Hadoop HDFS(大数据分布式文件系统)
Hadoop分布式文件系统(HDFS)是一个分布式文件系统,适用于商用硬件上高数据吞吐量对大数据集的访问的需求。
该系统仿效了谷歌文件系统(GFS),数据在相同节点上以复制的方式进行存储以实现将数据合并计算的目的。
该系统的主要设计目标包括:容错,可扩展性,高效性和可靠性。
HDFS采用了MapReduce,不迁移数据而是以将处理任务迁移到物理节点(保存数据)的方式降低网络I/O。HDFS是Apache Hadoop的一个子项目并且安装Hadoop。
OpenStack的对象存储Swift
OpenStack Swift提供一个类似Amazon S3的对象存储。其主要特点为:
- 所有的存储对象都有自身的元数据和一个URL,这些对象在尽可能唯一的区域复制3次,而这些区域可被定义为一组驱动器,一个节点,一个机架等。
- 开发者通过一个RESTful HTTP API与对象存储系统相互作用。
- 对象数据可以放置在集群的任何地方。
- 在不影响性能的情况下,集群通过增加外部节点进行扩展。这是相对全面升级,性价比更高的近线存储扩展。
- 数据无需迁移到一个全新的存储系统。
- 集群可无宕机增加新的节点。
- 故障节点和磁盘可无宕机调换。
- 在标准硬件上运行,例如戴尔,HP和Supermicro。
公有云对象存储
公有云大都只有对象存储。例如,谷歌云存储是一个快速,具有可扩展性和高可用性的对象存储。而且云存储无需一种模式也就是图像,视频文件就可以存储海量数据。
Amazon类似产品就是S3: http://aws.amazon.com/s3;
微软类似产品Azure Bolb:http://azure.microsoft.com/en-us/documentation/articles/storage-dotnet-how-to-use-blobs/;
阿里类似的有OSS:https://www.aliyun.com/product/oss/;
Facebook用于图片存储的Haystack

Facebook Haystack拥有大量元数据,适用于图片的对象存储,采用每张图片一个文件的方式取代NFS文件系统。
http://cse.unl.edu/~ylu/csce990/notes/HayStack_Facebook_ShakthiBachala.ppt;
此外,Facebook着眼于长尾服务,因此传统缓存和CDN(内容发布网络)的表现并不甚佳。一般正常的网站有99%CDN点击量,但Facebook只有约80%CDN点击率。
f4: Facebook的暖性BLOB存储
Haystack最初是用于Facebook图片应用的主要存储系统。到2016年已有近8年的历史。
这期间它通过比如减少磁盘数设法读取一个BLOB到1,跨地理位置通过复制(3个复制因子即文件副本数)实现容错等更多优化而运作良好。在此期间Facebook虽然服务良好但依然进行了演变。
截止2014年2月,Haystack存储了约4000亿张图片。
https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-muralidhar.pdf
目前,f4存储了超过65PB的本地BLOB,而且将其有效复制因子从3.6降低到任意2.8或2.1。
f4提供低延迟,可恢复磁盘,主机,机柜和数据中心故障并为暖性BLOB提供足够的吞吐量。
PS:f4仅存储“暖性”图片
OpenStack块存储Cinder
