1. 背景介绍
人工智能时代,各种深度学习框架大行其道,掌握一种框架已经成为这个时代的算法工程师标配。但无论学习什么框架或者工具,如果不了解它是如何解决某个具体问题进而帮助提高业务,那无异于舍本逐末。
本文将从智能对话系统中一个基础的问题——情感分析(Sentiment Analysis)——谈起,详细阐述如何“step-by-step”地运用百度开源的深度学习框架(PaddlePaddle)来解决情感分析,并最终如何提升整个对话系统的质量。
1.1一个案例
设想如下情景,一个刚刚成功转变身份成为父母的好青年,来到了一家专业纸尿裤供应商(例如小鹿叮叮)想要给刚出生的宝宝屯点纸尿裤。在做了如下一番交涉后,该青年发现为自己服务的是一个机器人,并且答非所问,他怒火中烧,直接辱骂机器人。若你正好是开发该智能导购机器人的算法工程师,应该怎样应对这种情况呢?
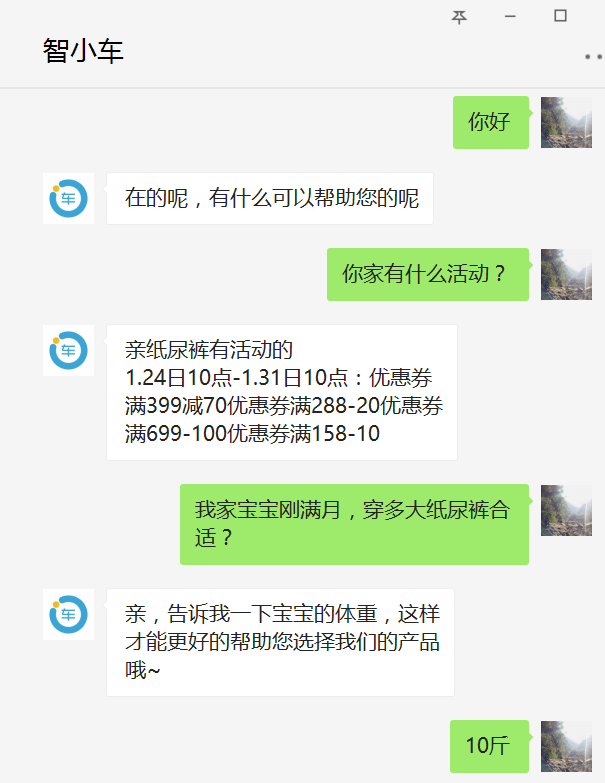
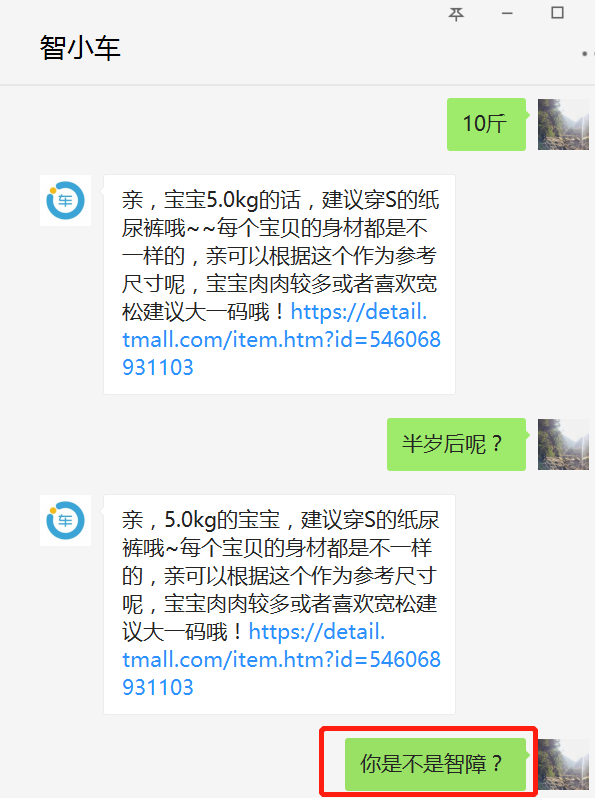
(图片来源:智能一点为小鹿叮叮开发的智能导购机器人测试账号)
在对话系统(Dialogue System)领域,由于目前的人工智能还只是弱人工智能,人工的介入在所难免,那么人工何时介入成为一个问题。若能精准识别用户目前的情绪(积极正面的情绪、消极负面的情绪),并在用户表现出负面情绪时及时转人工,这样既能尽可能地为企业提升效率、节省开支并进行精准推荐,又能在弱人工智能无法处理时及时安抚用户,降低客户流失。这就是情感分析在智能对话系统中的一个典型应用。
1.2 情感分析对于对话系统的意义
对话系统,作为一个直接与人对话的系统,若能完成对用户情绪的实时感知,对提升整个对话系统的质量,具有十分重大的意义,上述情景只是其在对话系统中的一种应用。
首先,情感分析能直接为企业提供量化的客服质量评估。由于一个好的客服在与客户交互的过程中一定会注意不引起客户的反感,那么从每个客服交互日志中可以通过情感分析可以挖掘出客户情绪的波动情况以及什么样的回复容易引起客户反感,将有助于企业效率的提高以及提升对话系统质量。
再者,目前大部分面向任务的对话系统(Task-oriented Dialogue System)都是采用基于有限状态自动机(FSA-based)或者基于帧(Frame-based)的架构。在这样的架构中,意图识别显得尤为重要。用户的情感倾向有助于提高意图识别的准确率。
最后,对话系统领域的前沿研究正在结合强化学习(Reinforcement Learning)来设计对话机器人[2]。强化学习需要机器人能接受环境(Environment)的反馈用以量化奖励(Reward),从而选择更加合适的动作(Action),精准的情感倾向分析是一种很强的环境反馈,是强化学习在对话系统中能够发挥作用的基础构件。
2.情感分析与PaddlePaddle
情感分析[1],又称意见挖掘,一般是指通过计算技术对一段文本的主客观性、观点、情绪的挖掘和分析,对文本的情感倾向做出分类判断。其中,一段文本可以是一个句子,一个段落或一个文档。情绪倾向可以是两类,如(正面,负面),(高兴,悲伤);也可以是三类,如(积极,消极,中性)等等。该问题通常建模为文本的分类问题。本文我们尝试使用百度开源深度学习框架PaddlePaddle来解决情感分析。
PaddlePaddle是百度旗下深度学习开源平台。Paddle是并行分布式深度学习(Parallel Distributed Deep Learning)[3]的简称,为了方便描述,后文都使用paddle来称呼PaddlePaddle。
3 .使用Paddle解决情感分析
3.1 安装
笔者以前曾经尝试过安装TensorFlow,安装TF需要配置的依赖项之多、过程之繁琐,至今仍心有余悸。Paddle安装十分方便,官方[4]给出了丰富的文档。本文只使用CPU版本,读者只需在自己的Linux/Mac上执行如下命令即可:
pip install paddlepaddle
在python脚本中导入paddle:
import paddle.v2 as paddle
若能导入成功,恭喜你,安装成功。
3.2 数据
为了便于开发人员快速开展实验,paddle提供了许多接口,提供现成的数据,例如经典的MNIST、Movielens。但若只是单纯的调用这些接口得到数据,会使得数据处理对于开发者如同黑盒子。有鉴于此,本文将使用外部数据完成情感分析实验,首先看看数据的构成。
(1)数据描述
数据采用中文文本数据,每一条数据占一行,且每条数据由一个instance(一条分好词的中文语句)和一个label组成。label有三种取值:0(negative)、1(neutral)、 2(positive),例如:
instance:你/家/客服/的/在线/时间 label:1
instance:好用/的/话/下次/可以/多/拍/点 label:2
instance:什么/垃圾/哟 label:0
数据文件中一个instance和label占一行,并且使用制表符隔开
