本文分享的是微信运维监控系统的具体设计实践。在分享开始之前,我们先看如下图中微信后台系统的现状。
面对庞大的调用量及复杂的调用链路,单靠人力难以维护,只能依赖一个全方位监控、稳定、快速的运维监控系统。

我们的运维监控系统主要有三个功能:
- 故障报警
- 故障分析和定位
- 自动化策略
今天我们的分享主题,主要有以下三部分:
- 监控数据收集轻量化
- 微信数据监控的发展过程
- 海量监控分析下的数据存储设计思路
监控数据收集轻量化
先看一下常见的数据收集流程,一般从日志里面采集,然后本地汇总打包,再发到全局服务器里面汇总。
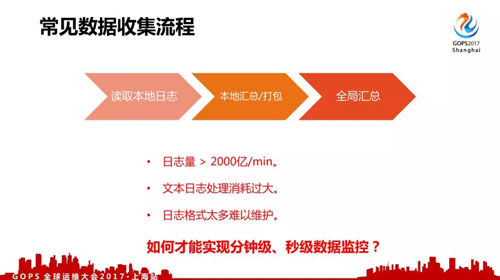
但是对于微信来说,200w/min 调用量产生的是 2000亿/min 的监控数据上报,这个还是比较保守的估计数据。
早期我们使用过自定义文本类型日志上报,但由于业务及后台服务非常多,日志格式增长非常快,难以持续进行维护,而且不管是 CPU、网络、存储、统计都出现非常大的压力,难以保证监控系统本身的稳定。
为了实现稳定的分钟级、甚至秒级的数据监控,我们进行了一系列改造。
对于我们内部监控数据处理分为两个步骤:
- 数据分类
- 定制处理策略
我们对数据进行分类,在我们内部来说有三种数据:
- 实时故障监控分析。
- 非实时数据统计,比如说业务报表等。
- 单用户异常分析,比如说用户一个报障过来还要单独对用户故障进行分析。
下面先简单介绍一下非实时数据统计及单用户异常分析,再重点介绍实时监控数据的处理。
非实时数据
对于非实时数据来说,我们有一个配置管理页面。
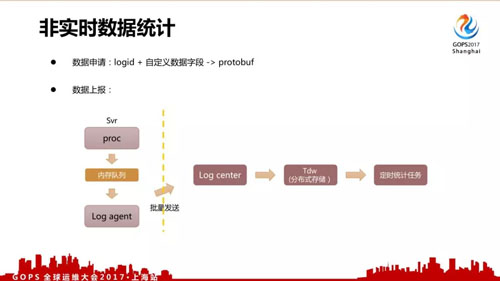
用户在上报的时候会先申请 logid + 自定义数据字段,上报并非使用写日志文件的方式,而是采用共享内存队列、批量打包发送的方式减少磁盘 IO、日志服务器的调用压力。统计使用分布式统计,目前已经是常规做法。
单用户异常分析
对于单个用户异常分析来说,我们关注的是异常,所以上报路径跟刚才非实时的路径比较相近。
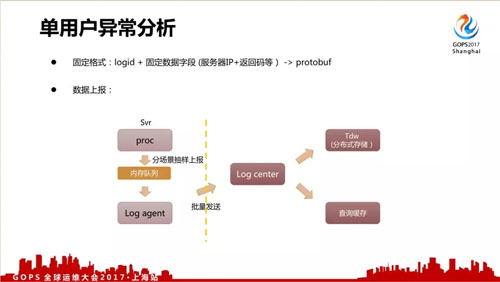
采用固定的格式: logid + 固定数据字段(服务器 IP+返回码等)。
数据上报量比刚才的非实时日志还要大很多,所以我们是抽样上报的,除了把数据存入到 Tdw 分布式存储里面,还会把它转发到另外一个缓存里面进行一个查询缓存。
实时监控数据
实时监控数据是重点分享的部分,这部分数据也是 2000亿/min 日志上报中的绝大多数。
为了实现分方位的监控,我们的实时监控数据也有很多种类型,其格式、来源、统计方式都有差异。
为了实现快速稳定的数据监控,我们对数据进行了分类,然后针对性的对各类数据进行简化、统一数据格式,再对简化后的数据采取***的数据处理策略。
对我们数据来说,我们觉得有下面几种:
- 后台数据监控,用于微信后台服务的监控数据。
