下载Demo - 2.77 MB (原始地址)
handwritten_character_recognition.zip
下载源码 - 70.64 KB (原始地址)
nnhandwrittencharreccssource.zip
介绍
这是一篇基于Mike O'Neill 写的一篇很棒的文章:神经网络的手写字符识别(Neural Network for Recognition of Handwritten Digits)而给出的一个人工神经网络实现手写字符识别的例子。尽管在过去几年已经有许多系统和分类算法被提出,但是手写识别任然是模式识别中的一项挑战。Mike O'Neill的程序对想学习通过神经网络算法实现一般手写识别的程序员来说是一个极好的例子,尤其是在神经网络的卷积部分。那个程序是用MFC/ C++编写的,对于不熟悉的人来说有些困难。所以,我决定用C#重新写一下我的一些程序。我的程序已经取得了良好的效果,但还并不优秀(在收敛速度,错误率等方面)。但这次仅仅是程序的基础,目的是帮助理解神经网络,所以它比较混乱,有重构的必要。我一直在试把它作为一个库的方式重建,那将会很灵活,很简单地通过一个INI文件来改变参数。希望有一天我能取得预期的效果。
字符检测
模式检测和字符候选检测是我在程序中必须面对的最重要的问题之一。事实上,我不仅仅想利用另一种编程语言重新完成Mike的程序,而且我还想识别文档图片中的字符。有一些研究提出了我在互联网上发现的非常好的目标检测算法,但是对于像我这样的业余项目来说,它们太复杂了。在教我女儿绘画时发现的一个方法解决了这个问题。当然,它仍然有局限性,但在***次测试中就超出了我的预期。在正常情况下,字符候选检测分为行检测,字检测和字符检测几种,分别采用不同的算法。我的做法和这有一点点不同。检测使用相同的算法:
- public static Rectangle GetPatternRectangeBoundary
- (Bitmap original,int colorIndex, int hStep, int vStep, bool bTopStart)
以及:
- public static List<Rectangle> PatternRectangeBoundaryList
- (Bitmap original, int colorIndex, int hStep, int vStep,
- bool bTopStart,int widthMin,int heightMin)
通过改变参数hStep (水平步进)和vStep (垂直步进)可以简单地检测行,字或字符。矩形边界也可以通过更改bTopStart 为true 或false实现从上到下和从左到右不同方式进行检测。矩形被widthMin 和d限制。我的算法的***优点是:它可以检测不在同一行的字或字符串。
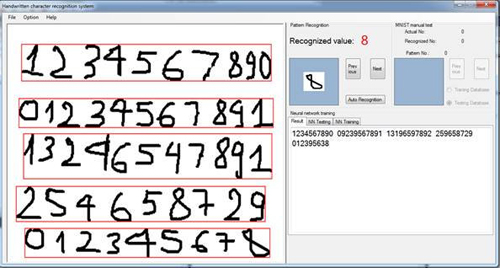
字符候选识别可以通过以下方法实现:
- public void PatternRecognitionThread(Bitmap bitmap)
- {
- _originalBitmap = bitmap;
- if (_rowList == null)
- {
- _rowList = AForge.Imaging.Image.PatternRectangeBoundaryList
- (_originalBitmap,255, 30, 1, true, 5, 5);
- _irowIndex = 0;
- }
- foreach(Rectangle rowRect in _rowList)
- {
- _currentRow = AForge.Imaging.ImageResize.ImageCrop
- (_originalBitmap, rowRect);
- if (_iwordIndex == 0)
- {
- _currentWordsList = AForge.Imaging.Image.PatternRectangeBoundaryList
- (_currentRow, 255, 20, 10, false, 5, 5);
- }
- foreach (Rectangle wordRect in _currentWordsList)
- {
- _currentWord = AForge.Imaging.ImageResize.ImageCrop
- (_currentRow, wordRect);
- _iwordIndex++;
- if (_icharIndex == 0)
- {
- _currentCharsList =
