源码下载地址:https://share.weiyun.com/a0c1664d334c4c67ed51fc5e0ac5f2b2
初学机器学习,写篇文章mark一下,希望能为将入坑者解点惑。本文介绍一些机器学习的入门知识,从安装环境到跑通机器学习入门程序MNIST demo。
内容提纲:
- 环境搭建
- 了解Tensorflow运行机制
- MNIST(手写数字识别 ) softmax性线回归
- MNIST 深度卷积神经网络(CNN)
- tools 工具类
- CPU & GPU & multi GPU
- 学习资料
1 环境搭建 (Windows)
- 安装虚拟环境 Anaconda,方便python包管理和环境隔离。
Anaconda3 4.2 https://www.anaconda.com/downloads,自带python 3.5。
- 创建tensorflow隔离环境。打开Anaconda安装后的终端Anaconda Prompt,执行下面命令
conda create -n tensorflow python=3.5 #创建名为tensorflow,python版本为3.5的虚拟环境
activate tensorflow #激活这个环境
deactivate #退出当前虚拟环境。这个不用执行
- 1.
- 2.
- 3.
CPU 版本
pip install tensorflow #通过包管理来安装
pip install whl-file #通过下载 whl 文件安装,tensorflow-cpu安装包:http://mirrors.oa.com/tensorflow/windows/cpu/tensorflow-1.2.1-cp35-cp35m-win_amd64.whl, cp35是指python3.5
- 1.
- 2.
GPU 版本。我的笔记本是技持NVIDIA显卡的,可以安装cuda,GPU比CPU快很多,不过笔记本的显存不大,小模型还可以跑,大模型建议在本地用CPU跑通,到Tesla平台上训练。

注意点:选择正确的 CUDA 和 cuDNN 版本搭配,不要只安装最新版本,tensorflow可能不支持。
目前Tensorflow已支持到CUDA 9 & cuDNN 7,之前本人安装只支持CUDA 8 & cuDNN 6,所以用是的:
CUDA8.1 https://developer.nvidia.com/cuda-80-ga2-download-archive
cudnn 6 https://developer.nvidia.com/cudnn ,将cudnn包解压,把文件放到cuda安装的对应目录中,C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0,bin对应bin,include对应include,再添加bin目录到环境变量path中。
pip install tensorflow-gpu #通过包管理来安装
pip install whl-file #http://mirrors.oa.com/tensorflow/windows/gpu/tensorflow_gpu-1.2.1-cp35-cp35m-win_amd64.whl
- 1.
- 2.
一些python工具包安装。用到啥安啥就行, pip install,不行就找源码编译安装
(tensorflow) D:\> pip install opencv-python #opencv, tensoflow 虚拟环境中
(tensorflow) D:\> pip install scipy #图片读取写入,scipy.misc.imread
(tensorflow) D:\> pip install Pillow #PIL/Pillow,这里有个坑,压缩过的PNG图,在1.x版本解析会出现透明通道质量下降,升级
- 1.
- 2.
- 3.
2 了解Tensorflow运行机制
- 上代码。注意注释说明
import tensorflow as tf
hello_world = tf.constant('Hello World!', dtype=tf.string) #常量tensor
print(hello_world) #这时hello_world是一个tensor,代表一个运算的输出
#out: Tensor("Const:0", shape=(), dtype=string)
hello = tf.placeholder(dtype=tf.string, shape=[None])#占位符tensor,在sess.run时赋值
world = tf.placeholder(dtype=tf.string, shape=[None])
hello_world2 = hello+world #加法运算tensor
print(hello_world2)
#out: Tensor("add:0", shape=(?,), dtype=string)
#math
x = tf.Variable([1.0, 2.0]) #变量tensor,可变。
y = tf.constant([3.0, 3.0])
mul = tf.multiply(x, y) #点乘运算tensor
#logical
rgb = tf.constant([[[255], [0], [126]]], dtype=tf.float32)
logical = tf.logical_or(tf.greater(rgb,250.), tf.less(rgb, 5.))#逻辑运算,rgb中>250 or <5的位置被标为True,其它False
where = tf.where(logical, tf.fill(tf.shape(rgb),1.), tf.fill(tf.shape(rgb),5.))#True的位置赋值1,False位置赋值5
# 启动默认图.
# sess = tf.Session()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())#变量初始化
result = sess.run(hello_world) #Fetch, 获取tensor运算结果
print(result, result.decode(), hello_world.eval())#`t.eval()` is a shortcut for calling `tf.get_default_session().run(t)`.