- 终端数据监控,除了后台,我们还需要关注终端方面具体的性能、异常监控及网络异常。
- 对外监控服务,我们现在有商户和小程序等外部开发者提供的服务,我们及外部服务开发者都需要知道这个服务和我们微信之间有些怎么样的异常,所以我们还提供了对外的监控服务。
后台数据监控
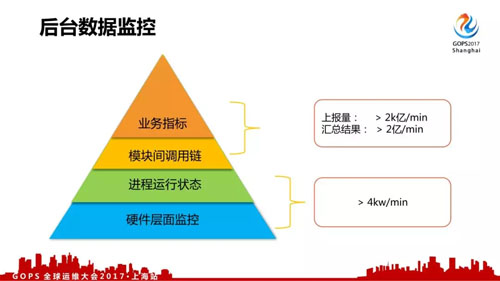
对于我们后台数据监控来说,我们觉得按层次来说分成四类,每种有不同的格式和上报方式:
- 硬件层面监控,比如服务器负载、CPU、内存、IO、网络流量等。
- 进程运行状态,比如说消耗的内存、CPU、IO 等。
- 模块间调用链,各个模块、机器间的调用信息,是故障定位的关键数据之一。
- 业务指标,业务总体层面上的数据监控。
不同类型的数据简化成如下格式,方便对数据进行处理。其中底下两层都用 IP+Key 的格式,后来出现了容器后,使用 ContainerID、IP、Key 的格式。
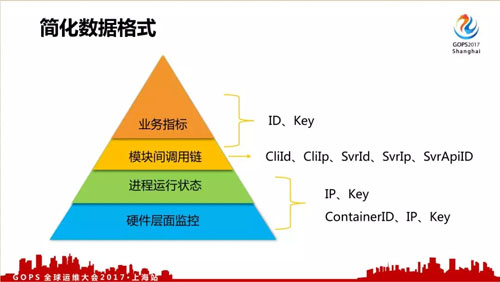
而模块调用信息,又把模块的被调总体信息抽出来,跟业务指标共用 ID、Key 的数据格式。
我们重点说一下 IDKey 数据。这个 IDKey 数据是早期的重点监控数据,但其上报量占了数据上报的 9 成以上,像刚才所说,用文本型数据上报难以做到稳定、快速。
所以我们定制了一个非常简化、快速的上报方式,直接在内存进行快速汇总,具体上报方案可以看下面这个图。

每个机器里面都申请了两块共享内存,有两块的原因是方便进行周期性的数据收集(6s 收集一次),每块内存的格式是:uint32_t[MAX_ID][MAX_KEY]。
我们内部只允许有三种上报方式:
- 累加
- 设置新值
- 设置***值
这三种方式都是操作一个 uint32_t,性能消耗非常小,而且还有一个***的优点,就是实时在内存进行汇总,每次从内存提取的记录只有平均 1000 条左右,大幅降低秒级统计的难度。
后台数据里面还有一个重要数据是调用关系数据,在故障分析定位中有非常大的作用。
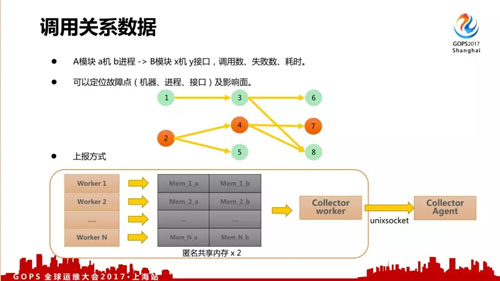
具体格式如上,可以定位故障点(机器、进程、接口)及影响面。它的上报量是小于 IDKey 的第二大数据,每次后台调用都产生一条数据,所以使用日志方式还是很难处理。
我们在服务内部用了另外一种跟 IDKey 接近的共享内存统计方式,比如说一个服务有 N 个 Worker,每个 Worker 会分配两块小共享内存进行上报,再由收集线程对数据打包后对外发送。
这个上报是框架层进行的上报,服务开发者不需要手工增加上报代码(微信 99% 都是使用内部开发的服务框架)。
终端数据监控
后台数据我们介绍完了,再说一下终端监控数据。这个我们关注的是手机端的微信 APP 一些具体的性能、异常,调用微信后台的耗时、异常,还有网络异常方面的问题。
手机终端产生的日志数据非常巨大,如果全量上报则对终端、后台都有不小的压力,所以我们并没有全量上报。