- AForge.Imaging.Image.PatternRectangeBoundaryList
- (_currentWord, 255, 1, 1, false, 5, 5);
- }
- foreach (Rectangle charRect in _currentCharsList)
- {
- _currentChar = AForge.Imaging.ImageResize.ImageCrop
- (_currentWord, charRect);
- _icharIndex++;
- Bitmap bmptemp = AForge.Imaging.ImageResize.FixedSize
- (_currentChar, 21, 21);
- bmptemp = AForge.Imaging.Image.CreateColorPad
- (bmptemp,Color.White, 4, 4);
- bmptemp = AForge.Imaging.Image.CreateIndexedGrayScaleBitmap
- (bmptemp);
- byte[] graybytes = AForge.Imaging.Image.GrayscaletoBytes(bmptemp);
- PatternRecognitionThread(graybytes);
- m_bitmaps.Add(bmptemp);
- }
- string s = " \n";
- _form.Invoke(_form._DelegateAddObject, new Object[] { 1, s });
- If(_icharIndex ==_currentCharsList.Count)
- {
- _icharIndex =0;
- }
- }
- If(_iwordIndex==__currentWordsList.Count)
- {
- _iwordIndex=0;
- }
- }
字符识别
原程序中的卷积神经网络(CNN)包括输入层在内本质上是有五层。卷积体系结构的细节已经在Mike和Simard博士在他们的文章《应用于视觉文件分析的卷积神经网络的***实践》中描述过了。这种卷积网络的总体方案是用较高的分辨率去提取简单的特征,然后以较低的分辨率将它们转换成复杂的特征。生成较低分辨的最简单方法是对子层进行二倍二次采样。这反过来又为卷积核的大小提供了参考。核的宽度以一个单位(奇数大小)为中心被选定,需要足够的重叠从而不丢失信息(对于一个单位3重叠显得过小),同时不至于冗余(7重叠将会过大,5重叠能实现超过70%的重叠)。因此,在这个网络中我选择大小为5的卷积核。填充输入(调整到更大以实现特征单元居中在边界上)并不能显着提高性能。所以不填充,内核大小设定为5进行二次采样,每个卷积层将特征尺寸从n减小到(n-3)/2。由于在MNIST的初始输入的图像大小为28x28,所以在二次卷积后产生整数大小的近似值是29x29。经过两层卷积之后,5x5的特征尺寸对于第三层卷积而言太小。Simard博士还强调,如果***层的特征少于五个,则会降低性能,然而使用超过5个并不能改善(Mike使用了6个)。类似地,在第二层上,少于50个特征会降低性能,而更多(100个特征)没有改善。关于神经网络的总结如下:
#0层:是MNIST数据库中手写字符的灰度图像,填充到29x29像素。输入层有29x29 = 841个神经元。
#1层:是一个具有6个特征映射的卷积层。从层#1到前一层有13×13×6 = 1014个神经元,(5×5 + 1)×6 = 156个权重,以及1014×26 = 26364个连接。
#2层:是一个具有五十(50)个特征映射的卷积层。从#2层到前一层有5x5x50 = 1250个神经元,(5x5 + 1)x6x50 = 7800个权重,以及1250x(5x5x6 + 1)= 188750个连接。
(在Mike的文章中不是有32500个连接)。
#3层:是一个100个单元的完全连接层。有100个神经元,100x(1250 + 1)= 125100权重,和100x1251 = 125100连接。
#4层:是***的,有10个神经元,10×(100 + 1)= 1010个权重,以及10×10 1 = 1010个连接。
反向传播
反向传播是更新每个层权重变化的过程,从***一层开始,向前移动直到达到***个层。
在标准的反向传播中,每个权重根据以下公式更新:
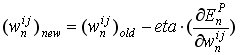
(1)
