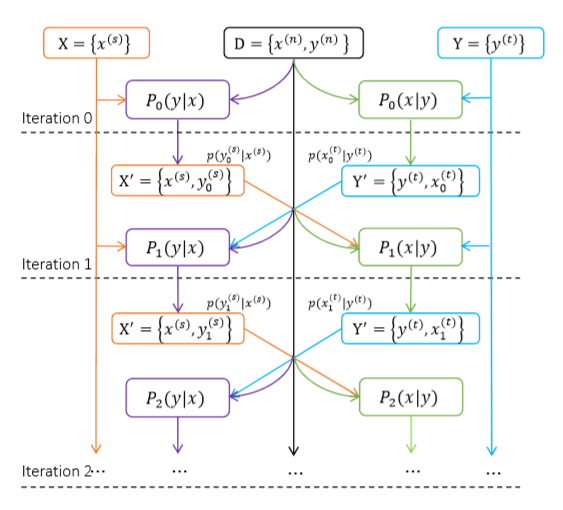
图:从源语言到目标语言翻译(Source to Target)P(y|x) 与从目标语言到源语言翻译(Target to Source)P(x|y)
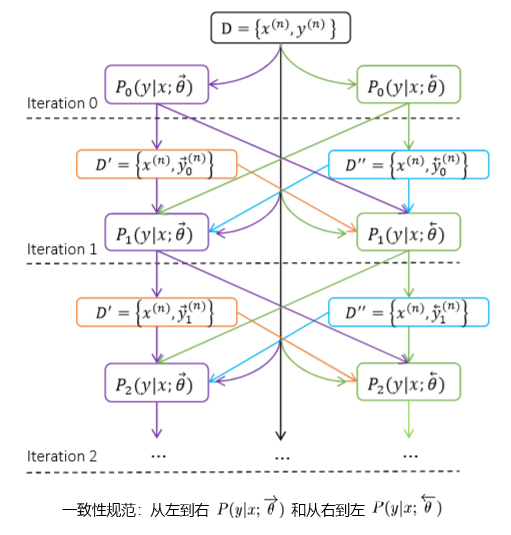
一致性规范(Agreement Regularization):
翻译结果可以从左到右按顺序产生,也可以从右到左进行生成。该规范对从左到右和从右到左的翻译结果进行约束。如果这两个过程生成的翻译结果一样,一般而言比结果不一样的翻译更加可信。这个约束,应用于神经机器翻译训练过程中,以鼓励系统基于这两个相反的过程生成一致的翻译结果。