#out: b'Hello World!' Hello World! b'Hello World!' #前辍'b'表示bytestring格式,decode解成string格式
print(sess.run(hello, feed_dict={hello: ['Hello']}))
#out: ['Hello']
print(sess.run(hello_world2, feed_dict={hello: ['Hello'], world: [' World!']}))#Feed,占位符赋值
#out: [b'Hello World!']
print(sess.run(mul))
#out: [ 3. 6.]
print(sess.run(logical))
#out: [[[ True] [ True] [False]]] #rgb中>250 or <5的位置被标为True,其它False
print(sess.run(where))
#out: [[[ 1.] [ 1.] [ 5.]]] #True的位置赋值1,False位置赋值5
#sess.close()#sess如果不是用with方式定义,需要close
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- Tensor。是一个句柄,代表一个运算的输出,但并没有存储运算输出的结果,需要通过tf.Session.run(Tensor)或者Tensor.eval()执行运算过程后,才能得到输出结果。A Tensor is a symbolic handle to one of the outputs of an Operation,It does not hold the values of that operation's output, but instead provides a means of computing those values in a TensorFlow.
- Tensorflow运行过程:定义计算逻辑,构建图(Graph) => 通过会话(Session),获取结果数据。基本用法参见链接。
3 MNIST(手写数字识别 ) softmax性线回归
- 分析
MNIST是一个入门级的计算机视觉数据集,它包含各种手写数字图片:
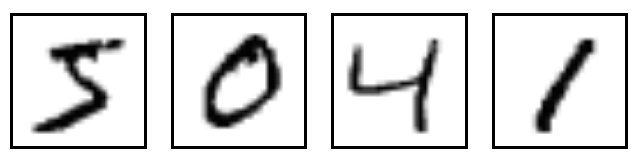
它也包含每一张图片对应的标签,告诉我们这个是数字几。比如,上面这四张图片的标签分别是5,0,4,1。
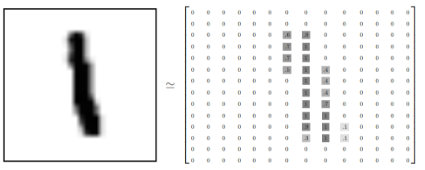
数据集图片大小28x28,单通道灰度图。存储样式如下:
MNIST手写数字识别的目的是输入这样的包含手写数字的28x28的图片,预测出图片中包含的数字。
softmax线性回归认为图片中数字是N可能性由图像中每个像素点用

表示是 数字 i 的可能性,计算出所有数字(0-9)的可能性,也就是所有数字置信度,然后把可能性最高的数字作为预测值。
evidence的计算方式如下:
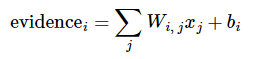
其中
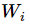
代表权重,

代表数字 i 类的偏置量,j 代表给定图片 x 的像素索引(0~28x28=784),用于像素求和。即图片每个像素值x权重之和,再加上一个偏置b,得到可能性值。
引入softmax的目的是对可能性值做归一化normalize,让所有可能性之和为1。这样可以把这些可能性转换成概率 y:
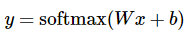
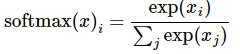
- 开始实现
数据
X样本 size 28x28 = 784
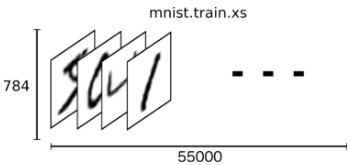
Y样本 ,样式如
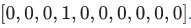
读取
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True) #total 55000,one_hot方式,图片x格式为1维数组,大小784
batch_xs, batch_ys = mnist.train.next_batch(batch_size) #分batch读取
- 1.
- 2.
- 3.
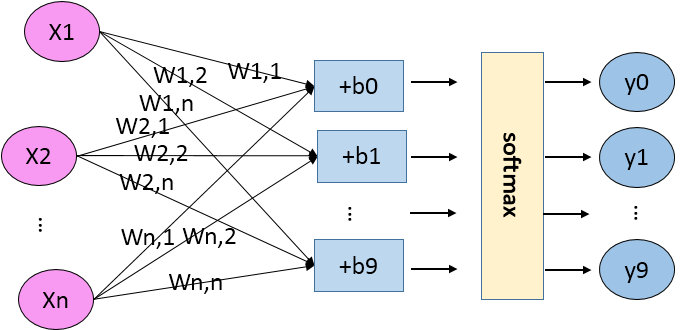
构建图(Graph)
Inference推理,由输入 x 到输出预测值 y 的推理过程
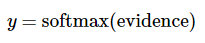

x = tf.placeholder(tf.float32, [None, 784], name="input")#None表示batch size待定
with tf.variable_scope("inference"):#定义作用域,名子inference
W = tf.Variable(tf.zeros([784, 10])) #初值为0,size 784x10
b = tf.Variable(tf.zeros([10])) #初值为0 size 10
y = tf.matmul(x, W) + b #矩阵相乘
- 1.
- 2.
- 3.
- 4.
- 5.