其中eta是“学习率”,通常是类似0.0005这样的小数字,在训练过程中会逐渐减少。但是,由于收敛速度慢,标准的反向传播在程序中不需要使用。相反,LeCun博士在他的文章《Efficient BackProp》中提出的称为“随机对角列文伯格-马夸尔特法(Levenberg-Marquardt)”的二阶技术已得到应用,尽管Mike说它与标准的反向传播并不相同,理论应该帮助像我这样的新人更容易理解代码。
在Levenberg-Marquardt方法中,rw 计算如下:
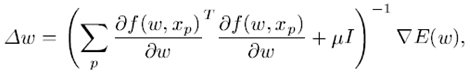
假设平方代价函数是:

那么梯度是:
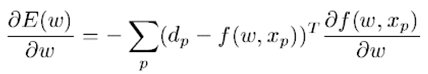
而Hessian遵循如下规则:

Hessian矩阵的简化近似为Jacobian矩阵,它是一个维数为N×O的半矩阵。
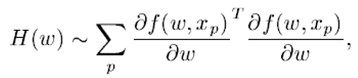
用于计算神经网络中的Hessian矩阵对角线的反向传播过程是众所周知的。假设网络中的每一层都有:
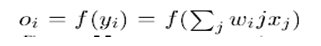
(7)
使用Gaus-Neuton近似(删除包含|'(y))的项,我们得到:
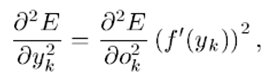
(8)
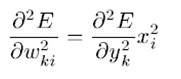
(9)
以及:
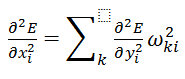
随机对角列文伯格-马夸尔特(Levenberg-Marquardt)法
事实上,使用完整Hessian矩阵信息(Levenberg-Marquardt,Gaus-Newton等)的技术只能应用于以批处理模式训练的非常小的网络,而不能用于随机模式。为了获得Levenberg- Marquardt算法的随机模式,LeCun博士提出了通过关于每个参数的二阶导数的运算估计来计算Hessian对角线的思想。瞬时二阶导数可以通过反向传播获得,如公式(7,8,9)所示。只要我们利用这些运算估计,可以用它们来计算每个参数各自的学习率:
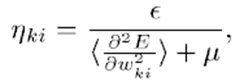
其中e是全局学习速率,并且

是关于h ki的对角线二阶导数的运算估计。m是防止h ki在二阶导数较小的情况下(即优化在误差函数的平坦部分移动时)的参数。可以在训练集的一个子集(500随机化模式/ 60000训练集的模式)中计算二阶导数。由于它们变化非常缓慢,所以只需要每隔几个周期重新估计一次。在原来的程序中,对角线Hessian是每个周期都重新估算的。
这里是C#中的二阶导数计算函数:
- public void BackpropagateSecondDerivatives(DErrorsList d2Err_wrt_dXn /* in */,
- DErrorsList d2Err_wrt_dXnm1 /* out */)
- {
- // 命名(从NeuralNetwork类继承)
- // 注意:尽管我们正在处理二阶导数(而不是一阶),
- // 但是我们使用几乎相同的符号,就好像有一阶导数
- // 一样,否则ASCII的显示会令人误解。 我们添加一
- // 个“2”而不是两个“2”,比如“d2Err_wrt_dXn”,以简
- // 单地强调我们使用二阶导数
- //
- // Err是整个神经网络的输出误差
- // Xn是第n层上的输出向量
- // Xnm1是前一层的输出向量
- // Wn是第n层权重的向量
- // Yn是第n层的激活值,
- // 即,应用挤压功能之前的输入的加权和
- // F是挤压函数:Xn = F(Yn)
- // F'是挤压函数的导数
- // 简单说,对于F = tanh,则F'(Yn)= 1-Xn ^ 2,即,
- // 可以从输出中计算出导数,而不需要知道输入
- int ii, jj;
- uint kk;
- int nIndex;
- double output;
- double dTemp;
- var d2Err_wrt_dYn = new DErrorsList(m_Neurons.Count);
- //
- // std::vector< double > d2Err_wrt_dWn( m_Weights.size(), 0.0 );
- // important to initialize to zero
- //////////////////////////////////////////////////
- //
- ///// 设计 TRADEOFF: REVIEW !!
