我们在日常消费的决策中,比如选择去哪家餐厅吃饭、是否购买某一件商品时,除了自身的感觉之外,我们常常会参考别人,尤其是已经消费过、体验过的人是什么评价。现在的电商平台上某件商品的评论数动辄就上千甚至上万,人工逐条看精力有限,在短暂的决策时间窗口中,最多只能抽样查看不超过20条评价,这样的抽样结果总结出来的结论大概率存在偏差,无法反应整体的真实情况。
那有没有大数据的方法,可以保证获得最全面最客观的评价,而不是管中窥豹呢?
幸运的是打分机制很早就被发明出来了,所有人都可以对某一件商品的整体情况在1-5分的评分体系中,给出一个综合评价,再按一人一票制取平均值,用得到的平均分来反映商品在所有人群中的整体评价,简洁民主。
但这样简单粗暴的评分方式无法体现出用户对商品的详细评价,举个简单的例子,同样是5分的评价餐厅,有的人觉得是因为菜品口味好,对自己的胃口,有的人觉得是因为用餐环境舒适,和女神度过了一个浪漫的夜晚。所以本文就分享一个深度学习的方法,从评论中提取出用户的观点,比如从某火锅店的评价“环境蛮好,没有很重的香料味道,上菜快,不用调料也好吃”中提取出“环境好,上菜快”的评价标签,并和其他有类似标签的评价聚类。

本文分享一种用word2vec模型,将词语训练成词向量,作用就是将人类使用的自然语言(相对于计算机可理解的编程语言)中的字词,转换为计算机可以理解的稠密向量(Dense Vector)。在word2vec出现之前,自然语言处理经常把字词转为离散的单独的符号(One-hot Vector)
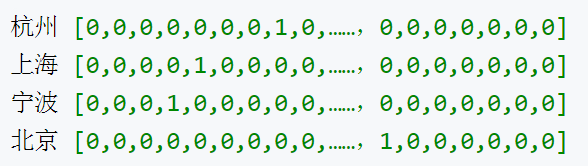
比如上图的例子,在语料库中,四个城市各对应一个向量,向量中有且只有一个值为1,其他位置都为0
但是用One-hot Vector会有两个问题,***,城市编码是随机的,向量之间相互独立,看不出城市之间可能存在的关联关系。其次,向量维度的大小取决于语料库中字词的多少。如果将世界所有城市名称对应的向量合为一个矩阵的话,那这个矩阵过于稀疏,占用大量空间。Word2Vec可以将One-hot Vector转化为低维度的连续值,也就是稠密向量,并且其中意思相近的词将被映射到向量空间中相近的位置。
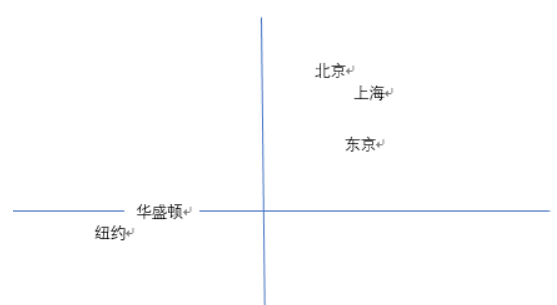
上图是将训练好的词向量降维后映射到二维平面的城市间的关系,可以看出亚洲的城市聚集在右上方而美国的城市聚集在左下方
Word2vec模型训练好后,每个词都有与其对应的一个多维向量,向量的维数可以作为参数人工设定,一般情况下维数越高,词与词之间的关系就可以被描述的越准确,当然训练模型所需的硬件和时间成本自然也更高,与其他模型一样,需要在表现和成本之间人工确定一个平衡点。以训练某手机游戏的评论文本为例,用python genism包提供的Word2vec模块作为训练工具,预测“画面”,“音效”两个词的top20近义词结果如下
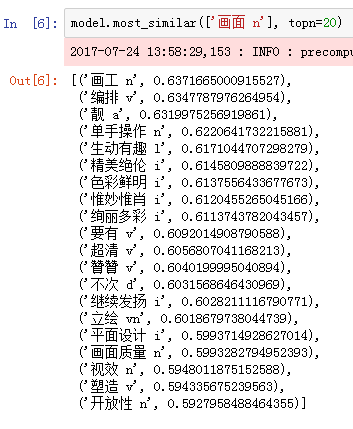

在模型结果的基础上进行人工筛选后,可以总结出“画工”,“画面质量”,“音响效果”,“音乐感”,“节拍”等词都可以作为近义词添加到人工建立的近义词词典中。
除了近义词之外,word2vec模型还支持预测与输入词出现概率***的协同词,下图显示的是与“画面”,“音效”一同出现频率***的top20协同词,可以再模型结果的基础上筛选出“精美”,“唯美”,“细腻”等形容画面的评价,和“震撼”,“逼真”等形容音效的评价。 

再重复向模型输入类似“画面”,“音效”等可以用来评价游戏的维度后,就可以将构建完整的近义词词典作为依据,聚类具有相似观点的评论文本。
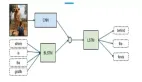
整个流程可以整理为以下这张流程图
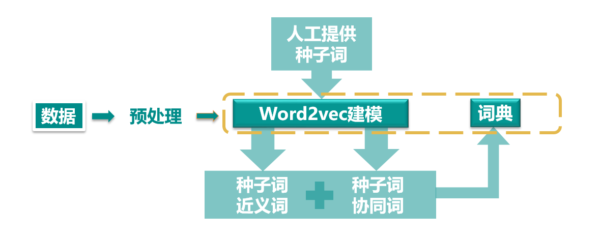
做过模型的同学都知道,模型只是工具,人工的部分才是区分整套系统质量和表现的关键。这套观点提取系统中需要人工处理的地方包括,数据(语料库)的选择,数据预处理,其中预处理又分分词,去停词,去除噪音数据等细节,人工提供评价维度的种子词(上文提到的“画面”,“音效”等),筛选模型输出的近义词和协同词结果(所有的结果保存在人工构建的词典中)。
这套系统建立完成后,将新的评论文本经过预处理后作为输入,匹配文本中是否包含词典中所有的评价维度的近义词和协同词,将匹配结果作为观点标签标注在该条评论上。这样我们就可以用模型批量的为评论文本打上标签,***将所有标签的结果汇总相加,就能得到无偏差的,全量的关于商品的评论,全面参考评论意见,辅助购买决策。