销售过程是一个多环节的过程,哪个步骤有了过大瑕疵,都会导致业绩急剧下滑。而诊断出哪个步骤有瑕疵,除了无形的经验,还有量化的诊断方式,就是今天要讨论的主角:转化漏斗模型。
示例数据
为了详细讨论这个漏斗的实现过程,我们举一个具体的网上商城的例子,被分析的数据也不复杂,只有一个事件表:
用户ID:用户编码
事件ID:事件编码
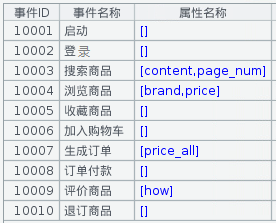
事件属性:不同事件有不同属性; json格式,{“content”:”computer”,”page_num”:1}
时间:事件发生的时间
事件类型和事件属性如下所示
需求定义
目标结果是获得某个操作流程在每个操作的客户流失率,如下图,登录的用户有20000人;其中有12000人进行了:登录->搜索商品;其中有8000人进行了:登录->搜索商品->查看商品。如下图所示:
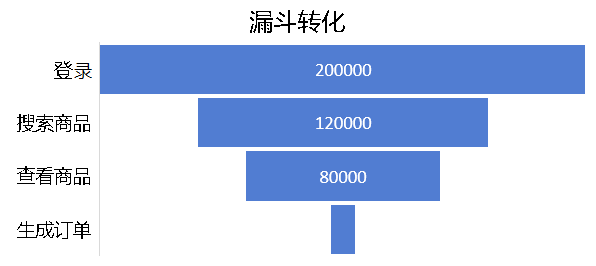
每个事件后都可能流失一些用户,整个图示就象一个漏斗形状,所以被称为漏斗转换分析。
我们来研究这个运算的一些需求点:
针对同一个用户,我们观察下面这两组数据,因为事件顺序关系,我们认为1000001用户只发生了登录行为,而1000002的三个事件符合目标顺序,到查看商品事件才流失
| 用户ID | 事件ID | 事件名称 | 时间 |
| 1000001 | 10002 | 登录 | 2017/2/3 0:01 |
| 1000001 | 10004 | 浏览产品 | 2017/2/3 0:03 |
| 1000001 | 10003 | 搜索产品 | 2017/2/3 0:08 |
| 1000001 | 10007 | 生成订单 | 2017/2/3 0:12 |
| 用户ID | 事件ID | 事件名称 | 时间 |
| 1000002 | 10002 | 登录 | 2017/2/3 0:01 |
| 1000002 | 10003 | 搜索产品 | 2017/2/3 0:03 |
| 1000002 | 10004 | 浏览产品 | 2017/2/3 0:08 |
上面这些事件,有一些事件有必然的前后关系,比如退订商品肯定发生在订单付款之后,订单付款肯定发生在生成订单之后;而收藏商品和加入购物车就不一定谁先谁后了,退订商品前也不一定发生评价商品的事件。这些不稳定性背后隐藏着用户行为,通过对一组有序事件的漏斗分析,就找到了这组行为用户在各个阶段的流失率。这是***个需求点:事件要顺序发生,且能灵活定义。
第二个需求点是能对事件属性自由定义条件,如brand=’APPLE’,price>10。
第三个需求点是定义时间段,这段时间之外的数据不在考察范围内,如2017-02-01~2017-02~28。
第四个需求点仍然是和时间有关,窗口时间,只有在窗口时间以内顺序发生的事件才符合要求,比如5分钟、3个自然天;上面图中的1000002用户在5分钟的窗口时间条件下,那只有前两个事件符合要求,因为浏览产品事件迟于登录7分钟而超出窗口时间了。
第五个需求点是每个用户只记录一次符合要求的最长事件序列。
额外多提一句,现实业务中发生的漏斗分析不一定和上面这些需求细节完全一致,完全有可能更复杂,更个性化,我们这里是为了容易说明问题而假定了这些需求细节。
算法详述
因为事件要求顺序发生,所以我们***步应该把数据先按照时间排序了,这样同一个窗口期的数据就汇聚到比较集中的一块了,而且窗口期内数据的位置也能表示先后次序了。数据量大大超出内存,用可以借用集算器的sortx对原始数据游标进行外存排序。