- //
- // 请注意,此命名的方案与NNLayer :: Backpropagate()
- // 函数中的推理相同,即从该函数派生的
- // BackpropagateSecondDerivatives()函数
- //
- // 我们希望对数组“d2Err_wrt_dWn”使用STL向量(为了便于编码)
- // ,这是图层中当前模式的错误权重的二阶微分。 但是,对于
- // 具有许多权重的层(例如完全连接的层),也有许多权重。 分
- // 配大内存块时,STL向量类的分配器非常愚蠢,并导致大量的页
- // 面错误,从而导致应用程序总体执行时间减慢。
- // 为了解决这个问题,我尝试使用一个普通的C数组,
- // 并从堆中取出所需的空间,并在函数结尾处删除[]。
- // 但是,这会导致相同数量的页面错误错误,并
- // 且不会提高性能。
- // 所以我试着在栈上分配一个普通的C数组(即不是堆)。
- // 当然,我不能写double d2Err_wrt_dWn [m_Weights.size()];
- // 因为编译器坚持一个编译时间为数组大小的已知恒定值。
- // 为了避免这个需求,我使用_alloca函数来分配堆栈上的内存。
- // 这样做的缺点是堆栈使用过多,可能会出现堆栈溢出问题。
- // 这就是为什么将它命名为“Review”
- double[] d2Err_wrt_dWn = new double[m_Weights.Count];
- for (ii = 0; ii < m_Weights.Count; ++ii)
- {
- d2Err_wrt_dWn[ii] = 0.0;
- }
- // 计算 d2Err_wrt_dYn = ( F'(Yn) )^2 *
- // dErr_wrt_Xn (其中dErr_wrt_Xn实际上是二阶导数)
- for (ii = 0; ii < m_Neurons.Count; ++ii)
- {
- output = m_Neurons[ii].output;
- dTemp = m_sigmoid.DSIGMOID(output);
- d2Err_wrt_dYn.Add(d2Err_wrt_dXn[ii] * dTemp * dTemp);
- }
- // 计算d2Err_wrt_Wn =(Xnm1)^ 2 * d2Err_wrt_Yn
- // (其中dE2rr_wrt_Yn实际上是二阶导数)
- // 对于这个层中的每个神经元,通过先前层的连接
- // 列表,并更新相应权重的差分
- ii = 0;
- foreach (NNNeuron nit in m_Neurons)
- {
- foreach (NNConnection cit in nit.m_Connections)
- {
- try
- {
- kk = (uint)cit.NeuronIndex;
- if (kk == 0xffffffff)
- {
- output = 1.0;
- // 这是隐含的联系; 隐含的神经元输出“1”
- }
- else
- {
- output = m_pPrevLayer.m_Neurons[(int)kk].output;
- }
- // ASSERT( (*cit).WeightIndex < d2Err_wrt_dWn.size() );
- // 因为在将d2Err_wrt_dWn更改为C风格的
- // 数组之后,size()函数将不起作用
- d2Err_wrt_dWn[cit.WeightIndex] = d2Err_wrt_dYn[ii] * output * output;
- }
- catch (Exception ex)
- {
- }
- }
- ii++;
- }
- // 计算d2Err_wrt_Xnm1 =(Wn)^ 2 * d2Err_wrt_dYn
- // (其中d2Err_wrt_dYn是不是***个二阶导数)。
