【51CTO.com原创稿件】2018 年魔都的第一场雪,比以往时候来的更大一些,我本想约上三五好友聚会赏雪,但是一个哥们却迟迟未到。
经打听得知:他们公司的实时收/付账系统突然在库中出现了大面积的报表乱码和被锁的现象,他们运维部的电话不但被打爆,而且受波及的用户直接找上门来,要求从备份中恢复急需的报表。
这些也导致了他们团队完全无法静下心来冷静地处理问题,并按步骤恢复。大家听闻后,除了报以关切的“呵呵”,居然还有人在此基础上提出了“问题与养蛙理论”。
他振振有词地说:我们应对运维中的各类问题,实际上就和养旅行青蛙类似。我们必须对它们负责,关注其“成长”与“发展”。
同时,不能让那些问题像蛙儿子那样与我们缺少“交互”、甚至“任性”失控,从而我们完全无法 get 到它们身处何方、所处何态。你看,这脑洞开得也是没谁了。
众所周知,我们的系统也有着它自身的生命周期:从初出茅庐、到风华正茂、直至“芳华”不再,它出现的问题数量和复杂程度都会呈现V型曲线的趋势。
因此我们要及时应对,否则积累太多的话,就会像今年的这波流感病毒那样,迅速蔓延开来,到时候周董就真的只能来“等你下课”了。
话题聊到这里,想必大家已经猜出了我们本次的主题了。对,就让我们来具体看看如何在不同的层面上对各类出现的问题进行全程管控吧。
概念层面上:认知有“灰度”,才能对症下药
很多企业只有事件管理的概念,而没有问题管理的意识。为了统一认识,我们首先来理解三个基本概念:事件、事故和问题。
事件(Event)
一般是指某种 IT 服务或是被监控项到达了门限值,而引发的警告;或者是伴随着某项操作所触发的通知等。
比如说:存储剩余空间小于已设定的百分比数值、对某个账号的权限变更、或是用户组的成员调整等。
事故(Incident)
事故指计划外的 IT 服务中断,或是服务质量的骤降。
例如:由于专线出现问题、某个分部失去了与总部的网络连接;或是某用户利用企业内网观看在线视频,而拖慢了整体的内、外网访问速度。
事故也包括一些尚未产生影响的监控项异常。比如:在做了 RAID 镜像的互备磁盘上,有一个出现了故障,但整体所提供的服务尚未中断。
通常情况下,对于处理人员来说,能够快速找到那些虽“能治标不治本”的事故处理方法,可能会比花更多的时间去研究症结,更容易被用户所接受和认可。
由此可见对于事故的管理,我们主要是以止损、抑制不良影响和快速恢复为目的。
问题(Problem)
如果说处理事故是利用应急措施,去尽快地恢复 IT 服务的话,那么解决问题则是通过查找根源,预防中断的再次发生,以及对那些实在无法避免的问题,尽量控制其影响的程度,它往往是一个耗时比较长的过程。
例如:软件开发部门协同运维部门一起,对其所发布的产品中代码的漏洞和不正确的配置进行安全加固,以消除攻击隐患等。
由此可见对于问题的管理,我们主要是通过跟踪那些显著故障、分析根本原因,在根除的基础上防止同类问题在整个系统中的复发。
准备层面上:手中有粮,方能心中不慌
通过上述的理论基础,大家应该能够明白问题管理的利害关系了吧?为了避免在碰到问题时像开篇的那个哥们那样被动挨打、手足无措,我们就应当未雨绸缪,甚至要有“磨刀不误砍柴功”的精神来提前准备。
下面咱们来了解一下企业需要具备哪些先决条件。
建立统一的受理入口
一站式服务,无问西东
很多企业对内配备了 Help desk,负责响应与处理自身用户的各种 IT 问题;而对外则设置了 Call center,能够应答和受理外部客户的各类技术疑问。
因此,我们可以将其作为统一的受理入口,收集第一手的问题导入,同时也不放过任何一个问题的最初细节状态。
配有自动的工具平台
巧妇难为无米之炊
无论是自行研发也好,还是选型添置也罢,企业都需要拥有一套工具平台来实现问题的录入和分拣。
