最近有朋友问关于区块链用于存储应用的话题,其实一定要清楚存储和存证的关系,简而言之区块链适合做存储的存证,并不适合做分布式的存储用,为了搞清楚这个问题,今天我们来看看一个分布式存储的代表Ceph是什么样子的,也就说明了区块链技术是否适合于作为存储出现。
Ceph是加州大学Santa Cruz分校的Sage Weil(DreamHost的联合创始人)专为博士论文设计的新一代自由软件分布式文件系统。自2007年毕业之后,Sage开始全职投入到Ceph开 发之中,使其能适用于生产环境。Ceph的主要目标是设计成基于POSIX的没有单点故障的分布式文件系统,使数据能容错和无缝的复制。
Ceph设计目标
开发一个分布式文件系统需要多方努力,但是如果能准确地解决问题,它就是无价的。Ceph 的目标简单地定义为:
- 可轻松扩展到数 PB 容量
- 对多种工作负载的高性能(每秒输入/输出操作[IOPS]和带宽)
- 高可靠性
不幸的是,这些目标之间会互相竞争(例如,可扩展性会降低或者抑制性能或者影响可靠性)。Ceph 开发了一些非常有趣的概念(例如,动态元数据分区,数据分布和复制),这些概念在本文中只进行简短地探讨。Ceph 的设计还包括保护单一点故障的容错功能,它假设大规模(PB 级存储)存储故障是常见现象而不是例外情况。最后,它的设计并没有假设某种特殊工作负载,但是包括适应变化的工作负载,提供最佳性能的能力。它利用 POSIX 的兼容性完成所有这些任务,允许它对当前依赖 POSIX 语义(通过以 Ceph 为目标的改进)的应用进行透明的部署。最后,Ceph 是开源分布式存储,也是主线 Linux 内核(2.6.34)的一部分。
Ceph 架构
现在,让我们探讨一下 Ceph 的架构以及高端的核心要素。然后我会拓展到另一层次,说明 Ceph 中一些关键的方面,提供更详细的探讨。
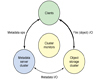
Ceph 生态系统可以大致划分为四部分(见图 1):客户端(数据用户),元数据服务器(缓存和同步分布式元数据),一个对象存储集群(将数据和元数据作为对象存储,执行其他关键职能),以及最后的集群监视器(执行监视功能)。
图 1. Ceph 生态系统的概念架构
如图 1 所示,客户使用元数据服务器,执行元数据操作(来确定数据位置)。元数据服务器管理数据位置,以及在何处存储新数据。值得注意的是,元数据存储在一个存储集群(标为 “元数据 I/O”)。实际的文件 I/O 发生在客户和对象存储集群之间。这样一来,更高层次的 POSIX 功能(例如,打开、关闭、重命名)就由元数据服务器管理,不过 POSIX 功能(例如读和写)则直接由对象存储集群管理。
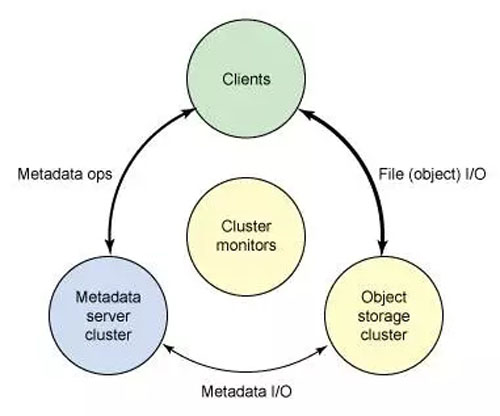
另一个架构视图由图 2 提供。一系列服务器通过一个客户界面访问 Ceph 生态系统,这就明白了元数据服务器和对象级存储器之间的关系。分布式存储系统可以在一些层中查看,包括一个存储设备的格式(Extent and B-tree-based Object File System [EBOFS] 或者一个备选),还有一个设计用于管理数据复制,故障检测,恢复,以及随后的数据迁移的覆盖管理层,叫做 Reliable Autonomic Distributed Object Storage(RADOS)。最后,监视器用于识别组件故障,包括随后的通知。