- // 需要d2Err_wrt_Xnm1作为d2Err_wrt_Xn的
- // 二阶导数反向传播的输入值
- // 对于下一个(即先前的空间)层
- // 对于这个层中的每个神经元
- ii = 0;
- foreach (NNNeuron nit in m_Neurons)
- {
- foreach (NNConnection cit in nit.m_Connections)
- {
- try
- {
- kk = cit.NeuronIndex;
- if (kk != 0xffffffff)
- {
- // 我们排除了ULONG_MAX,它表示具有恒定输出“1”的
- // 虚偏置神经元,因为我们不能正真训练偏置神经元
- nIndex = (int)kk;
- dTemp = m_Weights[(int)cit.WeightIndex].value;
- d2Err_wrt_dXnm1[nIndex] += d2Err_wrt_dYn[ii] * dTemp * dTemp;
- }
- }
- catch (Exception ex)
- {
- return;
- }
- }
- ii++; // ii 跟踪神经元迭代器
- }
- double oldValue, newValue;
- // ***,使用dErr_wrt_dW更新对角线的层
- // 神经元的权重。通过设计,这个函数
- // 以及它对许多(约500个模式)的迭代被
- // 调用,而单个线程已经锁定了神经网络,
- // 所以另一个线程不可能改变Hessian的值。
- // 不过,由于这很容易做到,所以我们使用一
- // 个原子比较交换操作,这意味着另一个线程
- // 可能在二阶导数的反向传播过程中,而且Hessians
- // 可能会稍微移动
- for (jj = 0; jj < m_Weights.Count; ++jj)
- {
- oldValue = m_Weights[jj].diagHessian;
- newValue = oldValue + d2Err_wrt_dWn[jj];
- m_Weights[jj].diagHessian = newValue;
- }
- }
- //////////////////////////////////////////////////////////////////
训练和实验
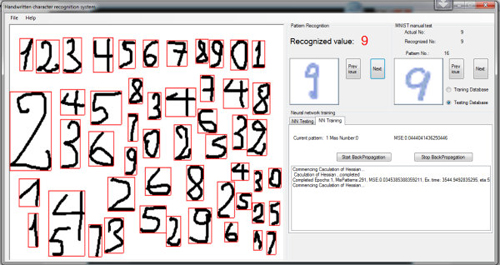
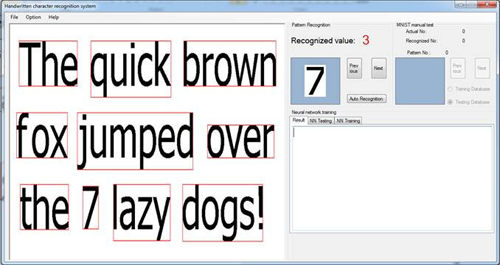
尽管MFC / C ++和C#之间存不兼容,但是我的程序与原程序相似。使用MNIST数据库,网络在60,000个训练集模式中执行后有291次错误识别。这意味着错误率只有0.485%。然而,在10000个模式中,有136个错误识别,错误率为1.36%。结果并不像基础测试那么好,但对我来说,用我自己的手写字符集做实验已经足够了。首先将输入的图像从上到下分为字符组,然后在每组中把字符从左到右进行检测,调整到29x29像素,然后由神经网络系统识别。该方案满足我的基本要求,我自己的手写数字是可以被正确识别的。在AForge.Net的图像处理库中添加了检测功能,以便使用。但是,因为它只是在我的业余时间编程,我相信它有很多的缺陷需要修复。反向传播时间就是一个例子。每个周期使用大约3800秒的训练时间,但是只需要2400秒。(我的电脑使用了英特尔奔腾双核E6500处理器)。与Mike的程序相比,速度相当慢。我也希望能有一个更好的手写字符数据库,或者与其他人合作,继续我的实验,使用我的算法开发一个真正的应用程序。
原文链接:https://www.codeproject.com/Articles/143059/Neural-Network-for-Recognition-of-Handwritten-Di
作者:Vietdungiitb
【本文是51CTO专栏作者“云加社区”的原创稿件,转载请通过51CTO联系原作者获取授权】