在Google、Amazon、腾讯等大型互联网公司里,因为业务广泛,有大量的用户数据需要保存,因此分布式存储系统往往成为该类公司的一个基础设施。分布式存储涉及到单机存储引擎、分布式系统协议等众多领域,该篇文章作为一个入门,带领大家认识分布式存储系统的基本概念。
分布式存储应该满足的基本条件
- 可扩展
以微信朋友圈的图片为例,随着微信运营时间的增长,需要保存的朋友圈图片必然是越来越多的,因此保存这些图片的分布式存储系统必须可扩展。
- 低成本
对于大型互联网公司来讲,要保存的数据量非常大,因此成本是考量一个存储系统是否可上线运营非常重要的一个指标。
- 高性能
无论是对整个分布式存储集群还是针对单机的存储引擎,都需要高性能的保证,否则低成本就无从谈起。
- 易用性
分布式存储系统作为一个基础设施,必须具备足够的易用性,才能更好地服务于各个业务。比如Amazon的S3,接口形式统一,接入简单。
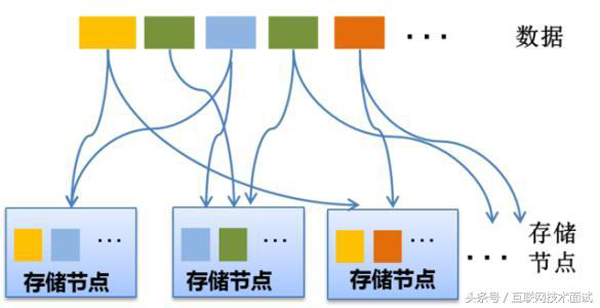
分布式存储系统面临的主要技术挑战
- 数据分布
整个存储系统是一个集群,如何保证数据均匀分布到多台服务器?假设某一数据被拆分存储到多台服务器后,又该如何实现跨服务器读写?
- 一致性
出于数据可靠性的考虑,同一份数据必然是保存多份的,如何保证这多份数据的一致性?
- 容错
对于一个集群而言,机器出现故障是必然的。如何在出现故障时做到及时发现,并且自动把故障机器上的数据和服务迁移到非故障机器?
- 负载均衡
任何一个集群系统都存在负载均衡的策略问题,分布式存储系统自然不例外。
- 事务与并发控制
如果要求该分布式存储系统支持事务和并发控制功能,该如何实现?
- 易用性
易用性前面有提,不再赘述。
- 压缩/解压缩
怎样根据数据的特点设计、选用合理的压缩/解压缩算法以平衡压缩带来的空间节省和消耗的CPU计算资源。
分布式存储系统存储的数据分类
互联网业务涉及的数据一般可以分为三大类:
1.非结构化数据
典型的如图片、音视频文件等。
2.结构化数据
传统的用关系型数据库保存的二维表结构数据。
3.半结构化数据
介于结构化数据和非结构化数据之间,典型的比如HTML文档。
分布式存储系统分类
基于上述数据类型存储的实际需要,分布式存储系统逐渐演化为以下四种类型:
1.分布式文件系统
一般用于存储非结构化数据。比如HDFS、TFS(Taobao File System)、FastDFS等。
2.分布式键值系统
可以通俗地理解为hash表,如淘宝的Tair、Redis、memcached等,一般用于存储半结构化数据。
3.分布式表格系统
也用于存储非结构化数据,相比分布式键值系统,不单单提供基于主键的读写,还支持对某个主键范围进行扫描,典型的比如Google的Big Table。
4.分布式数据库
由单机数据库发展而来,用于存储结构化数据。典型的如MySQL Sharding集群。