| A | B | |
| 1 | =file(fPath+”event.data”).cursor@t(用户ID,事件ID,事件属性,时间) | /以游标方式加载文件数据 |
| 2 | =A1.sortx(时间) | /用时间字段外存排序 |
| 3 | =file(fPath+”eventOrdered.data”).export@b(A2) | /排序结果存入目标文件 |
最终的结果只需要每个用户最长符合条件的事件序列的长度:代表该用户发生流失时的***一个事件。因为查找的过程中,不确定哪个事件序列最长,所以聚合信息里会保持住多个事件序列的信息。
events:定义目标事件顺序数组:[A,B,C,D,E],事件序号分别为1,2,3,4,5
UserList:定义空序表,每个用户的信息聚合成一条信息存入这个序表,单个用户聚合后的信息用JSON格式说明如下
- {
- 用户ID:1000001
- maxLen当前已找到的***事件序列长度:3
- seqs多个符合要求的事件序列数组:[
- {//***个事件序列
- 该事件序列的开始时间:2017-02-03 21:18:18
- ,该事件序列***事件序号:2
- },
- {//第二个事件序列
- 该事件序列的开始时间:2017-02-04 08:08:08
- ,该事件序列***事件序号:3
- },
- ……
- ]
- }
在定义了上面变量的基础上,写段伪代码来描述算法过程:
- for (按时间排好序的原始数据,循环逐条处理){
- //当前记录里四个个变量:当前用户、当前事件、当前时间,当前事件属性
- if (当前时间不在查询时间段内 || 当前事件属性不符合要求) continue;
- if (在UserList里找到当前用户){
- if (maxLen == events长度) {
- continue; //已经找到当前用户完整的目标事件序列,不用处理了,直接跳过
- } else {
- if (当前事件 == events***个事件) {
- 新建一个事件序列追加入events。
- } else {
- for(events){
- //变量:事件序列=events [i]
- if (当前事件序号 == 事件序列的***序号+1 AND 当前时间在事件序列的窗口期内 ) {
- 事件序列的***序号增加1
- if(事件序列的***序号>maxLen){
- maxLen增加1
- }
- }
- }
- }
- }
- } else {//没找到
- 新建当前用户的聚合信息,然后追加到UserList里
- }
- }
解决方案
- sql或存储过程。虽然这个计算针对单表,但过程复杂,还对数据有序性有要求,这特点就正好是sql的软肋。 能用sql写出来的人,估计是凤毛麟角,理论上能不能写出来也存疑。退一步讲,即便是写出来了,性能的可控又是一大难题。反正我是没有去细研究了,假如有研究出来的同学,可以反馈给我学习下。
- UDF?那相当于直接用高级语言硬编码了,代码量可想而知(比如用Java不会少于200行),不光写出来难度很大,以后再修改维护都是头疼的事,这种UDF又没什么通用性,需求变了就得重写。
- MapReduce以及Spark之类的东西?MapReduce对付这种有序的运算还真不好想。只是这个算法用Scala确实也写得出来,也不算太长,不过,其中的问题却是……,算了,这次先不提,以后专门细说,总之Scala是不合适。
