互联网的中心化发展模式是传统网络安全的的软肋,区块链作为一种去中心化、集体维护、不可篡改的新兴技术,是对互联网底层架构的革新,是对当今生产力和生产关系的变革。区块链也被誉为是继蒸汽机、电力、信息和互联网科技之后,目前最有潜力触发第五轮颠覆性革命浪潮的核心技术。
目前市场上主流的区块链系统有比特币,Ripple,以太坊和 Hyperledger Fabric 。本文的主要目的就是分析当前主要流行的区块链的存储技术以及他们之间的不同。
区块链简介
区块链(英语:blockchain 或 block chain)是用分布式数据库识别、传播和记载信息的智能化对等网络, 也称为价值互联网。中本聪于2008年在《比特币白皮书》中提出“区块链”概念,并在2009年创立了比特币社会网络,开发出***个区块,即“创世区块”。区块链包含一张被称为区块的列表,有着持续增长并且排列整齐的记录。每个区块都包含一个时间戳和一个与前一区块的链接,这样设计区块链使得数据不可篡改,一旦记录下来,在一个区块中的数据将不可逆。
其数据结构大致如下:
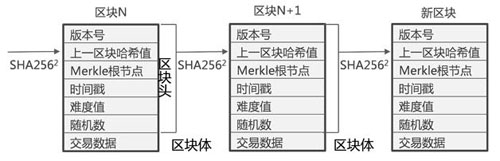
(区块链结构)
数据存储
1、比特币
比特币(英语:Bitcoin)是一种去中心化、全球通用、不需第三方机构或个人,基于区块链作为支付技术的电子加密货币。它由中本聪于2009年1月3日,基于无国界的对等网络,用共识主动性开源软件发明创立,是加密货币及区块链的始祖,也是目前知名度与市场总值***的加密货币。
比特币存储系统由普通文件和 kv 数据库(levelDB)组成。普通文件用于存储区块链数据,kv 数据库用于存储区块链元数据。
用于存储区块链数据的普通文件以 blk00000.dat , blk00001.dat 文件名格式组成,如图2所示,其中 index 目录存储用于存储区块元数据。

(图2)
为了快速检索区块数据每个文件的大小是128 M Bytes。每个区块的数据(区块头和区块里的所有交易)都会序列成字节码的形式写入 dat 文件中。
在序列化的过程中,如果检测到当前写入文件尺寸加上区块尺寸大于 128 M Bytes,则会重新生成一个 dat 文件。具体的序列化过程如下所述:
- 获取当前 dat 文件大小 npos,并将区块大小追加写入至 dat 文件中
- 序列化区块数据和区块中的交易数据,并将序列化的数据追加至 dat 文件中。
- ?在写入数据的过程中,会生成区块和交易相关的元数据。
区块的元数据格式如 <blockHash,xxxxx+npos> 格式, 其中 xxxxx 为 dat 文件序号,npos 为区块写入 dat 文件的起始位置。
交易的元数据格式如 <txHash, xxxxx+npos+nTxOffset> 格式, 其中 xxxxx、npos 和上面的描述一致,nTxOffset 为写入 dat 文件的起始位置(基于npos 位置)。
上述所有元数据都将写入 kv 数据库中,其中 blockhash/txHash 将作为后续查询具体数据在 dat 文件中的索引使用。
综上所述,在获取链数据的时候只需传入区哈希或是交易哈希,就能很容易的定位到区块数据或是交易数据。
2、瑞波币
Ripple 是世界上***个开放的支付网络,通过这个支付网络可以转账任意一种货币,包括美元、欧元、人民币、日元或者比特币,简便易行快捷,交易确认在几秒以内完成,交易费用几乎是零,没有所谓的跨行异地以及跨国支付费用。
Ripple 的区块链数据存储系统是由关系型数据库(sqlite)和 kv 数据库组成,其中关系型数据库用来存储区块头信息和每笔交易的具体信息, kv 数据库主要存储区块头、交易和状态表序列化后的数据。 Ripple 这样处理的主要目的是单纯在查询区块头信息和具体每笔交易的时候,可以直接从关系型数据库中查找;而要构造整个区块数据的时候,除了从关系型数据库构造区块头信息外,还要依据区块头里的交易根哈希和状态表根哈希从 kv 数据库中获取具体的交易和状态表信息。这是 Ripple 和其他三种类型区块链系统唯一***的不同。
区块头信息的序列化具体步骤:
- 用区块的哈希作为 Key;
- 序列化区块高度、区块哈希、前一个区块哈希、交易根哈希、状态表根哈希等生成的数据作为 value;
- 将 <key, value> 存储至 kv 数据库中。
交易的序列化具体步骤:
- 用区块头中的交易根哈希作为 Key;
- 序列化交易哈希、交易类型、交易数据和 MetaData 等生成的数据作为 value;
- 将 <Key, value> 存储至 kv 数据库中。
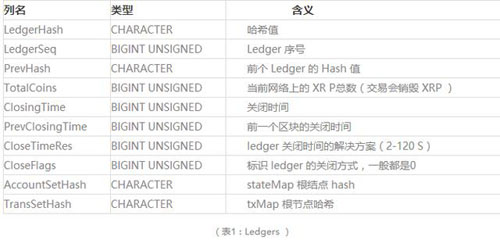
下表分别是 Ledgers 和 Transactions 表结构。