Loss 损失函数,分类一般采用交叉熵,这里用的是softmax交交叉熵。交叉熵是用来度量两个概率分布间的差异性信息,交叉熵公式如下:
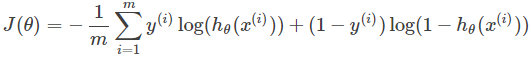
with tf.variable_scope("loss"):
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y), name="loss")
#softmax交叉熵公式: z * -log(softmax(x)) + (1 - z) * -log(1 - softmax (x)) # x: logits, z: label
- 1.
- 2.
- 3.
计算loss的方法有很多种,常见的还有L1 loss 、L2 loss、sigmoid 交叉熵、联合loss、自定义loss...
Accuracy 准确率,预测值与真实值相同的概率。矩阵相乘输出y值是一个数组,tf.argmax函数可能从数据中找出最大元素下标,预测值的最大值下标和真值的最大值下标一致即为正确。
with tf.variable_scope("accuracy"):
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)), tf.float32), name="accuracy")
- 1.
- 2.
Training 训练,训练的目的是让Loss接近最小化,预测值接近真值,Tensorflow通过优化器Optimizers来实现。在y = Wx+b中,W、b在训练之初会赋初值(随机 or 0),经过Optimizer不短优化,Loss逼近最小值,使W、b不断接近理想值。W、b一起共784x10+10个参数。
train_step = tf.train.GradientDescentOptimizer(FLAGS.learning_rate).minimize(loss)
- 1.
minimize函数:更新参数,让Loss最小化,包含两个步骤:计算梯度;更新参数。
grad_var = compute_gradients(loss) # return (gradient, variable) pairs
apply_gradients(grad_var) #沿着参数的梯度反方向更新参数,让Loss变小
- 1.
- 2.
GradientDescentOptimizer:梯度下降算法优化器, Tensorflow实现的是SGD(随机梯度下降)。其缺点是依赖当前batch,波动较大。
其它一些增强版Optimizers:参考链接。 MomentumOptimizer、AdadeltaOptimizer、AdamOptimizer、RMSPropOptimizer、AdadeltaOptimizer ...
Session:Tensorflow需要通过Session(会话)来执行推理运算,有两种创建方式,两者差别在于InteractiveSession会将自己设置为默认session,有了默认session,tensor.eval()才能执行。
sess = tf.Session()
sess = tf.InteractiveSession()
- 1.
- 2.
也可以通过下设置默认session:
with sess.as_default(): xx.eval()
with tf.Session() as sess: xx.eval()
- 1.
- 2.
配置gpu相关session参数:
sess_config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)#允许没有gpu或者gpu不足时用软件模拟
sess_config.gpu_options.allow_growth = True #动态申请显存。不加会申请全部,导致其他训练程序不能运行
#sess_config.gpu_options.per_process_gpu_memory_fraction = 0.8 #按比例申请显存
sess = tf.InteractiveSession(config=sess_config)
- 1.
- 2.
- 3.
- 4.
一个网络的训练过程是一个不断迭代(前向+反向)的过程。前向算法由前向后计算网络各层输出,反向算法由后向前计算参数梯度,优化参数,减小Loss。流程如图:
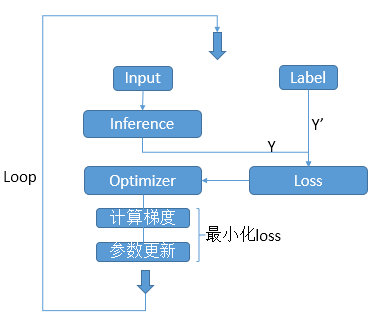
注意:每隔一段时间输出一下网络Loss和Accuracy,查看效果。每隔一段时间缓存一下网络参数,防止被突然中断,可再恢复。
模型参数的保存与恢复:
check point:默认保存方式。
pb:mobile使用。
npz:字典保存方式,{name: value}, numpy的一种保存方式。对参数按名保存,按名恢复。save和restore方法自己控制,可以选择性保存和恢复。参见附近代码中【tools.py】save_npz_dict & load_and_assign_npz_dict方法。
saver = tf.train.Saver(max_to_keep = 3, write_version = 2)
save_path = saver.save(sess, FLAGS.out_model_dir+'/model.ckpt')# check point方式
output_graph_def = tf.graph_util.convert_variables_to_constants(sess, sess.graph_def, output_node_names=['output'])#指定输出节点名称,这个需要在网络中定义
with tf.gfile.FastGFile(FLAGS.out_model_dir+'/mobile-model.pb', mode='wb') as f:
f.write(output_graph_def.SerializeToString()) #pb方式
tools.save_npz_dict(save_list=tf.global_variables(), name=FLAGS.out_model_dir+'/model.npz', sess=sess) #pnz方式
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
恢复:
#check point
saver = tf.train.Saver(max_to_keep = 3, write_version = 2)
model_file=tf.train.latest_checkpoint(FLAGS.log_dir)
if model_file:
saver.restore(sess, model_file)
#npz
tools.load_and_assign_npz_dict(name=FLAGS.log_dir+'/model.npz', sess=sess))打印网络中各参数信息:方便查看网络参数是否正确。
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
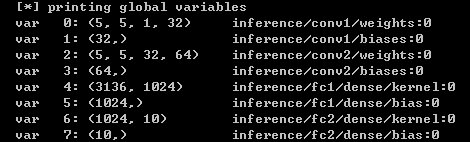
def print_all_variables(train_only=False):
if train_only:
t_vars = tf.trainable_variables()
print(" [*] printing trainable variables")
else:
t_vars = tf.global_variables()
print(" [*] printing global variables")
for idx, v in enumerate(t_vars):
print(" var {:3}: {:15} {}".format(idx, str(v.get_shape()), v.name))
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 可视化。Tensorflow提供tensorboard可视化工具,通过命令打开web服务,由浏览器查看,输入网址http://localhost:6006
tensorboard --logdir=your-log-path #path中不要出现中文
# 需要在训练过程指定相应log路径,写入相关信息
# 参考附件【sample.py】中summary、writer相关关键字代码。
- 1.