- 想要一种能精确描述这个计算过程,并且描述方法符合人类自然思维习惯,并且能清楚知道每个步骤结果,并且能对步骤里的性能优化也能精确控制,并且代码量不大,并且代码容易复用……! 这么多贪心的“并且”,那就只能推荐这个专门处理数据的集算器脚本语言了。直接看代码
| A | B | C | D | E | |
| 1 | >begin=date( string(begin), ”yyyyMMdd”) | >end=date(string(end), ”yyyyMMdd”) | >dateWindow =eval( dateWindow) | ||
| 2 | =create(用户ID,maxLen, seqs).keys(用户ID) | =now() | |||
| 3 | =file(fPath+” event30.txt”) .cursor@t() | =A3.select(时间>=begin &&时间<end && events.pos(事件ID)>0 && ${filter}) | |||
| 4 | for C3 | >user=A2.find@b( A4.用户ID) | |||
| 5 | if user ==null | >if (A4.事件ID ==events(1),A2.insert(,A4.用户ID:用户ID,1:maxLen,[[A4.时间,1]]:seqs)) | |||
| 6 | next | ||||
| 7 | if user.maxLen ==events.len() | next | |||
| 8 | for user.seqs | >nextXh=B8(2)+1, time1=long(A4.时间), time2=long(B8(1))+dateWindow, outWindow=time1>time2, nextEvt=A4.事件ID==events(nextXh) |
if(outWindow ||!nextEvt) | next | |
| 9 | >B8(2)=nextXh, if(nextXh>user.maxLen, user.maxLen=nextXh), if(nextXh==events.len(), user.seqs=null) |
next A4 | |||
| 10 | if A4.事件ID ==events(1) | >user.seqs.insert (0,[[A4.时间,1]]), if(user.maxLen==0, user.maxLen=1) |
|||
| 11 | =[A2.len()] | for events.len()-1 | >A11.insert(0,A11(B11)- (A2.select(maxLen==B11).len())) | ||
| 12 | =interval@ms(C2, now()) |
针对单用户的聚合代码是第4~10行,规模和上面的伪代码相当,基本上就是按自然思路去写出算法。如果用Java类语言起码是10倍长度了,代码长了就要翻好几页,看到后面就会忘了前面,而集算器的代码很短,一屏就能呈现出来,整个算法过程一目了然。
如果以前没接触过集算器的话,可能会看不懂这些代码,不过没关系了,掌握任何一门语言的语法都需要一个学习过程,我稍微解释一些关键点:
变量说明:开始事件begin,结束时间end,窗口期毫秒数dateWindow,目标事件序列events,事件属性过滤条件filter。
A2:定义一个空序表,也就是伪代码中的UserList。以用户ID为主键。
A3:定义被分析数据文件的游标,这样多大的文件都能分批加载入内存进行计算了。
C3:对数据游标进行条件过滤,效果类比SQL语句里的where子句。
