今天给大家带来的分享是基于支付场景的一个微服务实战,会更偏向于应用层的内容。
主要围绕以下四点进行分享:
- SOA 与微服务
- 老支付架构遇到的挑战
- 基于微服务怎么做的改造
- 未来计划要做的事
SOA 与微服务
在我看来,微服务虽是国外传进来的技术,却和咱们中国的一些理论是挂钩的。所以在正式进入主题之前,先给大家简单介绍一下麦田理论。
关于麦田理论

古代周朝时期,老百姓种地实际是没有任何规划的,也没有任何区域的限制。
一般来说在地里一会种水稻,一会种小麦,一会种蔬菜地交叉来种,可收成之后发现庄稼受阳光程度非常低,营养非常不均衡,后期维护成本非常高。
直到战国时期,有一位农业专家把地划分为多个区域,每一个区域种一种庄稼,地跟地隔开,形成最初的微服务理念。
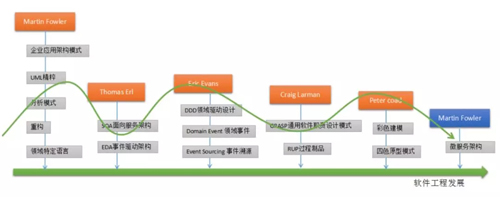
过去我们看到的很多文章都只是讲到 SOA 和微服务之间的比较,我今天在这个基础上加了一个 DDD。下面就 DDD、SOA 以及微服务的演进过程先做个引子。
DDD、SOA 与微服务
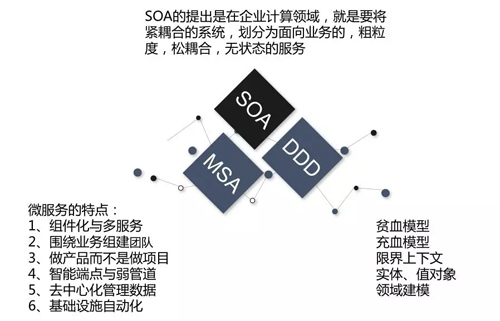
SOA 架构
SOA 是上一个时代的产物,大概是在 2010 年之前出现的,最早提出时是提供给传统行业计算领域的解决方案,当时 Oracle、IBM 也提了很多方案,包括出现的很多流程引擎。
它的思想是将紧耦合的系统,划分为面向业务的粗粒度、松耦合、无状态的服务。
在这之后,微服务的提出者基于 SOA 做了一个改进,就把它变成单一职责、独立部署、细小的微服务,是一个相反的概念。
微服务与 DDD
今天我们一说到微服务就会想到 DDD,有不少朋友认为 DDD 就是为微服务而生的。其实不是这样的,我在接触 DDD 时,它最早是用来做 UML 设计、领域建模的。
DDD 讲究充血模型,而 J2EE 模型以传统的分层架构和 Spring 架构捆绑在一起形成了以贫血模型为主的架构模式。
贫血模型的优点是容易入门、分层清晰,而充血模型要求设计者前期对业务理解较深,不然后期项目会产生混乱。
另外就是 DDD 思想比较宽泛,导致形成百家争鸣的姿态,没有形成一套固定的方法论。
开发者不容易理解,所以后面关注 DDD 的人变少了,而微服务的提出巧妙地借鉴了 DDD 里面的限界上下文、子域、领域事件等关键词,在微服务得到越来越多业界认可的情况下,也给 DDD 带来了重新的焕发机会。
老支付架构遇到的挑战
判断项目好坏的两个角度

我们判断一个优秀项目的好坏,可以从优秀的代码和高可用架构两个方向来讲。
我们在设计高可用架构的同时,也不能忽视代码的重要性,优秀的代码指的是冗错能力、冥等操作、并发情况、死锁情况等,并不一定是指代码写得多漂亮。
这就好比盖楼一样,楼房的基础架子搭得很好,但盖房的工人不够专业,有很多需要注意的地方忽略了,那么在往里面填砖加瓦的时候出了问题。
后果就是房子经常漏雨,墙上有裂缝等各种问题出现,虽然不至于楼房塌陷,但楼房也已经变成了危楼。
从代码和设计的角度来看有:
- 由不合理的代码所引起的项目无扩展性