- 2.
- 3.
Graph可视化:

训练过程可视化:
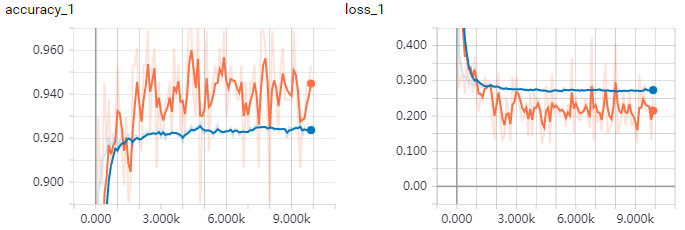
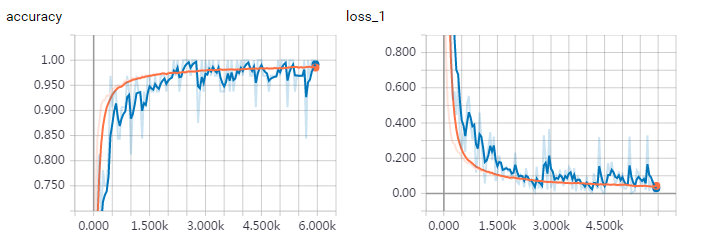
batch size = 128, 训练集,验证集。可以看到loss在收敛,accuracy在提高。由于训练集曲线反应的是当前batch的loss和accuracy,batch size相对不高,抖动较大。而验证集是全部图片进行测试,曲线较平滑。
4 MNIST深度卷积神经网络(CNN)
Softmax性线回归网络中,输出y是输入x的线性组合,即y = Wx+b,这是线性关系。在很多问题中其解法并非线性关系能完成的,在深度学习,能过能多层卷积神经网络组合非线性激活函数来模拟更复杂的非线性关系,效果往往比单一的线性关系更好。先看深度卷积神经网络(CNN,Convolutional Neural Network)构建的MNIST预测模型,再逐一介绍各网络层。
- MNIST CNN Inference推理图。从输入到输出中间包含多个网络层:reshape、conv卷积、pool池化、fc全链接、dropout。自底向上输入原始图片数据x经过各层串行处理,得到各数字分类概率预测输出y。Inference的结果转给loss用作迭代训练,图中的

可以看出用的是AdamOptimizer优化器。
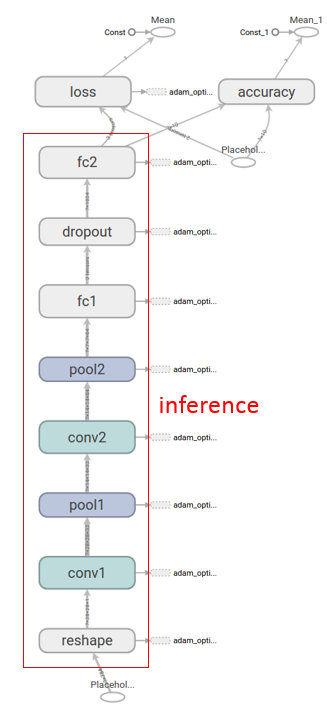
- reshape 变形,对数据的逻辑结构进行改变,如二维变四维:[1, 784] => [1, 28, 28, 1],数据存储内容未发生改变。这里由于输入数据存储的手写图片是一维数据,转成[batch_size, height, width, channels]格式
with tf.name_scope('reshape'): #scope
inputs = tf.reshape(inputs, [-1, 28, 28, 1])
#[batch_size, height, width, channels], batch size=-1表示由inputs决定,
#batch_size=inputs_size/(28x28x1)
- 1.