数据存储(二)
1、以太坊
以太坊是一个开源的有智能合约功能的公共区块链平台。通过其专用加密货币以太币(Ether,又称为「以太币」)提供去中心化的虚拟机(称为「以太虚拟机」Ethereum Virtual Machine)来处理点对点合约。
以太坊的区块主要由区块头和交易组成,区块在存储的过程中分别将区块头和交易体经过 RLP 编码后存入至 KV 数据当中。以太坊在数据存储的过程中,每个 value 对应的key 都有相对应的前缀,不同类型的 value 对应不同的前缀。
区块交易体的存储过程如下:
1. 将区块中的交易数据和叔块头信息进行 RLP 编码从而生成存储值value;
2. 将数据类型前缀,编码后的区块高度和区块哈希拼接生成 key;
3.将存储至db数据库中。
区块的信息可以通过区块哈希和区块高度进行检索,其存储过程如下:
1.将区块头信息进行 RLP 编码从而生成存储值 value
2.将区块高度进行编码(转发成大端格式数据)生成encNum
3. 将数据类型前缀 (headerPrefix) 和 encNum 生成以区块高度为检索信息的 key
4.将存储至db数据库中,从而生成以区块高度为检索的信息
5.将数据类型前缀(blockHashPrefix)和区块哈希生成以区块哈希为检索信息的key
6.将存储至db数据库中,从生成区块哈希为检索的信息
在数据查询的时候,应用层只需要提供交易 hash、区块高度和区块哈希就能得到交易 key,从而查询到相关的交易信息。
2、Hyperledger Fabric
Hyperledger fabric (HLF)是由Linux基金会主导推广的区块链开源项目。在Hyperledger Fabric的基础上又衍生出了其他一些相关的项目。HyperLedger项目汇集了金融、银行、物联网、供应链、制造等各界开发人员的心血。目的是为了打造一个跨领域的区块链应用。
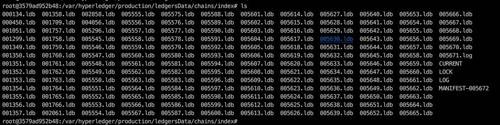
HLF 的存储系统和比特币一样,也是由普通的文件和 kv 的数据库(levelDB/couchDB)组成。在 HLF 中,每个 channel 对应一个账本目录,在账本目录中由 blockfile_000000、blockfile_000001 命名格式的文件名组成。为了快速检索区块数据每个文件的大小是64 M Bytes。每个区块的数据(区块头和区块里的所有交易)都会序列成字节码的形式写入 blockfile 文件中。
HLF存储区块数据的文件名格式如图所示:

HLF检索信息文件如图所示:
在序列化的过程中,程序以 append 方式打开 blockfile 文件,然后将区块大小和和区块数据写入至 blockfile 文件中。
以下是区块数据写入的具体描述:
1.写入区块头数据,依次写入的数据为区块高度、交易哈希和前一个区块哈希;
2. 写入交易数据,依次写入的数据为区块包含交易总量和每笔交易详细数据;
3. 写入区块的Metadata 数据,依次写入的数据为 Metadata 数据总量和每个 Metadata 项的数据详细信息。
在写入数据的过程中会以 kv 的形式保存区块和交易在 blockfile 文件中的索引信息,以方便 HLF 的快速查询。
HLF 区块索引信息格式在 kv 数据库中存储的最终的 LevelKey 值有前缀标志和区块 hash 组成,而 LevelValue 的值由区块高度,区块 hash,本地文件信息(文件名,文件偏移等信息),每个交易在文件中的偏移列表和区块的 MetaData 组成, HLF 按照特定的编码方式将上述的信息拼接成 db 数据库中的 value 。
HLF交易索引信息格式在kv数据库中存储最终的LevelKey值由channel_name,chaincode_name和chaincode中的key值组合而成:
LevelKey = channel_name + []byte + chaincode_name + []byte + key
而 LevelValue 的值由BlockNum 区块号,TxNum 交易在区块中的编号组成, HLF 通过将区块号和交易编号按照特定的方式编码,然后与 chaincode 中的 value 相互拼接最终生成 db 数据库中的 value 。
总结
综上所述,本文介绍的主要区块链除了 Ripple 使用的关系型数据库存储、检索区块数据外,其他三种类型的区块链都使用 kv 数据库存储区块链的检索信息。在存储、检索数据上,比特币和 Hyperledger Fabric 高度一致,即使用普通文件存储区块数据,使用 kv 数据库存储检索信息;以太坊的区块数据和检索信息都存储至 kv 数据库中,而 Ripple 的区块数据也会存储至 kv 数据库中。