我们对不同数据、终端版本有不同的采样配置,后台会定期对终端下发采样策略。
终端对数据采样上报时也不会实时发送,而是用临时存储记录下来,隔一段时间再打包发送,力求对终端的影响最小化。
对外监控服务

下面简单介绍一下我们***的对外监控服务,这个方案参考了一些云监控的方案,用户可以自行配置维度信息和配置监控规则。
现在在我们的商户管理界面还有小程序开发者工具的页面已经开发了这个功能,但现在自定义上报还没有开放,只提供了后台采集的一些固定数据项。
微信数据监控的发展过程
上面介绍了数据的上报方式,接下来介绍一下我们如何对数据进行监控。
异常检测
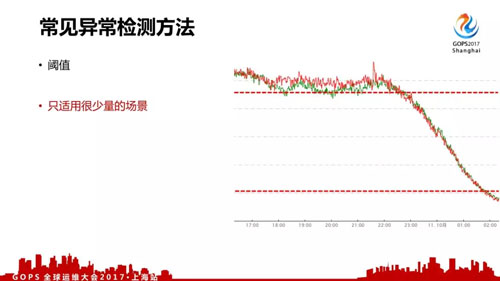
对于一般异常检测来说,可能都会用到三个办法:
- 阈值,甚至在早上和晚上都是有很大差异的,这个阈值本身没法去划分的,所以这个对于我们来说只适用于少量的场景。
- 同比,存在的问题是我们的数据都不是每天同一时间的数据是一样的,周一到周六会存在比较大的差异,只能降低敏感度才能保证准确性。
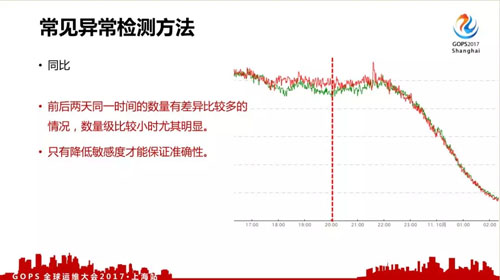
- 环比,我们的数据中,相邻的数据也并非平稳变化,数量级比较小时尤其明显,同样只有降低敏感度才能保证准确性。
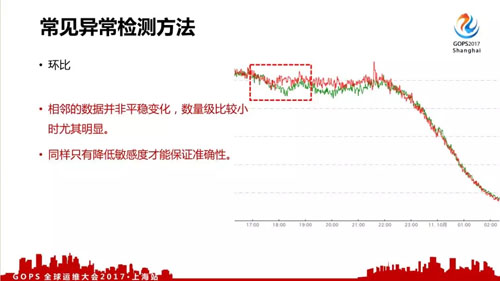
所以这三种常见的数据处理方法都不是很适用我们的场景,在过去我们对算法进行了改进。
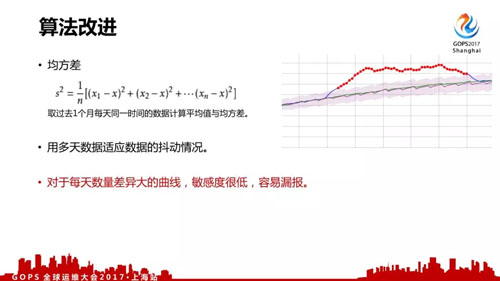
我们使用的***个改进算法是均方差,就是拿过去一个月每天同一时间的数据计算平均值与均方差,用多天数据适应数据的抖动情况。
这个算法适用范围比较广,但是对于波动比较大的曲线,敏感度会比较低,容易漏报。
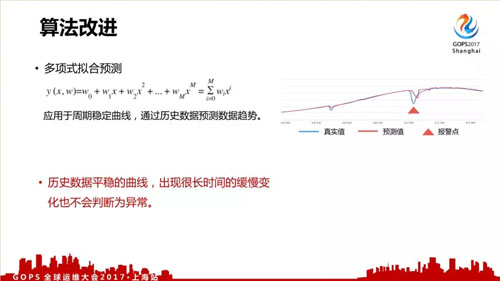
我们改进的第二个算法是多项式拟合预测,适用于平稳的曲线,就有点像改进的环比。
但如果出现异常时数据是平稳增长或减少,没有出现突变,这时也会判断为正常,出现漏报。
所以以上两种算法虽然比以前的算法有了不少改进,但同样存在一些缺陷。目前我们有在尝试其他算法,或多种算法结合一起使用。
监控配置
除了算法本身,我们在监控项配置也存在问题的,因为我们的服务非常多。
所以可能超过了 30 万的监控项要人手配置,每次配置观察曲线选择不同算法,不同的敏感度,而且过一段时间之后数据发生变化,需要重新调整。所以这种操作不可持续。
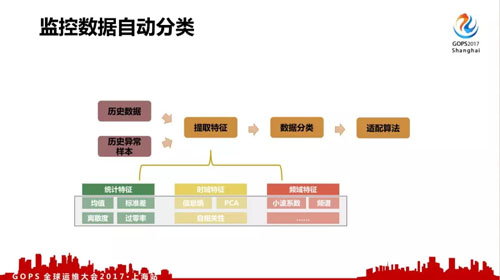
目前我们在尝试对监控项进行自动配置,比如使用历史数据,历史异常样本,抽取特征,进行数据分类,再自动套用***的监控参数。
这个我们正在尝试取得了一些成果,但还不是很完善,还在改进中。
海量监控分析下的数据存储设计思路
上面分享了数据如何进行采集、监控,***再介绍一下数据是怎么存储的。
