前言
最近在学习kubernetes过程中,想实现pod数据的持久化。在调研的过程中,发现ceph在最近几年发展火热,也有很多案例落地企业。在选型方面,个人更加倾向于社区火热的项目,GlusterFS、Ceph都在考虑的范围之内,但是由于GlusterFS只提供对象存储和文件系统存储,而Ceph则提供对象存储、块存储以及文件系统存储。怀着对新事物的向往,果断选择Ceph来实现Ceph块存储对接kubernetes来实现pod的数据持久化。
一、初始Ceph
1.1了解什么是块存储/对象存储/文件系统存储?
直接进入主题,ceph目前提供对象存储(RADOSGW)、块存储RDB以及CephFS文件系统这3种功能。对于这3种功能介绍,分别如下:
1.对象存储,也就是通常意义的键值存储,其接口就是简单的GET、PUT、DEL和其他扩展,代表主要有Swift、S3以及Gluster等;
2.块存储,这种接口通常以QEMUDriver或者KernelModule的方式存在,这种接口需要实现Linux的BlockDevice的接口或者QEMU提供的BlockDriver接口,如Sheepdog,AWS的EBS,青云的云硬盘和阿里云的盘古系统,还有Ceph的RBD(RBD是Ceph面向块存储的接口)。在常见的存储中DAS、SAN提供的也是块存储;
3.文件存储,通常意义是支持POSIX接口,它跟传统的文件系统如Ext4是一个类型的,但区别在于分布式存储提供了并行化的能力,如Ceph的CephFS(CephFS是Ceph面向文件存储的接口),但是有时候又会把GlusterFS,HDFS这种非POSIX接口的类文件存储接口归入此类。当然NFS、NAS也是属于文件系统存储;
1.2Ceph组件介绍
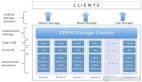
从下面这张图来简单学习下,Ceph的架构组件。(提示:本人在学习过程中所绘,如果发现问题欢迎留言,不要喷我哟)
Monitor,负责监视整个集群的运行状况,信息由维护集群成员的守护程序来提供,各节点之间的状态、集群配置信息。Cephmonitormap主要包括OSDmap、PGmap、MDSmap和CRUSH等,这些map被统称为集群Map。cephmonitor不存储任何数据。下面分别开始介绍这些map的功能:
- Monitormap:包括有关monitor节点端到端的信息,其中包括Ceph集群ID,监控主机名和IP以及端口。并且存储当前版本信息以及最新更改信息,通过"cephmondump"查看monitormap。
- OSDmap:包括一些常用的信息,如集群ID、创建OSDmap的版本信息和最后修改信息,以及pool相关信息,主要包括pool名字、pool的ID、类型,副本数目以及PGP等,还包括数量、状态、权重、最新的清洁间隔和OSD主机信息。通过命令"cephosddump"查看。
- PGmap:包括当前PG版本、时间戳、最新的OSDMap的版本信息、空间使用比例,以及接近占满比例信息,同事,也包括每个PGID、对象数目、状态、OSD的状态以及深度清理的详细信息。通过命令"cephpgdump"可以查看相关状态。
- CRUSHmap:CRUSHmap包括集群存储设备信息,故障域层次结构和存储数据时定义失败域规则信息。通过命令"cephosdcrushmap"查看。
- MDSmap:MDSMap包括存储当前MDSmap的版本信息、创建当前的Map的信息、修改时间、数据和元数据POOLID、集群MDS数目和MDS状态,可通过"cephmdsdump"查看。
OSD,CephOSD是由物理磁盘驱动器、在其之上的Linux文件系统以及CephOSD服务组成。CephOSD将数据以对象的形式存储到集群中的每个节点的物理磁盘上,完成存储数据的工作绝大多数是由OSDdaemon进程实现。在构建CephOSD的时候,建议采用SSD磁盘以及xfs文件系统来格式化分区。BTRFS虽然有较好的性能,但是目前不建议使用到生产中,目前建议还是处于围观状态。
Ceph元数据,MDS。ceph块设备和RDB并不需要MDS,MDS只为CephFS服务。
RADOS,ReliableAutonomicDistributedObjectStore。RADOS是ceph存储集群的基础。在ceph中,所有数据都以对象的形式存储,并且无论什么数据类型,RADOS对象存储都将负责保存这些对象。RADOS层可以确保数据始终保持一致。
librados,librados库,为应用程度提供访问接口。同时也为块存储、对象存储、文件系统提供原生的接口。
ADOS块设备,它能够自动精简配置并可调整大小,而且将数据分散存储在多个OSD上。
RADOSGW,网关接口,提供对象存储服务。它使用librgw和librados来实现允许应用程序与Ceph对象存储建立连接。并且提供S3和Swift兼容的RESTfulAPI接口。
CephFS,Ceph文件系统,与POSIX兼容的文件系统,基于librados封装原生接口。