- 数据库经常发生死锁
- 数据库事务乱用,导致事务占用时间过长
- 代码容错能力很差,经常因为考虑不足引起事故
- 程序中打印的大量的无用日志,并且引起性能问题
- 常用配置信息依然从数据库中读取
- 滥用线程池,造成栈和堆溢出
- 从库中查询数据,每次全部查出
- 业务代码研发不考虑幂等操作
- 使用缓存不合理,存在惊群效应、缓存穿透等情况
- 代码上下流流程定义混乱
- 异常处理机制混乱
再从整体架构角度来看:
- 整体依然使用单体集群架构
- 采用单机房服务器布署方式
- 采用 Nginx+hessian 的方式实现服务化
- 业务架构划分不彻底,边界模糊
- 项目拆分不彻底,一个 Tomcat 共用多个应用
- 无故障降级策略
- 监控系统不合理(网络、系统)
- 支付运营报表,大数据量查询
- 运维手动打包,手动上线
- 系统扩容手动布署
基于以上两点,我们可以清晰地看到以前老项目的存在问题,并开始思考新的微服务架构应该怎么去做。
基于微服务怎么做的改造
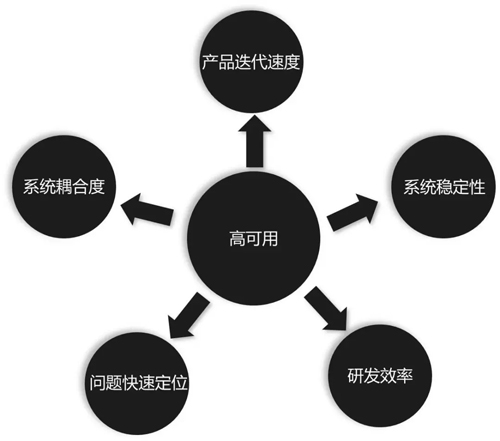
如上图,想做高可用的微服务架构,必须先确立以下五个点:
- 产品迭代速度,当架构设计完以后一定是对产品有利的,不能设计完了之后反而比以前开发得更慢了。这也是微服务的核心,通过把业务拆迁,将不同的产品一个个进行产品化,而不是项目化。
- 系统稳定性,单体架构时一个系统报错就全部报错,现在更是粒度细一些,同时架构各种监控。
- 研发效率。
- 问题快速定位,也就是每年给我们几十分钟的故障时间。
- 系统耦合度,不要把系统都放在一起,要多拆开。
利用 DDD 来划分限界上下文
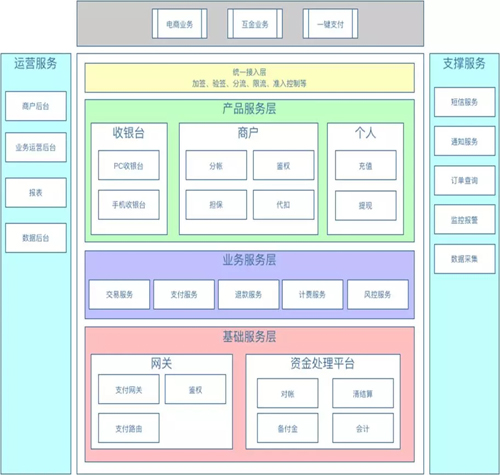
这是根据一些业务场景做的业务架构图,中间绿色部分是产品服务层。用 DDD 的思想来分析,产品服务层也就是产品服务域,这个域里包含三个子域,一个是收银台子域,一个是商户子域,一个是个人子域。
每一个域里都包含有限界上下文,收银台包含两个,商户包含四个,个人包含两个。
有些同学可能不太了解限界上下文概念,可以把它理解为一个系统、一个边界或者一个实体。
比如说我们每天上班要倒三次地铁,这里面的关键事件是什么?就是上班,那限界上下文就是坐地铁,中间切换三次。
限界上下文就可以把它理解为一个微服务,也可以把它理解为一个系统、一个模块。
限界上下文的划分可以根据我们的团队规模来定,如果团队规模没有达到一定的程度,可以将边界定的粗一些,如果项目规模和团队规模不断扩大,还可以再把大的领域和限界上下文继续拆分成多个小的。
微服务治理架构图
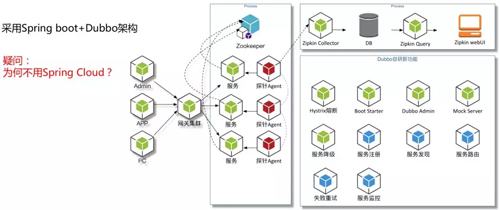
这是我们大致的一个微服务整体流程图,采用的是 Spring Boot+Dubbo 的架构。
为什么主张用 Dubbo 而不是 Spring Cloud?有两点原因:
- 要看目前这个架构是什么,如果是 Dubbo,很多组件的一些设施都要围绕它来做,如果这时把它完全推倒换成别的架构,成本部分我们需要慎重考虑。