OpenStack(类似商业云)还可以作为一个Linux访问的文件系统提供传统块存储。Cinder能虚拟化块存储设备池并向需要和消费这些资源的终端用户提供一个自助服务API,而无需了解存储部署的实际位置或是存储设备的类型。
OpenStack Cinder类似于亚马逊EBS(Elastic Block Storage )和微软Azure Files以及谷歌Persistent Storage。
Lustre
Lustre是一个并行分布式文件系统,通常用于大规模集群计算。??它的名字取自Linux和cluster(集群)的组合词。Lustre文件系统软件遵循GPL2认证协议并为(各类规模)计算机集群提供高性能文件系统。
因为Lustre文件系统拥有高性能的能力和开放式认证,所以经常应用于超级计算机。
Lustre文件系统具有可扩展性,可支持在数百台服务器上配置数万客户端节点,PB级容量的多个计算机集群,并超出TB级聚合I/O吞吐量。
这让Lustre文件系统受到拥有大型数据中心企业的青睐,其中也包括例如气象,虚拟,石油天然气,生命科学,多功能媒体和金融行业。Lustre曾辗转过几家企业,最近的三个所有者(时间先后排序)依次为甲骨文,Whamcloud和英特尔。
Gluster
http://www.gluster.org/http://en.wikipedia.org/wiki/Gluster
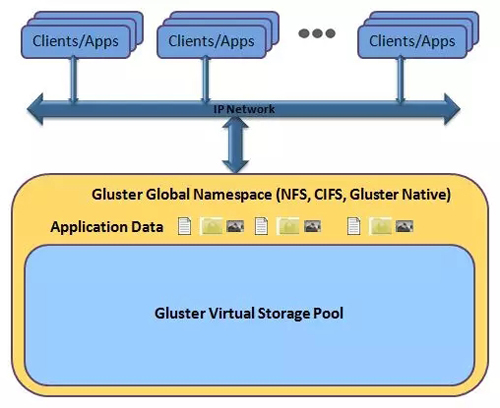
GlusterFS遵循Infiniband RDMA或TCP/IP协议创建块集中存储,在单一全局命名空间内集中磁盘和内存资源并管理数据。
对于公有云部署,GlusterFS提供了一个AWS AMI(亚马逊机器镜像)。它不是在物理服务器上部署,而是在Elastic Compute Cloud (EC2)实例上部署,并且地层存储空间是Amazon的Elastic Block Storage(EBS)。
在这样的环境里,容量通过部署更多EBS存储设备进行扩展,性能则通过部署更多EC2实例进行增强,而可用性通过AWS可用区域之间进行多方复制来提升。
FUSE(Filesystem in Userspace 用户空间文件系统)
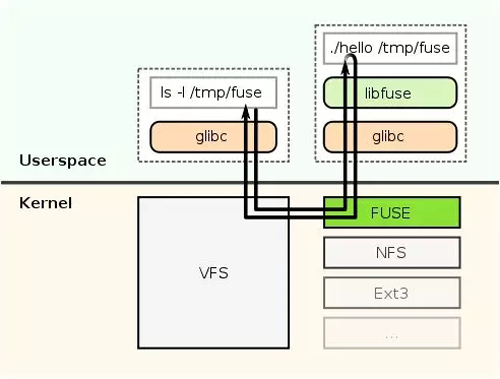
FUSE GPL/LGPL认证是一个操作系统机制,针对类Unix计算操作系统,让用户无需编辑内核代码即可构建自身文件系统。这虽然是通过在用户空间内运行文件系统代码实现,但FUSE模块仅提供了一个到达真正内核接口的一架“桥梁”。
FUSE最初是作为一个可加载的核心模块来实现的,通过GlusterFS使用,尤其适用于编写虚拟文件系统。但与传统文件系统,尤其是可存储数据和从磁盘上检索数据的系统不同,虚拟文件系统检索实际上无法存储自身数据。它们充当一个现有文件系统或存储设备的视图或翻译。
Ceph
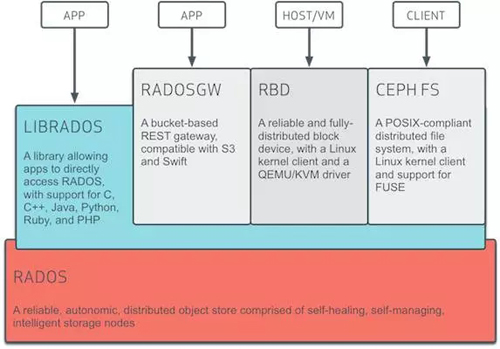
Cphe是红帽的,Ceph是一个遵循LGPL协议的存储平台,它可以在单个分布式节点上同时支持对象存储,块存储和文件存储。
Cphe主要设计的初衷是变成一个可避免单节点故障的分布式文件系统,EB级别的扩展能力,而且是一种开源自由软件,许多超融合的分布式文件系统都是基于Ceph开发的,作为开源软件在超融合商业领域的应用,Ceph因为性能等问题被诟病,但不乏许多厂商在Ceph上不断优化和努力。