- 2.
- 3.
- 4.
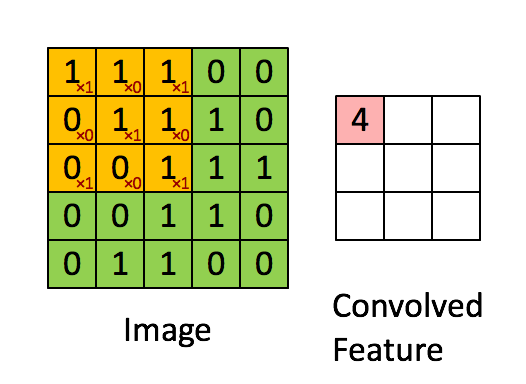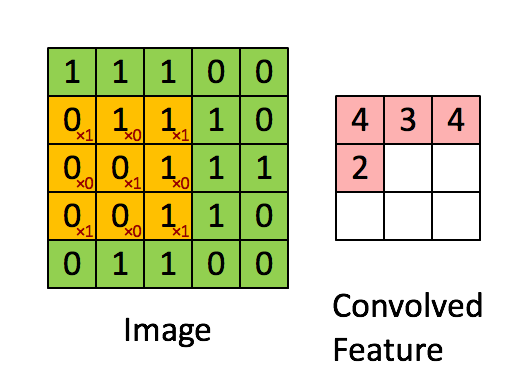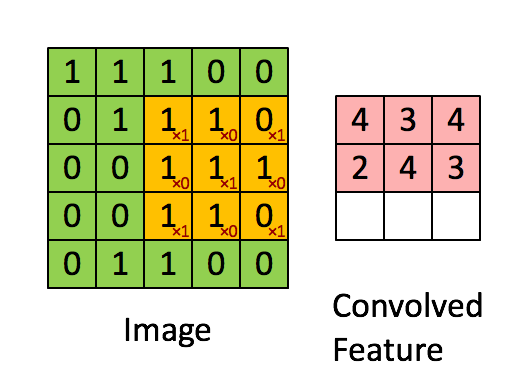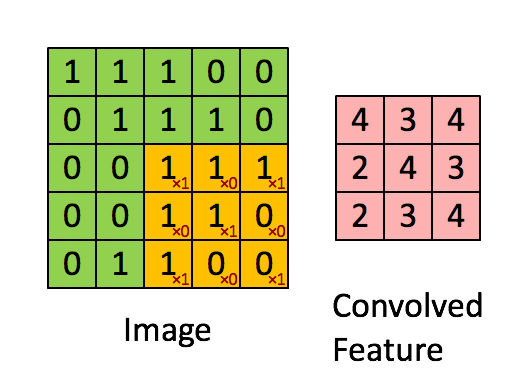
- conv2d 卷积, 卷积核(yellow)与Image元(green)素相乘,累加得到输出元素值(red)。Image的每个Channel(通道)都对应一个不同的卷积核,Channel内卷积核参数共享。所有输入channel与其kernel相乘累加多层得到输出的一个channel值。输出如有多个channel,则会重复多次,kernel也是不同的。所以会有input_channel_count * output_channel_count个卷积核。在卷积层中训练的是卷积核。
def conv2d(x, W): #W: filter [kernel[0], kernel[1], in_channels, out_channels]
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
- 1.
- 2.
tf.nn.conv2d:
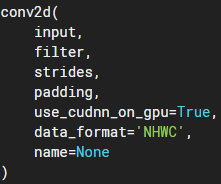
data_format: input和output数据的逻辑结构,NHWC : batch height width channel。NCHW: batch channel height width。常用的是NHWC格式;在一些输入数据中各通道数据分开存放,这种更适合NCHW。
input:输入,data_format=NHWC时,shape为batch, in_height, in_width, in_channels,Tensor。
filter:卷积核,shape为filter_height, filter_width, in_channels, out_channels,共有in_channels*out_channels个filter_height, filter_width的卷积核,输入输出channel越多,计算量越大。
strides: 步长,shape为1, stride_h, stride_w, 1,通常stride_h和stride_w相等,表示卷积核延纵横方向上每次前进的步数。上gif图stride为1。
padding:卷积计算时数据不对齐时填充方式,VALID:丢弃多余;SAME:两端补0,让多余部分可被计算。

output:输出,shape为batch, out_height, out_width, out_channels
output[b, i, j, k] =
sum_{di, dj, q} input[b, strides[1] * i + di, strides[2] * j + dj, q] *
filter[di, dj, q, k]
- 1.
- 2.
- 3.