(2)Paddle对数据的支持
Paddle支持四种数据类型:
|
dense_vector |
稠密的浮点数向量 |
|
sparse_binary_vector |
稀疏的01向量,即大部分值为0,但有值的地方必须为1 |
|
sparse_float_vector |
稀疏向量,即大部分值为0,但有值的地方可以为任何浮点数 |
|
integer |
整数 |
三种序列模式:
|
NO_SEQUENCE |
不是一条序列 |
|
SEQUENCE |
一条时间序列 |
|
SUB_SEQUENCE |
一条时间序列,且每个元素还是一个序列 |
(3)paddle中的DataReader
在训练和测试阶段,paddle都需要读取数据,为了方便,在paddle中做如下定义:
reader:reader是一个读取数据并且提供可遍历数据项的函数
这里注意,reader不一定非得是一个python generator,它只需要满足两个条件即可:
第一,无参;第二,可遍历(Iterable)
在官方代码中出现多次的reader.shuffle和batch其实都是一个python decorator,shuffle接收一个reader并返回一个将该reader中的数据打乱后的reader;batch也接收一个reader,并且返回一个个的batch_size大小的minibatch,通常的用法是:
train_reader = paddle.batch(
paddle.reader.shuffle(
origin_reader,
buf_size=1000),
batch_size=100)
在定义自己的reader时,注意这里的origin_reader是一个function object。
在本文中,我们使用最简单的one-hot编码来表示句子,假设我们已经有了一个词典来表征词的空间,词典中维护了每一个词在该空间中的index,那我们可以这样定义reader(以training reader为例):
def train(wd):
def file_reader():
with open(training_file_location) as f:
while True:
line = f.readline()
if line:
items = line.split('\t')
words = items[0].split('/')
label = items[1]
yield [[wd[word] for word in words], int(label)]
else:
return
return file_reader
3.3 模型
3.3.1 模型选择
为了展现paddle使用的灵活性以及便捷性,本文将使用三种模型来解决情感分析。分别是:LogisticRegression、LogisticRegression-FM、TextCNN,下面分别对这三种模型做一下介绍。
(1)LogisticRegression
逻辑回归(LR)在解决二分类问题时,使用如下公式来表示一个实例被分类为正类的概率
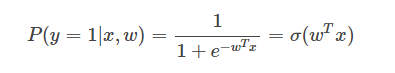
若是一个多分类逻辑回归,对于一个实例被分类为类别i的概率为
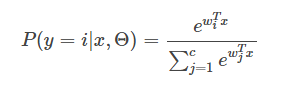
(2)LogisticRegression-FM
从(1)中看到,LR只考虑了x的线性部分,受启发与Factorization Machine[5],可以将线性部分拓展为包含x的交互部分,如下所示:
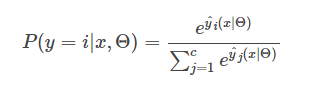
其中
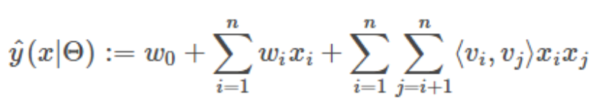
(3)TextCNN
由于CNN在图像领域取得了里程碑式的进展,TextCNN[6]将其引入了NLP处理文本分类,取得了很好的效果,其结构如下所示。
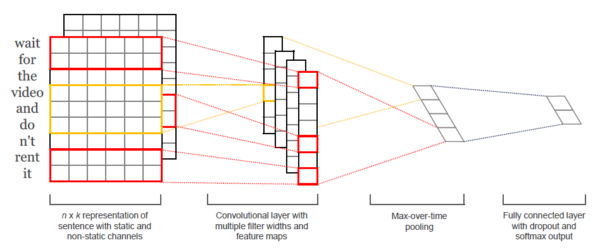
3.3.2 模型搭建
paddle中一个模型的搭建需要完成从数据到输出整个网络的定义。本文所选的三种模型均可以由神经网络模型来表示,只是在隐层(hidden layer)以及全连接层(full connected layer)有所区别而已。
(1)数据层
从上文reader的定义可以看到,reader中的数据实际是一个list,该list中包含两个元素:instance与label。其中instance的类型为integer_value_sequence(参考3.2节中paddle支持的数据类型),label的类型为integer,例如:
[[10, 201, 332, 103, 88], 1]
因此可以定义如下数据层:
data = paddle.layer.data("instance", paddle.data_type.integer_value_sequence(input_dim))