这个平台的特点是:
- 对于需要录入的各种问题,应尽可能以“菜单选择”的方式来丰富问题的相关属性项,并且要有基本的默认值。
这样设计的好处在于:既方便了对问题提交者进行“提问式思路”的引导,又利于系统在后台使用“已知错误知识库(Known Errors Database,KEDB)”进行自动地匹配、分拣和过滤。
- 从系统的投资回报率(ROI)角度来看:越容易操作提交,就越方便被频繁使用。
根据我的过往使用经验,对于那些仅需要三、五步点选和输入操作,就能完成提交的工具,提交者最乐于去使用。他们在体验到高效和便捷的同时满意度也很高。
- 自动为每一个问题提交分配一个工单号(ticket),并能够自动设置计时、倒计时、邮件告知等功能,以方便跟踪与评估。
拥有丰富的知识库
我注六经,还是六经注我
许多企业都已经拥有了配置管理数据库(ConfigurationManagement Database,CMDB)。
但是从问题管理的准备层面上说,我们要能够对CMDB予以用“活”,也就是说:要让上述的录入平台能够访问到它,并且实现对相关记录信息进行自动且精准地查找、定位和匹配。
当有了与 CMDB 的流畅“联动”,我们在整个问题处理的生命周期中,就能够轻松获取到丰富的背景支持信息,这样管理起来也更得心应手。
流程层面上:做一次流程并不难,难的是一直都这么遵循
我曾听过一句非常经典的管理言论:“没有流程,就没有执行力。”的确,面对各种出现的问题,纵然前期准备得再充分,如果没有正确的人、在正确的阶段、做正确的处理,就很容易造成整个团队乃至服务形象的“人设崩塌”。
做过日常运维的小伙伴可能会有这样的体会:我们不但对于突发的问题要有规范的处置流程;对于各种计划的服务发布和业务变更,也要提前设计好应对各类“失败”的应急流程,以防范于未然。
下图是一个问题管理的通用流程,让我们来逐一进行分解和梳理:
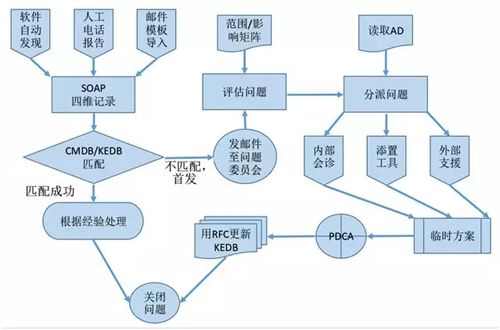
记录问题(事无巨细,明察秋毫)
输入:各种事件、事故和问题的产生,一般由自动和人工两种途径所产生。
即:由监控软件自动发现,并主动推送到受理平台上;Help desk 根据接报在平台的管理界面输入生成。
当然也可以由用户通过既定的邮件模板向指定地址发送电子邮件的形式,自动捕获关键字段来产生。
记录:Help desk 如实且详细地记录问题的“症状”。
他们通过从 SOAP(Statement Observation Analysis Process,陈述-观察-分析-处理)四个维度出发,留下他们的初步诊断和处理日志。
我在这里分享一个经验:应尽可能在 SOAP 里使用受影响“配置项(Configuration Item,CI)”的规范名称和错误代码等方面的信息。
这对于我们下面要谈到的事后查找与借鉴是十分有用的。因为问题描述可能因人而异,但这些特征字段较为通用也容易定位。
匹配问题(不要重复造轮子)
匹配:根据我们在前期准备阶段所“打通”的 CMDB 和 KEDB,运用关键字的匹配,来判断所提交的问题是首次发生,还是可以匹配到曾经发生过的、已知问题的记录。
如果能够定位到相似的记录,则直接根据过往经验记录着手处理,并最终关闭该问题。倘若是首发,则对其进行属性分类,以方便流转到下一步。
输出:在提交的 24 小时内,自动生成邮件,以通知问题管理委员会成员。
评估问题(找到“任督二脉”)
每一个问题在被录入到系统中的时候,我们应事先定义并设置好各种影响范围和紧急程度等选项,而问题管理委员会在收到邮件后,根据该问题日志记录和经验做出二次判断与评估。
同时,他们可以利用类似如下的矩阵,对所影响到的范围,和对业务与服务的影响程度,进行确认或修正。