- Spring Cloud 技术虽新但不见得一定比 Dubbo 好用。目前公司就维护了一个叫 Dubbo Cloud,自己研发一套基于 Dubbo 的微服务体系。
上图中间这块的探针也是我们自主研发的,能够实现把整个服务链路的各种信息采集到。
比如掉网时间、报错、返回值以及参数全部采集到,采集完之后就把这些信息用一个开源组件进行改造,把信息全部推给它,透过那个界面展示出我们要的东西。
后面这一套比如 Hystrix 熔断、Dubbo Admin 和 Mock Server,我们是参考 Dubbo 的思路做的智能化拦截和服务降级。
后面的服务注册、服务发现、服务路由、失败重试和服务监控等是 Dubbo 本身提供的,也就是图片绿色的部分是我们自研的新功能,未来我们会把这个 Dubbo Cloud 体系进行开源。
通道报警切换系统的演进
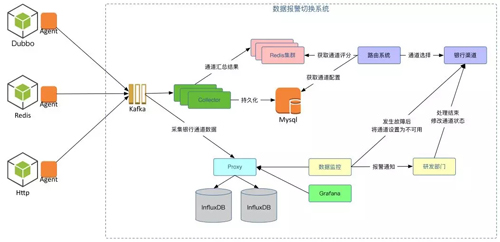
这是我们通道报警系统的框架演进。为什么叫“通道”呢?因为我们的支付要接银行,但银行本身是相对偏传统的,它们的通道不是很稳定。
经常有各种各样的问题,而每个银行都有 N 个通道,我们无法得知哪个通道近期是稳定的或不稳定,都是会来回变的。
这里我们自研了一个 Agent,通过采集它通道里的一些使用数据,比如说这次我们连成功了,获取到了数据,然后放到 Kafka 里。
之后还有一个统计分析的东西,如果这个通道连接成功一次会对它的统计加一次,***把每隔一段时间的结果存到 Redis 集群里。
图中的路由系统就是做通道选择的。这是一个业务系统,路由系统每次在做通道选择时要先从 Redis 集群里把这个银行的通道拿出来,选出评分***的一个。
拿出后再经过自己的一套路由选举的配套做一个清洗或者选择,***得到一个***的通道,直接连到银行通道上,这样我们就能知道哪些通道是高可用的。
底下的过程还是通过 Kafka,并进行各种各样的统计分析,也非常好用。然后这里会有一个图表,如果当前有问题,在界面上都能可以看到,同时可以给你发短信、发邮件。
为什么我们这里做了两套?***期的时候我们要做一个数据的比对,因为如果采集的数据不准确,这个通道就会存在问题。
所以我们一方面是通过上面这种方式来做评分策略,另一方面是把数据采集过来以后放到一个库里,通过这个库再做一次,***每次做一个比较,以统计正确率。
当这个通道也发生了问题,比如某一个银行通道发生了问题,我们的监控系统就会直接把银行通道设置为不可用,然后通知研发部门让他们去解决,完了以后再把这个通道变为可用。
如果这个过程数据不准确,会造成频繁的通道切换,会产生很多不必要的问题,所以在***期时我们先做成半自动化的。
双活体系架构的演进
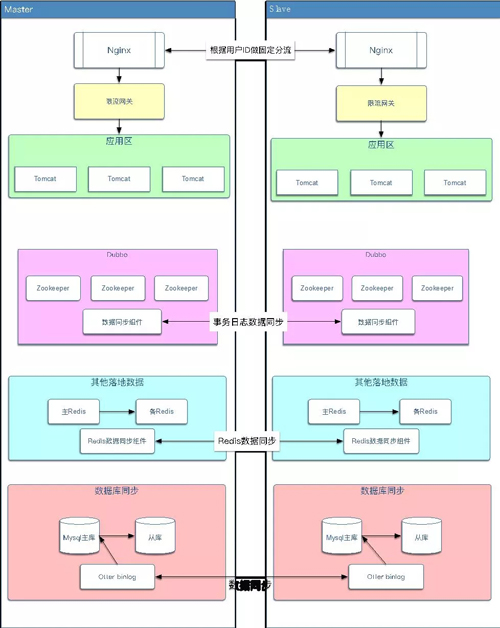
双活机房的演进,也是需要两个阶段:
***个阶段是伪双活
- 两个机房同时提供服务,但需要设置主备机房;备机房的应用只能通过专线访问主机房的数据库;备机房的 Redis 也需要通过专线访问主机房的 Redis。