lbl = paddle.layer.data("label", paddle.data_type.integer_value(3))
其中instance和label都是该数据层的名字,在训练的时候,可以通过一个feeding参数将训练数据中的元素对应到对应的数据层。接着定义embedding层如下:
emb = paddle.layer.embedding(input=data, size=emb_dim)
在经过embedding后,数据变为如下形式:
[[vect_10, vect_201, vect_332, vect_103, vect_88], 1]
其中vect_i代表该向量只有下标为i的元素有值,其他都为0。
(2)模型层
首先我们搭建最简单的逻辑回归:
pool = paddle.layer.pooling(input=emb, pooling_type=paddle.pooling.Sum())
output = paddle.layer.fc(input=pool, size=class_dim, act=paddle.activation.Softmax())
这里十分简单,先使用pooling.Sum将word embedding的每一维相加得到整个句子的embedding,再使用全连接层得到大小为class_dim的softmax结果即可。注意在paddle中,这里若不先做池化,在训练时会抛出实例数与标签数不相等的异常,这是由于emb的结果是词的embedding的List,而paddle会把这个List中的每个元素当做一个instance,使用pooling.Sum正好将一个List转化为一个句子的embedding。
然后搭建带FM的逻辑回归:
pool = paddle.layer.pooling(input=emb, pooling_type=paddle.pooling.Sum())
linear_part = paddle.layer.fc(input=pool, size=1, act=paddle.activation.Linear())
interaction_part = paddle.layer.factorization_machine(input=pool,
factor_size=factor_size,
act=paddle.activation.Linear())
output = paddle.layer.fc(input=[linear_part, interaction_part], size=class_dim,
act=paddle.activation.Softmax())
它与逻辑回归的唯一区别就是不止利用了x的线性,还利用了x各个维度之间的交互。这里我们用linear_part得到线性部分,再利用interaction_part得到大小为factor_size的交互部分,在全连接层将linear_part和interaction_part联合起来得到softmax输出。
最后搭建卷积神经网络(CNN):
pool_1 = conv_pool_layer(input=emb,
emb_dim=emb_dim,
hid_dim=hid_dim,
context_len=2,
act=paddle.activation.Relu(),
pooling_type=paddle.pooling.Max())
pool_2 = conv_pool_layer(input=emb,
emb_dim=emb_dim,
hid_dim=hid_dim,
context_len=3,
act=paddle.activation.Relu(),
pooling_type=paddle.pooling.Max())
output = paddle.layer.fc(input=[pool_1, pool_2], size=class_dim,
act=paddle.activation.Softmax())
其中定义conv_pool_layer为:
def conv_pool_layer(input, emb_dim, hid_dim, context_len, act, pooling_type):
with paddle.layer.mixed(size=emb_dim * context_len) as m:
m += paddle.layer.context_projection(input=input, context_len=context_len)
fc = paddle.layer.fc(m, size=hid_dim, act=act)
return paddle.layer.pooling(input=fc, pooling_type=pooling_type)
在这里我们只对相邻的2个词(Bi-Gram)和3个词(Tri-Gram)做卷积,并使用ReLU激活函数以及最大池化操作。为了方便,paddle在做卷积和池化时封装了许多可以直接调用的接口(例如paddle.v2.networks.sequence_conv_pool),读者可以参考paddle的官方文档。