图 2. Ceph 生态系统简化后的分层视图
Ceph 组件
了解了 Ceph 的概念架构之后,您可以挖掘到另一个层次,了解在 Ceph 中实现的主要组件。Ceph 和传统的文件系统之间的重要差异之一就是,它将智能都用在了生态环境而不是文件系统本身。
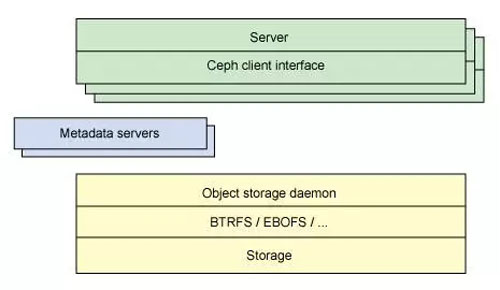
图 3 显示了一个简单的 Ceph 生态系统。Ceph Client 是 Ceph 文件系统的用户。Ceph Metadata Daemon 提供了元数据服务器,而 Ceph Object Storage Daemon 提供了实际存储(对数据和元数据两者)。最后,Ceph Monitor 提供了集群管理。要注意的是,Ceph 客户,对象存储端点,元数据服务器(根据文件系统的容量)可以有许多,而且至少有一对冗余的监视器。那么,这个文件系统是如何分布的呢?
图 3. 简单的 Ceph 生态系统
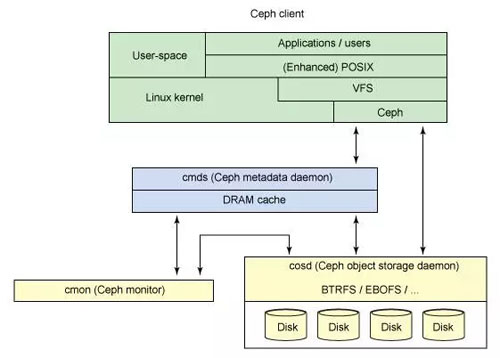
Ceph 客户端
因为 Linux 显示文件系统的一个公共界面(通过虚拟文件系统交换机 [VFS]),Ceph 的用户透视图就是透明的。管理员的透视图肯定是不同的,考虑到很多服务器会包含存储系统这一潜在因素(要查看更多创建 Ceph 集群的信息,见 参考资料 部分)。从用户的角度看,他们访问大容量的存储系统,却不知道下面聚合成一个大容量的存储池的元数据服务器,监视器,还有独立的对象存储设备。用户只是简单地看到一个安装点,在这点上可以执行标准文件 I/O。
Ceph 文件系统 — 或者至少是客户端接口 — 在 Linux 内核中实现。值得注意的是,在大多数文件系统中,所有的控制和智能在内核的文件系统源本身中执行。但是,在 Ceph 中,文件系统的智能分布在节点上,这简化了客户端接口,并为 Ceph 提供了大规模(甚至动态)扩展能力。
Ceph 使用一个有趣的备选,而不是依赖分配列表(将磁盘上的块映射到指定文件的元数据)。Linux 透视图中的一个文件会分配到一个来自元数据服务器的 inode number(INO),对于文件这是一个唯一的标识符。然后文件被推入一些对象中(根据文件的大小)。使用 INO 和 object number(ONO),每个对象都分配到一个对象 ID(OID)。在 OID 上使用一个简单的哈希,每个对象都被分配到一个放置组。放置组(标识为 PGID)是一个对象的概念容器。最后,放置组到对象存储设备的映射是一个伪随机映射,使用一个叫做 Controlled Replication Under Scalable Hashing(CRUSH)的算法。这样一来,放置组(以及副本)到存储设备的映射就不用依赖任何元数据,而是依赖一个伪随机的映射函数。这种操作是理想的,因为它把存储的开销最小化,简化了分配和数据查询。
分配的最后组件是集群映射。集群映射 是设备的有效表示,显示了存储集群。有了 PGID 和集群映射,您就可以定位任何对象。
Ceph 元数据服务器