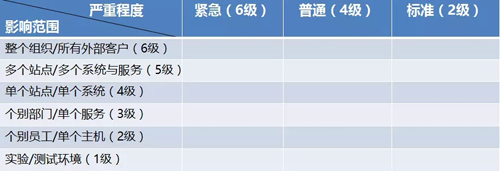
他们通过横向与纵向的焦点区域来评定问题的优先级,并根据运维部门的实际处理能力进行区别对待。
分派问题(找对“师傅”很重要)
根据上述的问题分类和优先级,问题管理委员会着手识别、并指派问题的处理人员。
这里再给大家分享一些我的点滴经验:
- 通过读取系统目录(AD)里 IT 角色和组的信息,方便处理人员所属的部门能够直接被对应到问题的本身分类属性上。必要时,各部门通过联动进行“会诊”处理。
- 如果被分派到的处理人不在,或是无法胜任,则升级到他对应的技术团队。
- 如果超出本企业内部现有的处理能力,则添置相应的专业技术与工具,或应及时转呈外部资源,以寻求援助。
- 在平台上,预先设置的分类越有条理、越丰富,就越能节约处理人员定位和他们熟悉问题的时间。
解决验证(用工匠精神去深耕)
处理人员或团队针对被分派的问题开展调查研究,并且每 24 小时更新一次工作日志。
在着手解决的过程中,我们应注意如下几点:
- 鉴于“聊胜于无”的佛系思想,如果能预计到分析的耗时较长的话,处理人员应当及时给出临时解决方案,保证服务的“降速”提供。
- 在找到了最终办法之后,处理人员需在模拟环境中进行充分的测试,并制定出回滚(Roll back)的方案。大家还记得那个“魔性”的 PDCA(Plan-Do-Check-Act)吗?此处仍然适用。
- 俗话说:唯一不变的是变更。要解决问题,就难免需要对原来的系统或服务进行修改。
为了避免发生各种未遇见到的次生问题,处理人员应严格遵循既定的变更管理流程,准备并提交一份变更请求(Request for Change,RFC)。
具体的内容大家可以参考一下《【廉环话】从OWASP Top 10的安全配置缺失说起》(http://zhuanlan.51cto.com/art/201708/547356.htm)。
- 千万记得要把验证有效的问题解决方案更新到我们上面提及的 KEDB 之中。
管理层面上:事后不总结,难道还留着过年吗?
在问题解决后,大家先别慌张开香槟,此时应该开展的是“过秦论”。
具体说来,应该由问题管理委员会牵头进行如下事后工作:
- 对问题的处理效果进行评审,重点是偏离 SLA 的部分(如超时等)及其原因,并提出改进方案。
- 提出问题复发与根除的整改措施与方案。
- 通过邮件的形式向受到问题影响的用户发放调查问卷和满意度。
- 每月汇总各类问题的详细报表,举行例会对问题进行归类和趋势分析。
- 每半年或一年对现有问题的处理流程进行回顾,涉及到的内容包括:流程的关键衡量指标、执行效率,验证工具的有效性等。
结语
您一定听说过那个适用范围颇广的“二八理论”吧?在这里,它也可以体现为:80% 的 IT 服务中断,来自于 20% 的累计问题。
由此可见,为了防止各种问题对系统和服务的“秋后算账”,我们不能停留在“黑暗球场”上,而是要通过不断地关心“蛙儿子”们的“成长”,持续修正与改进,才能通过自建生态圈,将各种问题“圈定”在可控且可管理的范围之内。
陈峻(Julian Chen) ,有着十多年的 IT 项目、企业运维和风险管控的从业经验,日常工作深入系统安全各个环节。作为 CISSP 证书持有者,他在各专业杂志上发表了《IT运维的“六脉神剑”》、《律师事务所IT服务管理》 和《股票交易网络系统中的安全设计》等论文。他还持续分享并更新《廉环话》系列博文和各种外文技术翻译,曾被(ISC)2 评为第九届亚太区信息安全领袖成就表彰计划的“信息安全践行者”和 Future-S 中国 IT 治理和管理的 2015 年度践行人物。

【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】