Google 为了应对快速增长的数据处理,开发了一套算法。后来有人根据算法的思想,开发出开源的软件框架 ,就是Hadoop, 随着越来越多的组织和个人开发者在框架开发中不断贡献改进,Hadoop 已经形成一套家族产品,成为当下最成功***的分布式大数据处理框架。
Hadoop 受到很多组织青睐,是因为有两大因素: 一、超大规模的数据处理, 通常 10TB 以上;二、超复杂的计算工作,例如统计和模拟。
Hadoop 在很多应用场景中发挥着主要功用,如大规模统计、ETL数据挖掘、大数据智能分析、机器学习等。
Hadoop 和 传统SQL关系数据存储 有什么区别?
Hadoop 读时模式(Schema on read),传统SQL是 写时模式(Schema on write).传统数据库存储时对数据进行检查,需要检查表结构定义等必须匹配后才让存储(write),否则就报错。Hadoop 是你拿过任何数据格式我都给你存储,只要你给我读取这些数据的接口程序,在用到这些数据时(read),才会检查。

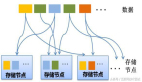
左边是Schema on Read , 右边是Schema on Write。 右边数据格式不对会报错;左边更关注读数据的规则
Hadoop 是分布式数据库, 而大部分SQL 是集中存储的。
举例来讲: 微信后台有可能数千个服务器节点用于存储微信聊天记录,假设我的聊天记录分布在60个不同的服务节点上。而对于关系数据库,会集中在多个表空间中。
假如我搜索我的一个聊天记录,Hadoop 会把搜索任务分成多个均衡负载的搜索任务运行在60个节点上。而传统SQL会逐个搜索存储空间,直到全部遍历。如果没有完全搜索完,会返回搜索结果吗? Hadoop的回答是YES,而传统SQL会是NO。
Hadoop 家族的产品 Hive,可以让不怎么懂SQL 的客户开发出基本上和SQL同样功能的查询
Hadoop 的数据写入、备份、删除操作
一、数据写入
在客户端想HDFS写数据的过程中,主要分为下面几个过程:
客户端将数据缓存到本地的一个临时文件中;
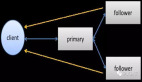
当这个本地的临时文件到达HDFS中的块大小限制时,客户端访问Namenode,Namenode将文件的名字插入到HDFS命名空间中,并且为其分配相应的存储位置;
Namenode与分配好的Datanode进行沟通,确定存储位置可用,然后将这些存储位置信息返回给客户端;
客户端将本地的临时文件传输到Datanode中;
当写文件结束,临时文件关闭时,会将已有的临时数据传输到Datanode中,并告知Namenode写数据完成;
Namenode将该文件改变为持久的一致性状态,也就事将该操作记录到日志EditLog中。如果此时Namenode宕掉,那么文件信息丢失。
上面的过程主要特点是写入数据先缓存到本地,在达到块大小限制时才与Datanode通信进行传输。这样的好处在于避免在客户写数据的过程中持续占用网络带宽,这对于处理多用户大量数据的写入是非常关键的。
二、数据备份
数据的写入同时伴随这数据块的备份,过程如下:
在客户端临时数据达到一个块时,与Namenode通信,得到一组Datanode地址,这些Datanode就是用来存储该数据块的;
客户端首先将该数据块发送到一个Datanode上,Datanode在接受时是以4kb为单位进行,我们把这些小单位称为缓存页(参考了Linux管道文件的说法);
对于***个接到数据的Datanode,它把缓存页中的数据写入自己的文件系统,另一方面,它又将这些缓存页传送给下一个Datanode;
重复3的过程,第二个Datanode又将缓存页存储在本地文件系统,同时将它传送给第三个Datanode;
如果HDFS中的备份数目设置为3,那么第三个Datanode就只需要将缓存页存储即可。
上面的过程中,数据块从客户端流向***个Datanode,然后再流向第二个,从第二个再到第三个,整个是一个流水线过程,中间不会有停顿。所以HDFS将它称为Replication Pipelining。
为什么不采取客户端同时向多个Datanode写数据的方法呢?其实从Pipelining这个称呼上就可以猜到,客户端和Datanode采用的缓存文件都是管道文件,即只支持一次读取。
三、 数据删除
HDFS中的数据删除也是比较有特点的,并不是直接删除,而是先放在一个类似回收站的地方(/trash),可供恢复。
对于用户或者应用程序想要删除的文件,HDFS会将它重命名并移动到/trash中,当过了一定的生命期限以后,HDFS才会将它从文件系统中删除,并由Namenode修改相关的元数据信息。并且只有到这个时候,Datanode上相关的磁盘空间才能节省出来,也就是说,当用户要求删除某个文件以后,并不能马上看出HDFS存储空间的增加,得等到一定的时间周期以后(现在默认为6小时)。
对于备份数据,有时候也会需要删除,比如用户根据需要下调了Replicaion的个数,那么多余的数据备份就会在下次Beatheart联系中完成删除,对于接受到删除操作的Datanode来说,它要删除的备份块也是先放入/trash中,然后过一定时间后才删除。因此在磁盘空间的查看上,也会有一定的延时。
那么如何立即彻底删除文件呢,可以利用HDFS提供的Shell命令:bin/hadoop dfs expunge清空/trash。