一. 为什么要掌握列存储技术
列存储太流行了!!!
在大数据技术如火如荼的今天,掌握列存储技术不论对于求职面试,技术选型,还是增加自己的知识广度都是非常有帮助的。列存储技术目前应用领域有:
- hadoop生态系统:几乎所有的Sql-On-Hadoop引擎都支持列存储技术,比如SparkSql,Impala。parquet几乎成为了交互式分析的标准存储。
- NoSql数据库:HBase,cassandra等数据库。
- 传统关系数据库:Vertica,Infobright等传统意义上面向列的关系数据库,甚至oracle,sql-server都开始支持列存储了。
二. 文章大纲
尽管列存储技术已经非常的火了,但是列存储技术的中文资料还是太少了,在百度中搜索列存储几乎搜不到任何有价值的东西,列存储技术的学习难度非常高。
作者对列存储领域核心论文,开源技术做了一个整理,在接下来的系列文章中,分别对列存储技术进行一一介绍。本系列文章大纲如下:
列存储1:***个列存储模型DSM
列存储2:列存储没有取代行存储背后的原因
列存储3:列存储的崛起
列存储4:现代列存储关系数据库
列存储5:元组物化策略
列存储6:列存储压缩
列存储7:向量化执行引擎
列存储8:列存储在hadoop中的应用
列存储9:数据库存储模型的发展趋势
三.初识列存储
数据库领域中有两种存储方式:行存储和列存储。二者之间唯一的区别就是一个按行存储,一个按照列存储,如图1。
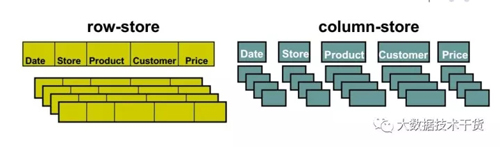
图1行存储和列存储
我们再举一个具体的例子,假设我们有一个employ关系表,employ表含有uuid,name,age三列,表总大小大约在3G左右。

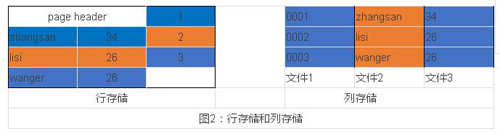
在行存储中(图2,左),表”水平”存储,既按行连续存储,首先***行,然后第二行。当执行SELECT uuid FROM sales,需要遍历表的所有数据(3G)来返回uuid列。
在列存储中(图2,右),表是”垂直”存储的,每一列独立的存储为一个文件,sales表中的每一个列都有一个对应的文件存储。当用户执行SELECT uuid FROM sales时,只需查询uuid对应的文件即可(30M),而不必查询其他列所对应的文件,从而极大的减少了磁盘访问,提高查询速度。
我们看到了列存储的优势:列存储查询可以剔除无关的列,当查询只有少量列时,可以极大的减少查询的数据量,提高查询速度。
此外,列存储还具有很多行存储所不具有的优点:因为按列存储,每一个列种内存相似的概率比较大,例如age列,34,26,26.因此列存储压缩率要比行存储高很多。此外,我们可以将列数据放到CPU cache中,然后使用SIMD指令执行计算,从而提高计算速度。
列存储概括起来具有如下优点[文献2],我们在接下来的系列文章中将分别详细的介绍:
- 轻量级压缩算法(Leight-Weight Compression)
- 延迟压缩(Late Compression)
- 延迟物化(Late Materialization)
- 直接操作压缩数据(Operating Directly on Compressed Data)
- 向量化执行引擎(vectorized processing)
四.列存储简史
列存储技术从诞生之日起,至今已有40多年时间了,列存储技术的广泛应用也不过是最近十年左右的事情。我们不由得好奇,既然列存储技术出现已经有40年了,为什么最近十年才开始流行,本文主要对列存储的发展历史做一个全局的综述,后面系列文章将对列存储做更细致的介绍。
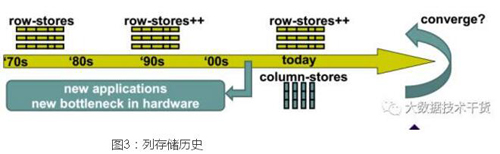
图3:列存储历史
列存储技术的发展主要经历了3个阶段:
- 1970-1990:列存储思想开始出现。在70s年代,列存储技术最早应用在倒排文件中。76以后关系数据库管理系统开始出现,关系数据库从出现开始就使用行存储作为其标准存储,到了1985年,Copeland在其A decomposition storage model论文中***提出了DSM存储,作者对DSM和NSM做了比较全面的对比,这篇论文阐述了两个最重要的观点:首先,DSM可以取代NSM作为关系数据库的存储,其次,当查询只有一个列或者少数几个列时,DSM可以显著的减少磁盘读取次数,从而提高查询性能。
- 1990-2005:列存储技术被应用在内存数据库中。到了90年代,CPU和内存之间的速度差异越来越大,当CPU指令访问内存数据时,需要花费上百个周期来等待内存返回结果,导致CPU大部分时间都浪费在等待内存上,CPU访问内存开始成为新的瓶颈。在数据库领域,最早注意到这一点的是Boncz.
- 1999年,Boncz在[3]中指出内存访问将成为数据库系统新的瓶颈,这个观点是非常令人兴奋的,因为人们一直认为磁盘是数据库系统最主要的瓶颈,而忽略了内存延迟。受boncz论文的启发,在数据库领域,逐渐出现了PAX等针对CPU cache优化的存储模型。因boncz在那个年代超前的观点,VLDB在2009将其论文评为十年内***论文。
- 2005-至今:读优化数据库。2005年以后,互联网应用越来越流行,企业存储的数据体量也越来越大,人们不再满足于简单的存储数据,而是开始想着怎么从现有的数据中挖掘出价值。于是,TB,PB级数据仓库开始出现。数据库仓库是典型的分析型应用,所谓的分析,就是海量数据基础上(至少***)执行复杂查询(join,group by,filter)。此时,传统的OLTP数据库很难处理这种分析应用,于是新的面向分析的数据库系统诞生了:面向列的关系数据。
C-store是***个现代的列存储关系数据库,其原型Michael Stonebraker(2014年图灵奖得主,后文会介绍)等大牛开发的,后来慢慢演变成vertica,我们现在的很多列存储技术用的都是c-store中的那一套,比如面向列的压缩。
面向列的关系数据库是典型的读优化数据库,所谓的读优化数据库,是指他们具有良好的复杂查询性能,但是不支持单行插入,在线更新等操作。该类系统通常只支持批量加载,比如每天凌晨设置一个定时任务将数据加载到数据库中。
五. 总结
列存储就是每一个列或者多个列独立的存储为一个文件,这是所有列存储系统的特点
列存储查询时可以”剔除”无关的列,从而极大的减少所查询的数据量,提高查询速度。
列存储发展历史经历了三个时期,1970-1990年,列存储思想开始萌芽,DSM是***个列存储模型。1990-2005年,人们主要关注列存储数据库在主内存中的应用,monet,pax是该时期的代表。2005以后,面向分析的读优化数据库开始流行。
列存储相关技术:轻量级压缩算法,延迟物化,直接操作压缩数据,向量化执行引擎。