元数据服务器(cmds)的工作就是管理文件系统的名称空间。虽然元数据和数据两者都存储在对象存储集群,但两者分别管理,支持可扩展性。事实上,元数据在一个元数据服务器集群上被进一步拆分,元数据服务器能够自适应地复制和分配名称空间,避免出现热点。如图 4 所示,元数据服务器管理名称空间部分,可以(为冗余和性能)进行重叠。元数据服务器到名称空间的映射在 Ceph 中使用动态子树逻辑分区执行,它允许 Ceph 对变化的工作负载进行调整(在元数据服务器之间迁移名称空间)同时保留性能的位置。
图 4. 元数据服务器的 Ceph 名称空间的分区
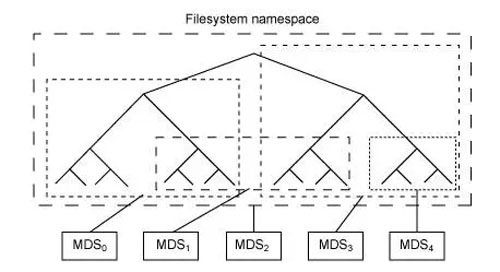
但是因为每个元数据服务器只是简单地管理客户端人口的名称空间,它的主要应用就是一个智能元数据缓存(因为实际的元数据最终存储在对象存储集群中)。进行写操作的元数据被缓存在一个短期的日志中,它最终还是被推入物理存储器中。这个动作允许元数据服务器将最近的元数据回馈给客户(这在元数据操作中很常见)。这个日志对故障恢复也很有用:如果元数据服务器发生故障,它的日志就会被重放,保证元数据安全存储在磁盘上。
元数据服务器管理 inode 空间,将文件名转变为元数据。元数据服务器将文件名转变为索引节点,文件大小,和 Ceph 客户端用于文件 I/O 的分段数据。
Ceph 监视器
Ceph 包含实施集群映射管理的监视器,但是故障管理的一些要素是在对象存储本身中执行的。当对象存储设备发生故障或者新设备添加时,监视器就检测和维护一个有效的集群映射。这个功能按一种分布的方式执行,这种方式中映射升级可以和当前的流量通信。Ceph 使用 Paxos,它是一系列分布式共识算法。
Ceph 对象存储
和传统的对象存储类似,Ceph 存储节点不仅包括存储,还包括智能。传统的驱动是只响应来自启动者的命令的简单目标。但是对象存储设备是智能设备,它能作为目标和启动者,支持与其他对象存储设备的通信和合作。
从存储角度来看,Ceph 对象存储设备执行从对象到块的映射(在客户端的文件系统层中常常执行的任务)。这个动作允许本地实体以最佳方式决定怎样存储一个对象。Ceph 的早期版本在一个名为 EBOFS 的本地存储器上实现一个自定义低级文件系统。这个系统实现一个到底层存储的非标准接口,这个底层存储已针对对象语义和其他特性(例如对磁盘提交的异步通知)调优。今天,B-tree 文件系统(BTRFS)可以被用于存储节点,它已经实现了部分必要功能(例如嵌入式完整性)。
因为 Ceph 客户实现 CRUSH,而且对磁盘上的文件映射块一无所知,下面的存储设备就能安全地管理对象到块的映射。这允许存储节点复制数据(当发现一个设备出现故障时)。分配故障恢复也允许存储系统扩展,因为故障检测和恢复跨生态系统分配。Ceph 称其为 RADOS(见 图 3)。
其他分布式文件系统
Ceph 在分布式文件系统空间中并不是唯一的,但它在管理大容量存储生态环境的方法上是独一无二的。分布式文件系统的其他例子包括 Google File System(GFS),General Parallel File System(GPFS),还有 Lustre,这只提到了一部分。Ceph 背后的想法为分布式文件系统提供了一个有趣的未来,因为海量级别存储导致了海量存储问题的唯一挑战。