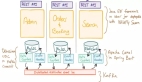
OStorage的老大李明宇随手发了一个朋友圈,是该公司企业级对象存储产品OStorage-EOS的监控界面截图,感慨一个200多TB的集群很快被用户用到了92%以上。
“外行看热闹,内行看门道”,一位做分布式存储的同仁看到了说:接近93%的存储利用率,还在不停写数据进去,说明OStorage-EOS数据分布的均匀性很好,否则,如果数据分布不够均匀,就有可能出现其他的节点或盘还有很多空间,但某一个盘或者某一个节点写满了,这时还继续写数据进去就会出问题。
那么OStorage-EOS分布式对象存储是如何让数据均匀分布到各个盘上的呢?原来是使用了一个算法叫做“一致性哈希(Consistent Hashing)”,并且在一致性哈希基础上做了改进,增加了权重、副本、机柜感知、地域感知等机制。
一致性哈希算法也是分布式系统领域的经典算法,在很多地方都有应用,下面,我们就一起来了解一下它:
哈希函数
仔细研究一致性哈希之前,我们先来了解一下基本的哈希,举个例子说明了我们如何使用哈希函数来确定对象存储在哪里。
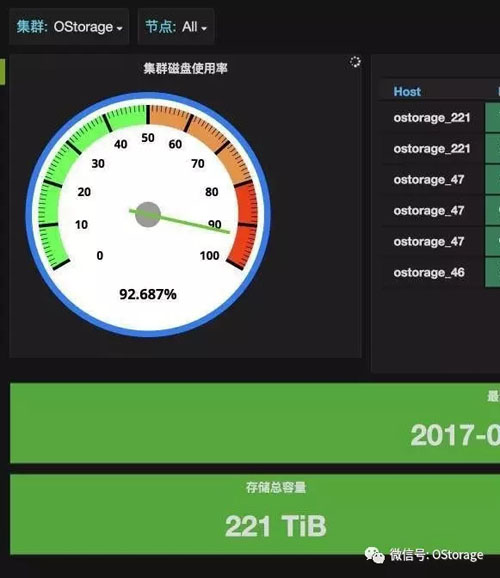
先看一个定位数据相对简单的方法,使用MD5算法来得到对象的逻辑位置的哈希值,然后除以可用的磁盘数量,得到余数。***将余数值映射到驱动器ID。
例如,对象的存储位置为 /accountA/container1/objectX ,并且使用四个磁盘来存储数据,我们称之为磁盘0到磁盘3。这里我们先计算MD5值:
- md5 -s /accountA/container1/objectX
- MD5 ("/account/container/object") =
- f9db0f833f1545be2e40f387d6c271de
然后我们用哈希值(十六进制数值)除以磁盘数,取余数(取模)。以上十六进制数值转化为十进制为:
332115198597019796159838990710599741918
取模函数在大多数编程语言中用%运算符表示:
332115198597019796159838990710599741918 % 4 = 2
因为余数是2,所以对象将被存储在磁盘2。
这种算法***的缺点是计算结果取决于除数也就是磁盘数量。任何时候添加或移除某个磁盘(除数变化了),同一个对象可能得到不同的余数,从而映射到不同的磁盘。为了说明这一点,下面的表显示了当添加磁盘时,哪一个磁盘将成为对象新的存储位置。
注意,几乎每次添加新磁盘,对象都必须移动到新的磁盘上,这仅仅一个对象的情况,将这种行为推广开来,在增加或者移除节点、磁盘时,几乎集群中的所有数据都需要进行移动。集群将不得不花费大量资源来进行这些迁移,还将产生繁重的网络负载,以及数据不可读取的情况。
一致性哈希算法
当从集群中的增加或者移除磁盘、节点时,一致性哈希(Consistent Hashing)可以减少移动的对象数量。一致性哈希不是将每个值直接映射到一个磁盘,而是通过将所有可能的哈希值建模为一个环。一致性哈希算法除了计算对象的哈希以外,还计算设备的哈希,根据磁盘的IP地址、盘符等计算哈希值,每个磁盘被映射到哈希环的某个点上,如图所示。
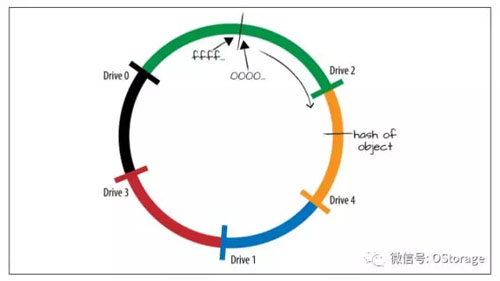
当一个对象需要被存储时,先计算对象的哈希值,然后定位到环上,如图所示“hash of object”的位置。系统按顺时针搜索环上面下一个磁盘的哈希然后定位该磁盘,用这个磁盘存储数据。上图中可以看到,对象将被存储在磁盘4。按照这种算法,哈希环上某个区间的哈希值会被映射到一个磁盘上,如图所示,我们用不同颜色表示不同区间和它们对应的磁盘,若某个对象的哈希值落在蓝色的区间内,则它会被存储在磁盘1上。
有了这样的哈希环,当我们添加一块新的磁盘时,比如磁盘5,那么图中粉色部分将不再属于磁盘4,因为这部分数据目前全部属于新的磁盘5。所以这部分位于磁盘4上的对象将会被移动到磁盘5,而其他数据均不受影响。
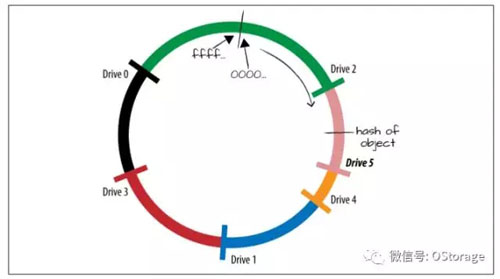
使用这种方案,添加一个盘或者一个节点,只需要移动少量数据,比前面那种最基本的依靠计算哈希值并模除来确定数据存放位置的方案要好很多,在前面那种方案中需要移动很多数据。
在实际应用的一致性哈希算法中,每个实际的磁盘或节点会对在环上对应到多个标记,这些标记在一些文献中也被成为“虚节点(Virtual Node)”,实际应用中,一个磁盘会对应很多标记/虚节点,甚至每个磁盘对应数百个标记。多个标记意味着每块磁盘对应环的哈希值范围从一个大区域切分成了数个小区域。这样做有两个效果,一个效果是一个新添加的磁盘可能从多个磁盘那里迁移对象数据,进一步降低了数据迁移的压力,另一个效果是总体的数据分布更加的平均。
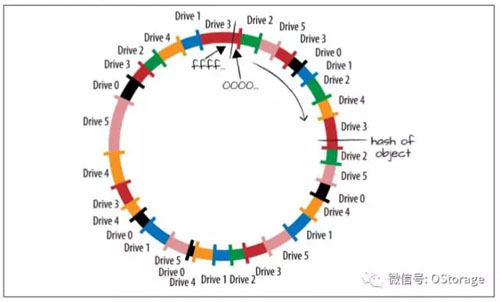
以上就是一致性哈希的基本原理,OStorage-EOS基于一致性哈希算法实现了数据的均匀分布,并加以改进,引入副本、权重、机柜感知、地域感知等机制,以满足企业级用户的需求。