1.前情提要
经过一番努力,张大胖和Bill成功地实现了一个分布式的文件系统:HDFS。
(参见《HDFS的诞生》)。
这个系统可以把大文件分成一个个片段,分散地存储在各个服务器上,每个片段还额外有2个或多个备份。
虽然把文件分了片,但在客户端软件看来,仍然是对一个文件进行操作, 并不知道HDFS在背后搞的“伎俩”。
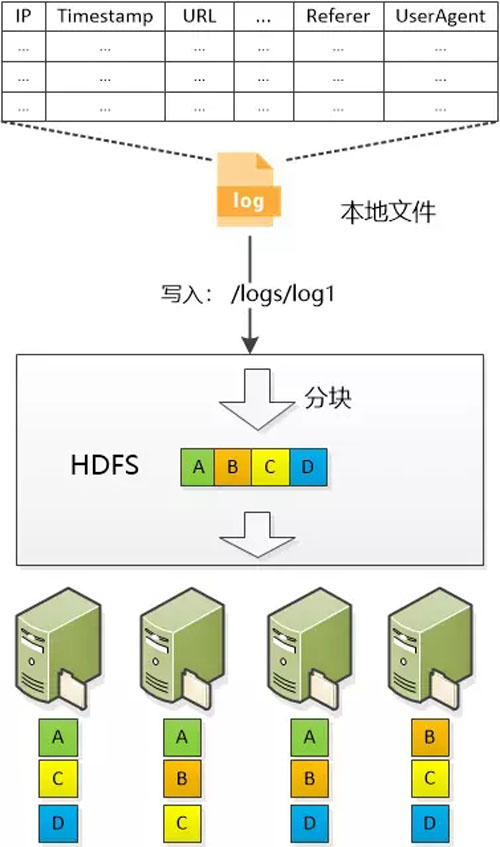
于是张大胖便把海量的Web日志文件存储到了HDFS当中。
2.并行计算
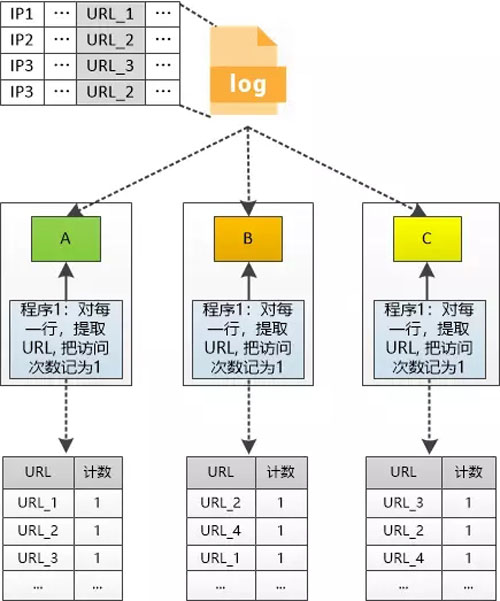
张大胖决定先使用HDFS完成一个小目标: 统计每个URL被访问了多少次。
刚一开始,就遇到了棘手的问题:数据量太大,如果只有一台机器读出所有文件,在同一台机器上进行处理,还是慢得要死。
师傅Bill说:“我们在编程中有个非常重要的思想就是‘Divide and Conquer’,现在就可以用到这里来了。”
“分而治之? ” 张大胖说,“我们不是已经把文件分而治之,变成分片,放到不同机器上了吗?”
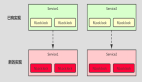
“那只是数据,现在我们让计算程序也分布式,并且要尽可能地让计算靠近数据,降低网络流量的开销!比如你的小目标,是为了统计URL的访问次数,我们就把这个计算程序发到每个分片所在的机器上,然后在每个机器上并行地做计算, 像这样:“
“虽然是并行计算, 但是计算出来的结果还是杂乱无章啊,有什么用?”
“你想想,要是把他们按URL分下组呢?” Bill 说。
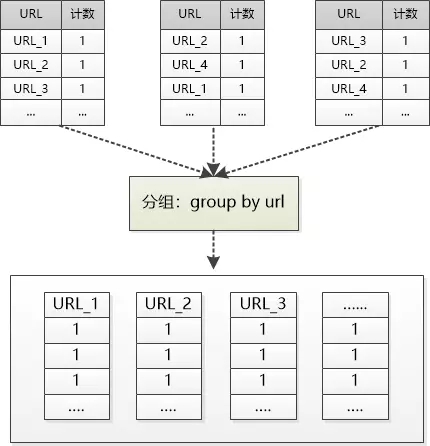
(注:正式的术语不叫group by ,叫shuffle。)
“奥,明白,这么做以后,数据之间互相独立, 又可以并行计算了!”