对于我们来说数据存储同样重要,像刚才提到每分钟监控要拿一个月数据出来。
还有比如我们的故障分析,一个模块有异常需要读取所有机器调用信息、CPU、内存、网络、各种进程信息等,如果机器数特别多,一次读取的数据量会超过 50w*2 天。
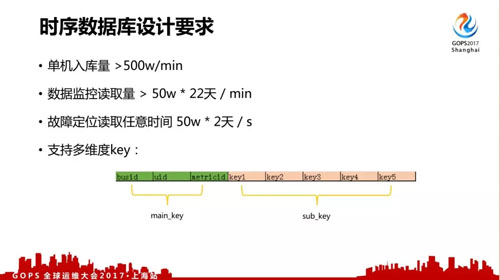
所以我们对监控数据存储的读写性能要求非常高。首先写入性能基本要求是总入库量可能一分钟有 2 亿条以上,单机至少要求 500w/min 能入到这个数据量。数据读取性能需要能支撑每分钟读取 50w×22 天的监控读取。
数据结构上,我们各种数据是多个维度的,比如调用关系的维度非常多,还要支持按 client 端、svr 端、模块级、主机级等不同维度的部分匹配的查询,不能只支持简单的 key —— value 查询。
注意我们的多维度 key 分成了 main key 和 sub key 两部分,后面会有介绍为什么这样做。
以前我们监控数据存储改造时参考了其他一些开源方案,但在当时没有找到完全符合性能、数据结构要求的现成方案,所以我们自行研发了自己的时间序列服务器。
首先对数据写入来说,如果一分钟一条记录,则数据量过大,所以我们会先缓存一定时间的数据,隔一段时间批量合并成一天一条记录。
这也是目前比较常用的提升写入性能的做法。我们数据缓存的时间是一个小时。
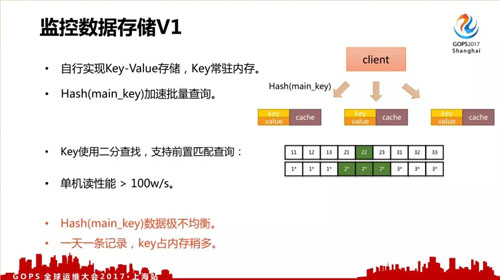
而我们自行开发的 key-value 存储,关键点是 key 的实现。首先 key 会常驻内存。
另外因为数据量很大,一台机不可能撑得住,所以我们用的是多机集群,使用 hash(main_key)对数据进行写入和查询。
而部分匹配查询是使用改造的二分查找法实现前置匹配查询。 这样实现的查询性能非常高,可以超过 100w/s,而且加个查询结果缓存性能更高。
不过它也存在一些问题,比如 hash(main_key) 数据不均衡,而且 1 天一条记录,key 占内存太多。
由于上面的问题,我们做了第二个改进。
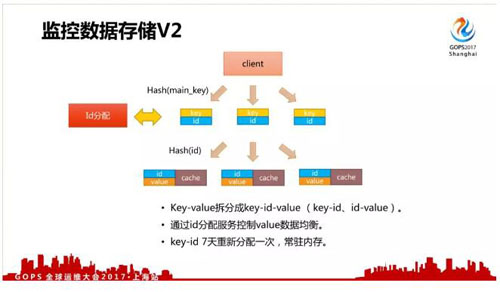
第二个改进的方法是把 Key-Value 拆分成 key-id-value ,通过 id 分配服务控制 value 数据均衡,key-id 7 天重新分配一次,减少内存占用。
对于存储来说还有一个***的问题就是容灾,既然是对服务器进行监控,自身的容灾能力要求也非常高。
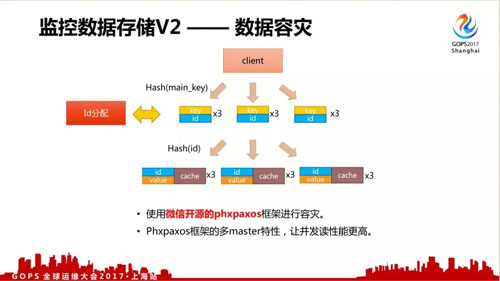
一般来说做到高容灾、数据强一致性比较难,但微信后台已经开源了自行研发的 phxpaxos 协议框架,使用这个框架可以很容易实现数据容灾。
另外 phxpaxos 框架的多 master 特性可以提升并发读取性能。
陈晓鹏,2008 年进入腾讯,2012 年调入微信运维开发组负责运维监控系统的改造,是微信当前运维监控系统的主要设计开发人员。