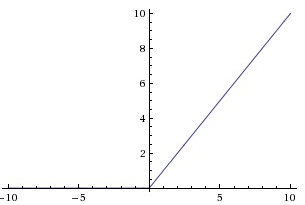
- 激活函数,与卷积搭配使用。激活函数不是真的要去激活什么,在神经网络中,激活函数的作用是能够给神经网络加入一些非线性因素,使得神经网络可以更好地解决较为复杂的问题。
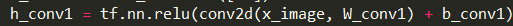
tf.nn.relu即是激活函数,对卷积输出作非线性处理,其函数如下:
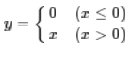
其它还有如sigmoid:
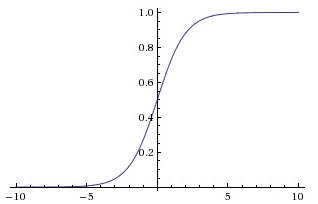
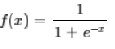
tanh:

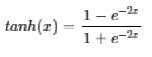
- Pool池化,有最大池化和平均值池化,计算与卷积计算类似,但无卷积核,求核所覆盖范围的最大值或平均值,输入channel对应输出channel,没有多层累加情况。输入与输出 channel数相同,输出height、width取决于strides。
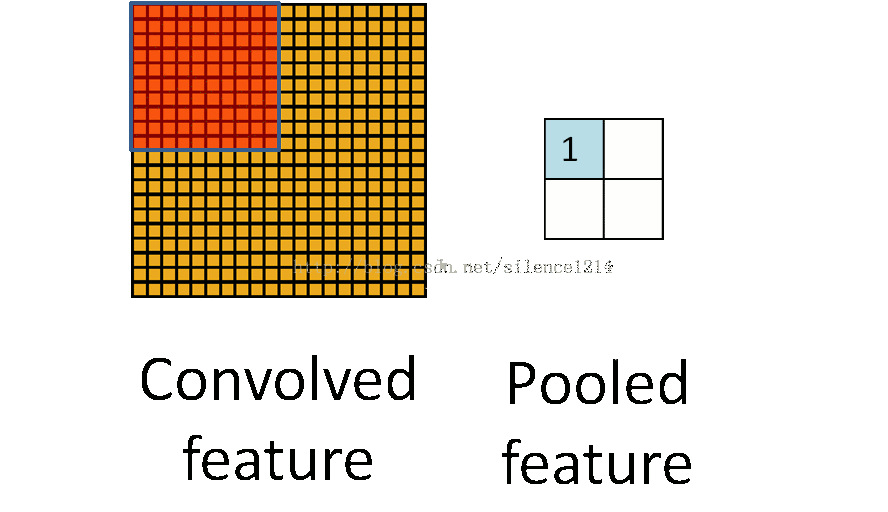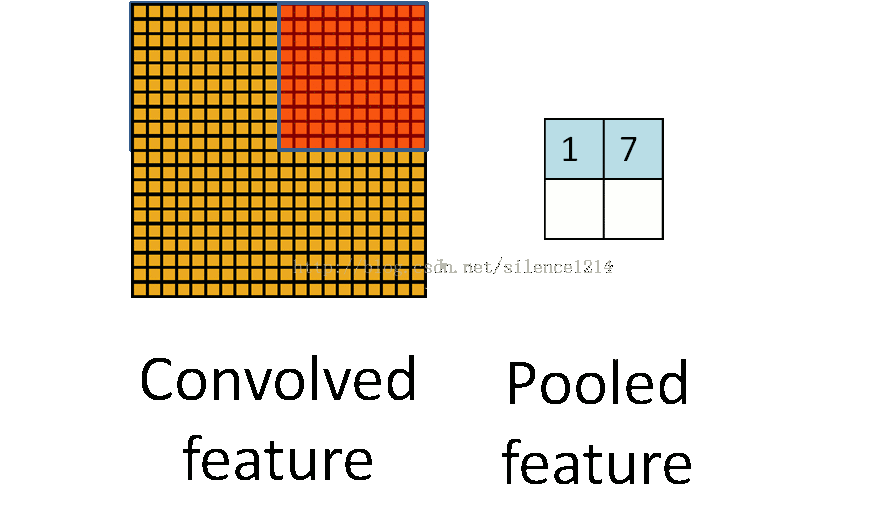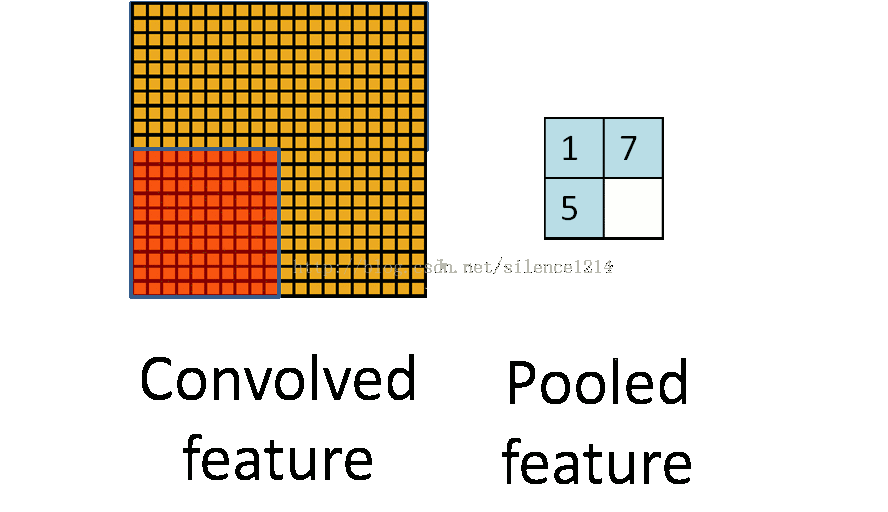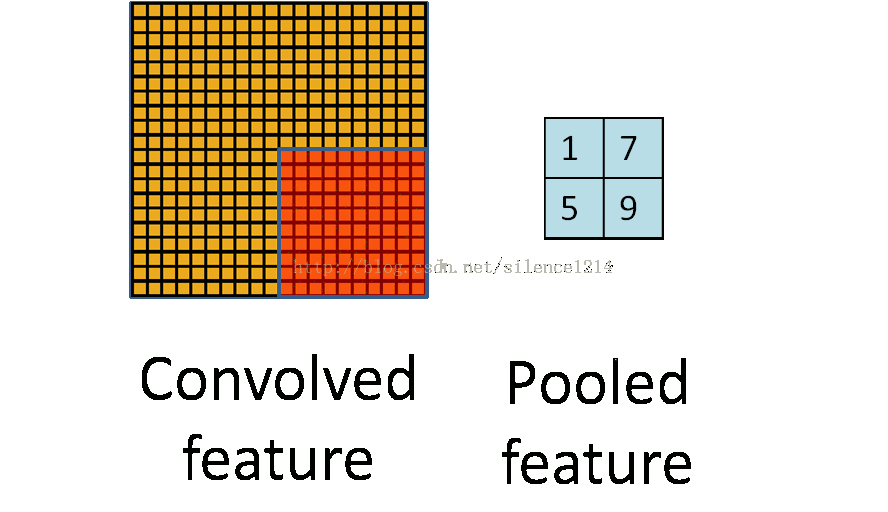
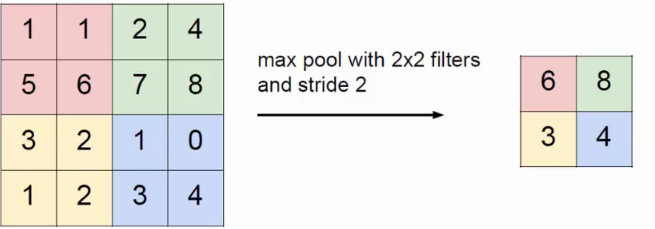
if is_max_pool:
x = tf.nn.max_pool(x, [1,kernel[0],kernel[1],1], strides=[1,stride[0],stride[1],1], padding=padding, name='pool')
else:
x = tf.nn.avg_pool(x, [1,kernel[0],kernel[1],1], strides=[1,stride[0],stride[1],1], padding=padding, name='pool')
- 1.
- 2.
- 3.
- 4.
- Dropout,随机删除一些数据,让网络在这些删除的数据上也能训练出准确的结果,让网络有更强的适应性,减少过拟合。
x = tf.nn.dropout(x, keep_prob) #keep_prob 保留比例,keep_prob=1.0表示无dropout
- 1.