- 当主机房挂了后,需要先将备机房应用的数据库配置改成备库,同时备库停机,修改备库为主库。
第二个阶段是泳道双活
双活体系架构的演进,在ZK做数据同步的时候,采用两种方式 Curator 的 TreeCacheListener 监控相应节点的变化从而同步数据,另一个是修改 ZK 源码伪装成 Observer 接收事务日志数据从而实现数据同步。
ZK 的同步***还是不进行同步、泳道隔离,比如像使用 Dubbo 这种的时候,完全可以同步二套环境,如果使用当当的 Elastic-Job,在做双活的时候就会相对麻烦。
微服务架构全景图
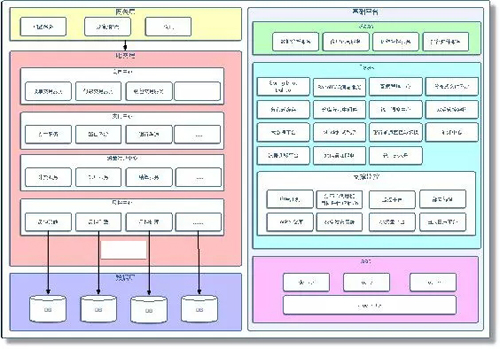
这个就是我们整个微服务的整体架构。图中左半部分体现了怎么把服务进行划分,划分了哪些领域,然后有哪些服务,数据库内容怎么划分,网关层怎么做的,是从业务角度来做的一个划分。
右边这块是体现我们如何保障微服务的可靠性。***层主要是给项目运营人员使用,第二层是我们为了保障微服务都做了什么东西,有统一调度中心、双活管控架构,还有大数据平台、分布式缓存,做了各种各样的组件来保障微服务顺利的开展。
再下面是一些监控,这里我们用了 APM 分布式调链的监控,包括我们自己也做了一些监控平台。
持续集成测试

接下来讲讲我们的持续测试经验。怎么来保证代码的质量?这里就涉及到了集成测试的概念。
我们分了四个象限:一是单元测试,这是由开发自己来做的,一般覆盖率在60-80%就不错了;二是验收测试和探索测试。
这两个实际上是我们的测试人员在做,一个是验证业务的可行性,一个是采取一些非法条件或者是一些破坏性测试,***是压力测试,通过压测看系统能承受的负载情况。
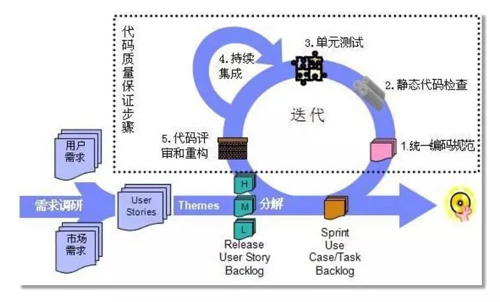
这是我们的整个测试流程:
- 首先,我们参照了阿里和其他公司的一些编码规范,制定一套自己的编码规范,并跟所有开发人员达成共识。
- 然后我们有自己的静态代码检查,这里也可以用阿里的组件,这是前两步。
- 第三步就是单元测试,基本上前三部分都是由开发来保障代码的健壮性和正确性。
- 第四是持续集成,我们根据自己的规则和模板对它再进行一次代码的扫描,扫描完之后就组织一些架构师或是技术专家,对一些关键核心代码再做一个代码重构,大致是分了五步。
未来计划要做的事
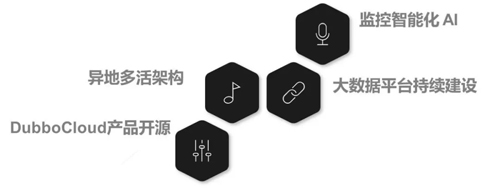
上图几点就是未来我们计划要做的一些事情,因为现在业务量越来越大了,而不久后央行会再出一个文件,要考虑异地多活这个情况,这块我觉得是一种趋势,目前也有很多公司在做这件事情。
然后我们也会有一个 Dubbo Cloud,未来也是会开源的。后面就是大数据平台的持续建设,目前我们的大数据平台还不是特别完善。
像数据的挖掘这块还没有做,而现在一般的金融公司还有支付公司的风控都要做得特别好,而我们才刚起步。
程超,智慧支付***支付专家,12 年 Java 开发经验,对互联网支付、电商业务方向较为了解,擅长分布式、性能调优等技术领域,对高并发、大数据有浓厚兴趣。《深入分布式缓存》一书联合作者。