(3)loss层
由于是一个多分类任务,loss可以用最常用的cross-entropy来定义
lbl = paddle.layer.data("label", paddle.data_type.integer_value(3))
cost = paddle.layer.cross_entropy_cost(input=output, label=lbl)
经过了数据层、模型层和loss层的定义,整个网络结构就搭建完成了,下边给出上文描述的逻辑回归的代码示例:
def logistic_regression(input_dim,
class_dim,
emb_dim=128,
is_predict=False):
data=paddle.layer.data("instance", paddle.data_type.integer_value_sequence(input_dim))
emb = paddle.layer.embedding(input=data, size=emb_dim)
pool = paddle.layer.pooling(input=emb, pooling_type=paddle.pooling.Sum())
output = paddle.layer.fc(input=pool,
size=class_dim,
act=paddle.activation.Softmax())
if not is_predict:
lbl = paddle.layer.data("label", paddle.data_type.integer_value(3))
cost = paddle.layer.cross_entropy_cost(input=output, label=lbl)
return cost
else:
return output
其中为了测试方便,加入了一个is_predict标识是否是测试,在训练的时候,它返回的是模型在训练数据上的Loss,在测试的时候,它直接返回softmax后的输出。
3.3.3 模型训练与存储
根据上文定义的Loss,直接创建好整个模型的参数
cost = logistic_regression(dict_dim, class_dim=class_dim)
parameters = paddle.parameters.create(cost)
parameters负责维护整个模型在训练阶段或者测试阶段网络结构中的参数,也就是网络结构中的所有的w。在paddle中,目标函数的优化是通过一个optimizer来进行的,为了方便用户操作,paddle封装好了丰富的优化算法供用户选择,本文选择adam算法作为示例。定以好optimizer后,可以直接定义trainer:
adam_optimizer = paddle.optimizer.Adam( learning_rate=2e-3,
regularization=paddle.optimizer.L2Regularization(rate=8e-4),
model_average=paddle.optimizer.ModelAverage(average_window=0.5))
trainer = paddle.trainer.SGD(cost=cost, parameters=parameters,
update_equation=adam_optimizer)
为了方便用户对整个训练过程进行监控,paddle定义了多种event来反映训练的状态,用户可以从特定的event获取当前的输出、lost值等各种信息,并定制自己的event_handler,在event_handler中可以处理以下六种事件:
|
EndIteration |
标识一轮迭代的结束 |
|
BeginIteration |
标识一轮迭代的开始 |
|
BeginPass |
标识一轮epoch的开始 |
|
EndPass |
标识一轮epoch的结束 |
|
TestResult |
trainer.test返回的结果 |
|
EndForwardBackward |
标识一轮ForwardBackward的结束 |
下边以本文定义的event_handler为例进行说明,它在每个minibatch结束时打印出cost等信息,并在每个pass结束后,将参数存储到文件。
def event_handler(event):
if isinstance(event, paddle.event.EndIteration):
if event.batch_id % 100 == 0:
print "\nPass %d, Batch %d, Cost %f, %s" % (
event.pass_id, event.batch_id, event.cost, event.metrics)
else:
sys.stdout.write('.')
