元数据被定义为:描述数据的数据,对数据及信息资源的描述性信息。
元数据(Metadata)是描述其它数据的数据(data about other data),或者说是用于提供某种资源的有关信息的结构数据(structured data)。元数据是描述信息资源或数据等对象的数据,其使用目的在于:识别资源;评价资源;追踪资源在使用过程中的变化;实现简单高效地管理大量网络化数据;实现信息资源的有效发现、查找、一体化组织和对使用资源的有效管理。
对于元数据的管理目前有几种常用的解决方案:中心节点管理元数据,分布式管理元数据,无元数据设计;本文谈谈三种方案的特点:
1、中心节点管理元数据
在设计分布式(存储)系统时,使用中心节点是非常简洁、清晰地一种方案,中心节点通常兼具元数据存储与查询、集群节点状态管理、决策制定与任务下发等功能;
优点:
A.由于其元数据集中式管理的特点,可以方便的处理集群运维管理的统计分析类需求;
B. 中心节点记录了用户数据的状态信息(即元数据),在扩容时,可以选择不做rebalance操作(rebalance引起的数据迁移可能带来巨大的性能开销),且仍能正常寻址;
缺点及解决方案:
a.单点故障是设计分布式系统最忌讳的问题之一,中心节点简洁的设计也带来了此问题,如何实现HA呢?;解决方案:(1)使用主备模型,主备之间使用同步或异步的方式进行增量或全量的数据同步(如TFS,mfs,HDFS2.0等),或者主备之间使用远端共享存储(如HDFS2.0,远端存储需要高可用);
b.存在性能和容量扩展上限,集中式中心节点自身硬件设施存在扩展(scale up)上限及查询式寻址方式,导致此问题;即使client缓存元数据或使用缓存集群,也不能在根本上消除上限,在某些场景下(如海量小文件),此问题仍然存在;解决方案:(1)优化升级硬件,如使用SSD,大内存等机器;(2)当面临此问题时,考虑使用分布式管理元数据方案。
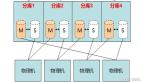
2、分布式管理元数据
和中心节点的方案相似,只是将元数据分片并使用分布式节点管理存储,在保有中心节点方案优点的同时,解决了性能和容量扩展上限的问题,同时,多个节点同时提供元数据查询服务,系统性能得到提升;
缺点
此类系统较为少见,系统本身结构复杂,实现也有一定难度;
a.系统包含两种相对独立的分布式节点:元数据节点,数据节点,它们均是带状态节点,每种节点组成的分布式模块都要面临分布式CAP原则的取舍,都要做到可扩展,尤其是元数据对一致性有着更高要求;
b.元数据节点需要共同维护数据节点的状态,并在状态变化时作出一致性的决策;这些都对系统的设计和实现构成了很大挑战;
c.另外,大量元数据所需的存储设备也是一笔不可忽略的成本开销;
上面两种方案有着共同思想:记录并维护数据的状态(即元数据),数据寻址时先向元数据服务器查询,再存取实际数据;
3、无元数据设计
主要以ceph为例,有别于上述二者的思想,此类系统的主要思想:使用算法计算寻址,寻址算法的输入参数之一为集群状态(如数据节点分布拓扑,权重,进程状态等)的某种形式描述,此类常见算法有consistent hashing,Ceph RADOS系统的CRUSH算法,这类算法通常不直接管理用户数据,而是引入中间一层逻辑分片结构(如consistent hashing的环片段,ceph的placement group),其粒度更大,其数量有限且相对固定,用户存取的数据隶属于其中唯一一个分片中,系统通过管理维护这些分片进而管理维护用户数据;此类系统有的也有中心配置管理节点(如ceph rados的monitor),只提供集群和分片等重要状态的管理维护,不提供元数据的存储查询;
优点:
A.如前所述,系统只需管理维护逻辑分片与集群状态等信息,不存储管理用户数据的元数据,系统的可扩展性大大增强,这在大量元数据场景时尤为明显;
B.寻址算法所需的参数数据量小且相对固定,client可以通过缓存的方式,达到若干client并行寻址的目的,避免了寻址性能瓶颈;
缺点分析:
a.集群扩容时(甚至权重改变时),需要做rebalance,尤其是数据规模很大(PB级以上)的集群,由此带来的大量数据迁移使集群一直处于高负载的状态,进而使得正常业务请求的延时、iops等性能指标下降;但有些场景做集群扩容时,并不希望做rebalance(如集群容量不足);对此,常见策略是每个集群预先做好性能、容量评估,需要扩容时,直接新建集群;如果单个集群必须做rebalance,通过人工干预限流降低集群负载;至于需要做rebalance的根本原因,本人认为扩容导致集群状态改变,进而导致寻址算法结果改变,最终数据分布也需随之改变;
b.数据的副本分布位置通过寻址算法计算得出,位置相对固定,几乎不可人为调整;但通常可以通过改变权重的方式改变数据总体分布情况;
c.中心配置管理节点只管理分片信息,不知道单个用户数据的信息,统计分析类的需求需要通过定期地收集数据节点信息等方式实现,并存储维护。
总结:通过以上比较分析,三类系统的寻址策略,使系统本身均有自己相应的优缺点,它们都不是***的,但都有其适宜的场景和业务,在系统设计与选型时,需要做全面的考量。