张大胖接着Bill的图继续往下画:
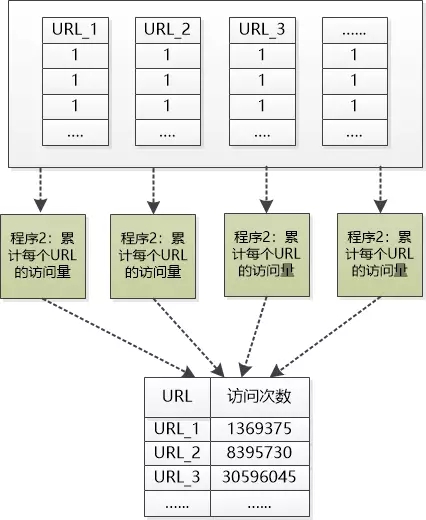
“对,这样一来我们的计算也变成分布式的了,并且每个程序都比较简单, 程序1的职责是:把该分片中的URL给提取出来,记一个数。 程序2的职责是累计每个URL的访问量。 ” Bill 说道。
3.深入讨论
“有意思,看来保持程序的并行执行是关键,我注意到一个现象,那就是程序1和程序2都不维护内部状态,他们就像一个函数,根据输入进行计算,输出结果,就这么简单。”
“ 只有这样,才有***的灵活性嘛,程序1的各个副本之间不互相依赖, 程序2也会如此, 所以我们才能把程序1和程序2部署到任意一台机器上去运行。” Bill说。
“还有, 程序1的输出为什么把每个URL访问量都记为1呢?我们为什么不能把属于同一个URL的访问量在那个节点上先做个求和呢?”
“对于我们这个简单的情况,是可以先求和,然后发给第二个程序继续统计,也没有什么错误, 但是对于其他情况,例如求平均数,那就不能先做平均了,得留给第二个程序去做,不然就错了。”
张大胖心里盘算了一下,假设有三个数字,a= 20,b=10,c = 30, 他们三个的平均数是20 ,但是如果先计算a+b的平均数,再和c 进行平均,即((a+b)/2 + c)/2,结果是22.5,就和之前不一样了。
“你说过分布式很麻烦,我想到一个问题,如果某个程序没运行完就死翘翘了,或者那个程序所在的机器down掉了,怎么办呢?”
“魔鬼都是在细节当中,一遇到异常分支,我们的程序就变得异常复杂。 很明显,我们得跟踪每个程序的状态,如果发现它不可用了,就得在另外一个机器上重新运行它。 我们甚至可以故意多开几个程序,让他们竞争,谁运行得最快,就以谁的结果为准。”
“唉,这么多事情,看来又得弄个框架来处理了!” 张大胖感慨道。
“那是自然,什么是框架? 框架自然是把基础设施做好,把重复的工作都做了,让用户写的程序越简单越好,我们的框架会把程序1和程序2分布到各个机器上并行运行,还会监控他们的状态。 还有那个所谓的分组操作,也得我们处理,所以这必然是个框架,我想可以把它叫做MapReduce。”
4.MapReduce
“MapReduce? 就是你上次给我说的那个东西? ”
“对啊, 如果我们把程序1称为Mapper, 把程序2称为Reducer,那合起来不就是MapReduce 了。 ” Bill笑着说道。
“怎么会起了这么一个古怪的名字呢?” 张大胖撇撇嘴。
“Map 和 Reduce最早是函数式编程中的概念,所谓map ,就是这个样子: ”
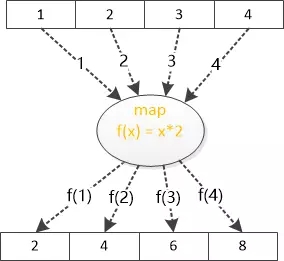
张大胖说:“不就是把一个函数施加到一组数据上,把它变成另外一组数据嘛!”
“是啊,map 在广义上来讲,就是数据的变换,把一个数据变成另外一个, 回到我们的例子,我们的程序1接收的输入其实就是一行行的日志记录,对每一行日志,程序1从中提取URL,变换成另外一个结构:(URL, 1), 输出给后续处理。所以也是一种map操作。”
“那reduce 呢?”
“reduce 就是给定一个函数和初始值,每次对列表中的一个元素调用该函数,不断地“折叠”一个列表,最终把它变成一个值,以最简单的求和为例,如果初始值为0 , 列表是[1,2,3,4],计算过程如下:
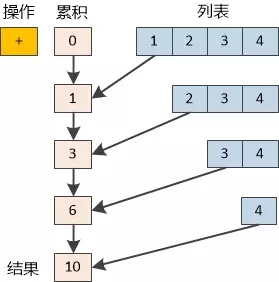
“明白了,思想虽然很简单, 但应用到我们的HDFS当中,让程序并行化运行, 威力巨大啊!”

【本文为51CTO专栏作者“刘欣”的原创稿件,转载请通过作者微信公众号coderising获取授权】