- BN(batch normalize),批规范化。Inference中未标出,demo中未使用,但也是网络中很常用的一层。BN常作用在非线性映射前,即对Conv结果做规范化。一般的顺序是 卷积-> BN -> 激活函数。
BN好处:提升训练速度,加快loss收敛,增加网络适应性,一定程序的解决反向传播过程中的梯度消失和爆炸问题。详细请戳。
- FC(Full Connection)全连接,核心是矩阵相乘
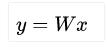
,softmax性线回归就是一个FC。在CNN中全连接常出现在最后几层,用于对前面设计的特征做加权和。Tensorflow提供了相应函数tf.layers.dense。
- 日志,下图打印了模型中需要训练的参数的shape 和 各层输出数据的shape(batch_size=1时),附件【tool.py】中有相关代码。目的是方便观自己搭的网络结构是否符合预期。
数据由[1x784] -reshape-> [1x28x28x1](batch_size, height, width, channels) -conv-> [1x28x28x32] -pool-> [1x14x14x32] -conv-> [1x14x14x64] -pool-> [1x7x7x64] -fc-> [1x1024] -fc-> [1x10](每类数字的概率)
- 训练效果,详细代码参考附件【cnn.py】
- 一个网上的可视化手写识别DEMO,http://scs.ryerson.ca/~aharley/vis/conv/flat.html
- CNN家族经典网络,如LeNet,AlexNet,VGG-Net,GoogLeNet,ResNet、U-Net、FPN。它们也都是由基本网络层元素(上述介绍)堆叠而成,像搭积木一样。
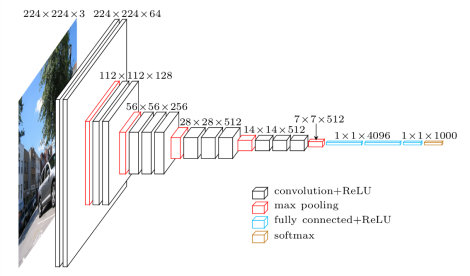
VGG,如下图,非常有名的特征提取和分类网络。由多层卷积池化层组成,最后用FC做特征融合实现分类,很多网络基于其前几层卷积池化层做特征提取,再发展自己的业务。
5 tool工具类
【tool.py】是一个自己基于tensorflow二次封装的工具类,位于附件中。好处是以后编程更方便,代码结构更好看。网上也有现成的开源库,如TensorLayer、Keras、Tflearn,自己封装的目的是更好的理解tensorflow API,自己造可控性也更强一些,如果控制是参数是否被训练、log打印。
下图是MNIST CNN网络的Inference推理代码:

6 CPU & GPU & multi GPU
- CPU, Tensorflow默认所有cpu都是/cpu:0,默认占所有cpu,可以通过代码指定占用数。
sess_config = tf.ConfigProto(device_count={"CPU": 14}, allow_soft_placement=True, log_device_placement=False)
sess_config.intra_op_parallelism_threads = 56
sess_config.inter_op_parallelism_threads = 56
sess = tf.InteractiveSession(config=sess_config)
- 1.
- 2.
- 3.
- 4.
- GPU,Tensorflow默认占用/gpu:0, 可通过指定device来确定代码运行在哪个gpu。下面
with tf.device('/device:GPU:2'):
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a')
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b')
c = tf.matmul(a, b)
#下面的代码配置可以避免GPU被占满,用多少内存占多少
sess_config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)
sess_config.gpu_options.allow_growth = True
sess_config.gpu_options.per_process_gpu_memory_fraction = 0.8
sess = tf.InteractiveSession(config=sess_config)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
多块GPU时,可以通过在终端运行下面指令来设置CUDA可见GPU块来控制程序使用哪些GPU。
export CUDA_VISIBLE_DEVICES=2,3
- 1.
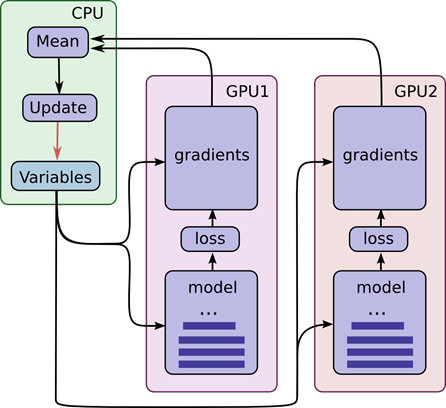
- 多GPU使用,在Tensorflow中多GPU编程比较尴尬,资料较好,代码写起比较复杂,这一点不如Caffe。
在Tensorflow中你需要自己写代码控制多GPU的loss和gradient的合并,这里有个官方例子请戳。自己也写过多GPU的工程,附件代码【tmp-main-gpus-不可用.py】可做参考,但此处不可用,来自它工程。
7 学习资料
收藏了一些机器学习相关资料,分享一下。自己也只看过很小一部分,仍在学习中....
Google最近出的机器学习速成课程 https://developers.google.cn/machine-learning/crash-course/ml-intro
斯坦福大学公开课 :机器学习课程 Andrew Ng吴恩达 http://open.163.com/special/opencourse/machinelearning.html
我爱机器学习博客 https://www.52ml.net/
晓雷机器学习笔记 https://zhuanlan.zhihu.com/xiaoleimlnote
lilicao博客 http://www.cnblogs.com/lillylin/
猫狗大战知乎专栏 https://zhuanlan.zhihu.com/alpha-smart-dog
计算机视觉,机器学习相关领域源代码大集合 https://zhuanlan.zhihu.com/p/26691794
物体检测大集合 https://handong1587.github.io/deep_learning/2015/10/09/object-detection.html#r-cnn
机器学习笔记 https://feisky.xyz/machine-learning/
原文链接:https://cloud.tencent.com/developer/article/1058521
【本文是51CTO专栏作者“云加社区”的原创稿件,转载请通过51CTO联系原作者获取授权】