A4:从C3游标里循环取数据,每次取一行记录做处理。
B4:用二分法从UserList里找当前记录的用户。
第5、6行:UserList里不存在当前用户的处理分支,按照主键用户ID顺序自动找正确的位置插入。
第7行:当前用户已经找到完整目标事件序列,直接跳过。
第8~9行:已找到的多个事件序列进行循环处理,试图把当前用户信息融入某个符合条件的事件序列。融入成功,跳出到A4执行下一条;融入失败,执行第10行。
第11行:用UserList计算出每个目标事件存留的用户数,也就是漏斗需要的各层数据了。
A12:以秒为单位计算出C2执行到A12的耗时。
实现上面这个功能,无论用哪门语言,程序逻辑应该没多大变化,关键就是看方便程度。这段流程还算繁杂的程序,写完之后执行,只改了两三处小毛病就跑通了,运行到哪个格子发生什么错误;哪个格子运算后的结果是啥都会一目了然。
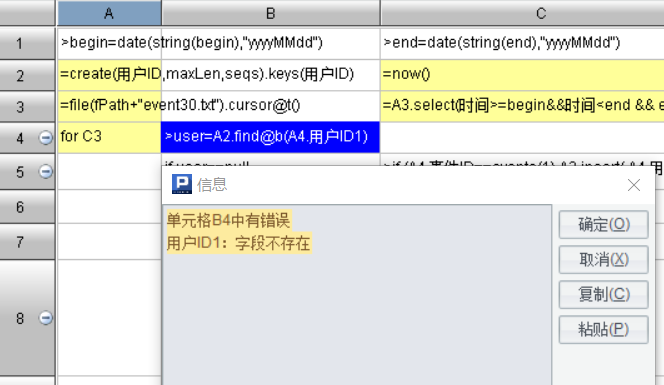
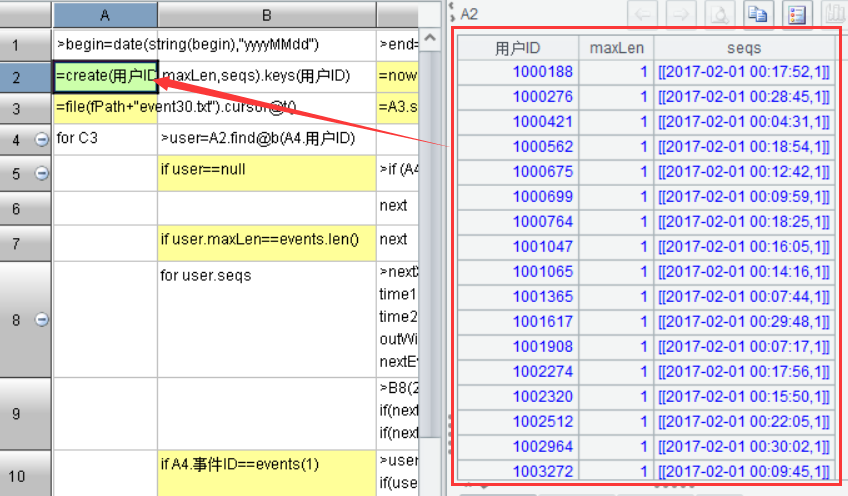
为了验证这段程序是否正确,只剩下1000001用户如下的9条数据:
| 用户ID | 事件ID | 时间 | 事件属性 |
| 1000001 | 10001 | 2017/2/3 8:11 | {} |
| 1000001 | 10002 | 2017/2/3 8:12 | {} |
| 1000001 | 10003 | 2017/2/3 8:13 | {“content”: “watch”, “page_num”: 3} |
| 1000001 | 10004 | 2017/2/3 8:14 | {“brand”: “Apple”, “price”: 2500} |
| 1000001 | 10005 | 2017/2/3 8:15 | {} |
| 1000001 | 10006 | 2017/2/3 8:16 | {} |
| 1000001 | 10007 | 2017/2/3 8:17 | {“price_all”: 3500} |
| 1000001 | 10008 | 2017/2/3 8:18 | {} |
| 1000001 | 10009 | 2017/2/3 8:19 | {“how”: -1} |
不同条件的执行结果:
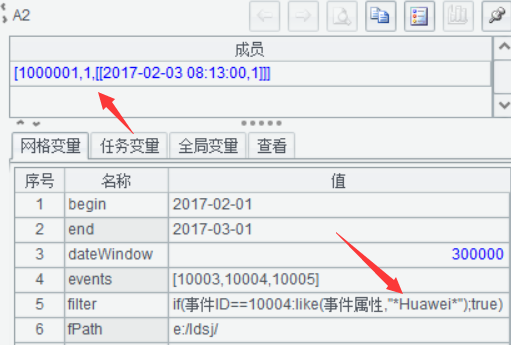
窗口期1分钟,事件序列[10003,10004,10005],算出来***事件序号是2
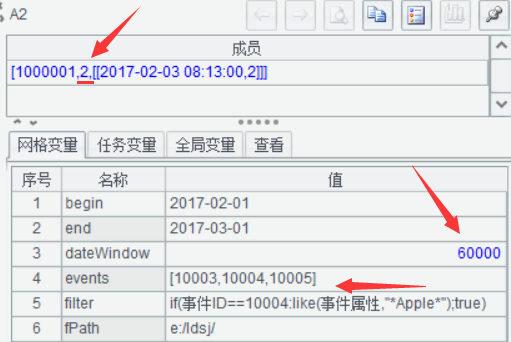
增长窗口期到5分钟,结果是3,找到了完整的目标事件序列。
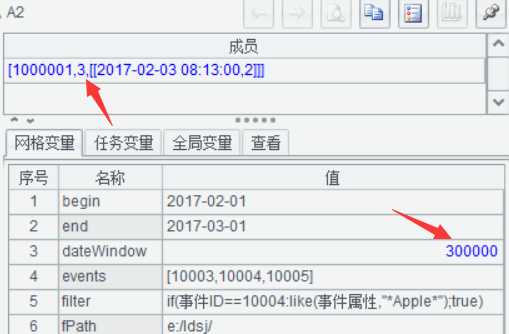
目标事件序列反序[10005,10004,10003]测试,结果是1,因为不存在这种顺序。
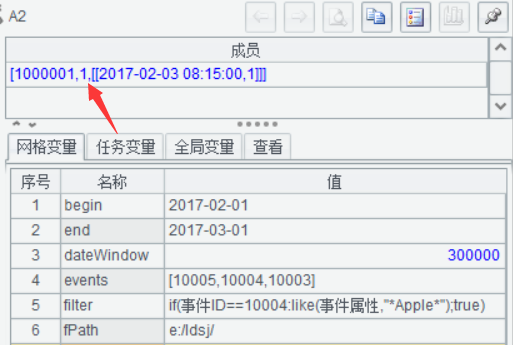
修改事件属性Huawei,结果同样为1,因为没有符合条件的10004事件
结语及预告
6万条符合条件的记录,聚合出3万个用户的事件数据,耗时1.8秒。目标数据6亿条时,性能即便是线性的也需要5个小时,还很可能不是线性的,这就不能容忍了。
理论上能完成的任务在性能不达标的情况下,等同于不能完成。实际上好些生产中的业务就因为耗不起时间和计算资源,不得不作罢。可以预告下我们已经验证了更多优化办法,不仅限于修改这段程序的逻辑,还有发生在数据预处理阶段的。正是在逐步优化、反复试错的过程中才真切体会到一个顺手工具的重要性。敬请关注!