IBM General Parallel File System(GPFS通用并行文件系统)
这个专有GPFS是一个由IBM开发的高性能集群文件系统。它可以在共享磁盘或非共享分布式并行模式中进行部署。
GPFS-SNC,其中SNC代表Shared Nothing Cluster(非共享集群),它是2012年12月正式发布的GPFS 3.5版本,如今被称为GPFS-FPO(文件配置优化)。这让GPFS可以在一个联网服务器的集群上采用本地连接磁盘,而不需要配置共享磁盘的专用服务器(例如使用SAN),GPFS-FPO可充当HDFS兼容的文件系统。
GPFS时常通过调用计算集群上的MPI-IO(Message Passing Interface)进行访问。功能包括:
分布式元数据处理。包括目录树。没有单独的“目录控制器”或“索引服务器”管理文件系统。
对非常大的目录进行高效索引目录项。很多文件系统被限制在单一目录(通常, 65536或类似的小二进制数)中的少数文件内,而GPFS并没有这样的限制。
分布式锁定。该功能考虑了完整的Posix文件系统语义,包括锁定文件进行独占访问。
Global Federated File System(GFFS全局联合文件系统)
XSEDE文件系统在美国弗吉尼亚大学Genesis II项目的一部分。
GFFS的出现是源于一个对诸如文件系统的资源以一种联合,安全,标准化,可扩展和透明化的方式进行访问和远程操作的需求,而无需数据所有者或应用程序开发者和用户改变他们存储和访问数据的任何方式。
GFFS通过采用一个全局基于路径的命名空间实现,例如/data/bio/file1。
在现有文件系统中的数据,无论它们是否是 Windows文件系统, MacOS文件系统,AFS,Linux或者Lustre文件系统都可以导出或链接到全局命名空间。
例如,一个用户可以将它 “C” 盘上一个本地根目录结构,C:\work\collaboration-with-Bob导出到全局命名空间,/data/bio/project-Phil,那么用户 “C” 盘\work\collaboration-with-bob 内的文件和目录将会受到访问限制,用户可以通过/data/bio/project-Bob路径在 GFFS上访问。
***谈一下,最常见的GPFS和HDFS有什么区别?
GPFS和Hadoop的HDFS系统对比起来相当有趣,它设计用于在商用硬件上存储类似或更大的数据——换言之就是,不配置 RAID 磁盘的数据中心和一个SAN。
HDFS还将文件分割成块,并将它们存储在不同的文件系统节点内。
HDFS对磁盘可靠性的依赖并不高,它可以在不同的节点内存储块的副本。保存单一副本块的一个节点出现故障是小问题,可以再复制该组其它有效块内的副本。相较而言,虽然GPFS支持故障节点恢复,但它是一个更严重的事件,它可能包括数据(暂时性)丢失的高风险。
GPFS支持完整的Posix文件系统语义。 HDFS和GFS(谷歌文件系统)并不支持完整的Posix语义。
GPFS跨文件系统分布它的目录索引和其它元数据。相反, Hadoop将它们保留在主要和次要Namenode中,大型服务器必须在RAM内存储所有的索引信息。
GPFS将文件分割成小块。Hadoop HDFS喜欢64MB甚至更多的块,因为这降低了Namenode的存储需求。小块或很多小的文件会快速填充文件系统的索引,因此限制了文件系统的大小。
说到分布式文件系统,不得不提到许多超融合厂商,一部分是基于Ceph的,还有一部分是完全自主研发的。