简单说下CRUSH,ControlledReplicationUnderScalableHashing,它表示数据存储的分布式选择算法,ceph的高性能/高可用就是采用这种算法实现。CRUSH算法取代了在元数据表中为每个客户端请求进行查找,它通过计算系统中数据应该被写入或读出的位置。CRUSH能够感知基础架构,能够理解基础设施各个部件之间的关系。并且CRUSH保存数据的多个副本,这样即使一个故障域的几个组件都出现故障,数据依然可用。CRUSH算是使得ceph实现了自我管理和自我修复。
RADOS分布式存储相较于传统分布式存储的优势在于:
1.将文件映射到object后,利用ClusterMap通过CRUSH计算而不是查找表方式定位文件数据存储到存储设备的具体位置。优化了传统文件到块的映射和BlockMAp的管理。
2.RADOS充分利用OSD的智能特点,将部分任务授权给OSD,最大程度地实现可扩展。
二、安装Ceph
2.1环境准备
##环境说明
主机IP功能
ceph-node01192.168.58.128 deploy、mon*1、osd*3
ceph-node02192.168.58.129 mon*1、osd*3
ceph-node03192.168.58.130 mon*1、osd*3
##准备yum源
- cd /etc/yum.repos.d/ && sudo mkdir bak
- sudo mv *.repo bak/
- sudo wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
- sudo wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
- sudo sed -i '/aliyuncs/d' /etc/yum.repos.d/CentOS-Base.repo
- sudo sed -i '/aliyuncs/d' /etc/yum.repos.d/epel.repo
- sudo sed -i 's/$releasever/7/g' /etc/yum.repos.d/CentOS-Base.repo
##添加Ceph源
- sudo cat <<EOF > /etc/yum.repos.d/ceph.repo
- [Ceph]
- name=Ceph packages for x86_64
- baseurl=https://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/
- enabled=1
- gpgcheck=1
- type=rpm-md
- gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
- [Ceph-noarch]
- name=Ceph noarch packages
- baseurl=https://mirrors.aliyun.com/ceph/rpm-jewel/el7/noarch/
- enabled=1
- gpgcheck=1
- type=rpm-md
- gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
- [ceph-source]
- name=Ceph source packages
- baseurl=https://mirrors.aliyun.com/ceph/rpm-jewel/el7/SRPMS/
- enabled=1
- gpgcheck=1
- type=rpm-md
- gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
- EOF
##配置免密钥(略)
提示:如果使用普通用户进行安装,请授予用户相关权限,如下:
a.将yangsheng用户加入到sudo权限(yangshengALL=(ALL)NOPASSWD:ALL)
b.将/etc/sudoers中的“Defaultsrequiretty”注释
2.2开始安装
##安装部署工具(在192.168.58.128执行如下操作)
- yum makecache
- yum -y install ceph-deploy
- ceph-deploy --version
- 1.5.39
##初始化monitor
- mkdir ceph-cluster && cd ceph-cluster
- ceph-deploy new ceph-node01 ceph-node02 ceph-node03
根据自己的IP配置向ceph.conf中添加public_network,并稍微增大mon之间时差允许范围(默认为0.05s,现改为2s):
- # change default replica 3 to 2
- osd pool default size = 2
- public network = 192.168.58.0/24
- cluster network = 192.168.58.0/24
##安装ceph
- ceph-deployinstallceph-node01ceph-node02ceph-node03
##开始部署monitor
- ceph-deploy mon create-initial
- [root@ceph-node01 ceph]# ls