sys.stdout.flush()
if isinstance(event, paddle.event.EndPass):
with open('./params_pass_%d.tar' % event.pass_id, 'w') as f:
trainer.save_parameter_to_tar(f)
在完成所有的配置后,即可开始模型的训练
trainer.train( reader=train_reader, event_handler=event_handler,
eeding=feeding, num_passes=10)
其中feeding定义了数据层的映射:feeding={'instance': 0, 'label': 1},它表示将数据中的第一个元素映射到名为instance的数据层,第二个元素映射到名为label的数据层,这也是数据层中取名原因。
3.4 测试与结果分析
测试阶段我们加载训练阶段保存的parameters文件,并使用paddle的infer得到输出:
with open("./params_pass_9.tar") as f:
parameters = paddle.parameters.Parameters.from_tar(f)
out = cn_sentiment.logistic_regression(dict_dim, class_dim=class_dim, is_predict=True)
probs = paddle.infer(output_layer=out, parameters=parameters, input=x)
在本文中其中probs存储的就是每个test instance属于三个类别的概率,概率最高的那个类别即为模型的预测结果。下面将测试结果总结汇报如下:
|
Model |
Acc |
|
LogisticRegression |
0.932857991682 |
|
LogisticRegression-FM |
0.933143264763 |
|
CNN_Sigmoid |
0.935828877005 |
|
CNN_Relu |
0.953060011884 |
从结果可以看出,LR-FM考虑了特征之间的交叉,其表现优于LR。但CNN由于其更强大的表现能力结果相较于LR有大幅提升,在实验中也顺便验证了ReLU激活函数对比于sigmoid的优势,这是因为ReLU可以解决训练过程中出现的梯度饱和效应(Saturation Effect)。
4 .总结与展望
本文结合一个具体例子介绍了情感分析在对话系统中的应用。情感分析对于对话系统,至少有以下四点意义:为转人工提供依据;优化意图识别;挖掘对话数据,提升客服质量;协助强化学习。笔者目前正在“智能一点”从事对话机器人的开发,我们期望利用NLP的技术来提高对话的质量并帮助客户节省开支并提高效率,对这一点的感触就更深了。
除此之外,本文还展示如何使用paddle step-by-step地解决情感分析问题,并在实验中简单对比了用paddle实现的几种模型的结果。本文的目的在于,给深度学习的入门开发者提供一个如何使用paddle开发的直观感受,起到抛砖引玉的作用。
当然,本文只是管中窥豹。正如paddle官网的slogan:“易学易用的分布式深度学习平台”,paddle无论安装还是使用都十分方便,甚至连经典任务的基本数据集都做了准备,特别适合刚接触深度学习的人员上手。但若以为paddle只是这么简单那就大错特错了,如同目前流行的深度学习框架一样,paddle不仅支持GPU,还支持多种分布式集群的部署和运行方式,包括fabric集群、openmpi集群、Kubernetes单机、Kubernetes distributed分布式等。这些特性只能留待读者自己探索了。
5 .引用
[1] 杨立公, 朱俭, 汤世平. 文本情感分析综述[J]. 计算机应用, 2013, 33(6):1574-1578.
[2] Serban I V, Sankar C, Germain M, et al. A Deep Reinforcement Learning Chatbot[J]. 2017.
[3] http://ai.baidu.com/paddlepaddle
[4] http://staging.paddlepaddle.org/docs/develop/documentation/zh/getstarted/index_cn.html
[5] Rendle S. Factorization Machines[C]// IEEE, International Conference on Data Mining. IEEE, 2011:995-1000.
[6] Kim Y. Convolutional Neural Networks for Sentence Classification[J]. Eprint Arxiv, 2014.