- ceph.bootstrap-mds.keyring ceph.bootstrap-osd.keyring ceph.client.admin.keyring ceph-deploy-ceph.log rbdmap
- ceph.bootstrap-mgr.keyring ceph.bootstrap-rgw.keyring ceph.conf ceph.mon.keyring
查看集群状态
- [root@ceph-node01 ceph]# ceph -s
- cluster b5108a6c-7e3d-4295-88fa-88dc825be3ba
- health HEALTH_ERR
- no osds
- monmap e1: 3 mons at {ceph-node01=192.168.58.128:6789/0,ceph-node02=192.168.58.129:6789/0,ceph-node03=192.168.58.130:6789/0}
- election epoch 6, quorum 0,1,2 ceph-node01,ceph-node02,ceph-node03
- osdmap e1: 0 osds: 0 up, 0 in
- flags sortbitwise,require_jewel_osds
- pgmap v2: 64 pgs, 1 pools, 0 bytes data, 0 objects
- 0 kB used, 0 kB / 0 kB avail
- 64 creating
提示:Monitor创建成功后,检查集群的状态,此时集群状态并不处于健康状态。
##开始部署OSD
- ### 列出节点所有磁盘信息
- ceph-deploy disk list ceph-node01 ceph-node02 ceph-node03
- ### 清除磁盘分区和内容
- ceph-deploy disk zap ceph-node01:sdb ceph-node02:sdb ceph-node03:sdb
- ### 分区格式化并激活
- ceph-deploy osd create ceph-node01:sdb ceph-node02:sdb ceph-node03:sdb
- ceph-deploy osd activate ceph-node01:sdb ceph-node02:sdb ceph-node03:sdb
此时,再次查看集群状态
- [root@ceph-node01 ceph-cluster]# ceph -s
- cluster 86fb7c8b-9ad1-4eaf-a24c-0d2d9f36ab29
- health HEALTH_OK
- monmap e2: 3 mons at {ceph-node01=192.168.58.128:6789/0,ceph-node02=192.168.58.129:6789/0,ceph-node03=192.168.58.130:6789/0}
- election epoch 6, quorum 0,1,2 ceph-node01,ceph-node02,ceph-node03
- osdmap e15: 3 osds: 3 up, 3 in
- flags sortbitwise,require_jewel_osds
- pgmap v32: 64 pgs, 1 pools, 0 bytes data, 0 objects
- 100 MB used, 45946 MB / 46046 MB avail
- 64 active+clean
2.3清理环境
如果之前部署失败了,不必删除ceph客户端,或者重新搭建虚拟机,只需要在每个节点上执行如下指令即可将环境清理至刚安装完ceph客户端时的状态!强烈建议在旧集群上搭建之前清理干净环境,否则会发生各种异常情况。
- sudo ps aux|grep ceph | grep -v "grep"| awk '{print $2}'|xargs kill -9
- sudo ps -ef|grep ceph
- sudo umount /var/lib/ceph/osd/*
- sudo rm -rf /var/lib/ceph/osd/*
- sudo rm -rf /var/lib/ceph/mon/*
- sudo rm -rf /var/lib/ceph/mds/*
- sudo rm -rf /var/lib/ceph/bootstrap-mds/*
- sudo rm -rf /var/lib/ceph/bootstrap-osd/*
- sudo rm -rf /var/lib/ceph/bootstrap-rgw/*
- sudo rm -rf /var/lib/ceph/tmp/*
- sudo rm -rf /etc/ceph/*
- sudo rm -rf /var/run/ceph/*
三、配置客户端
3.1安装客户端
- ssh-copy-id 192.168.58.131
- ceph-deploy install 192.168.58.131
将Ceph配置文件复制到192.168.58.131。
- ceph-deploy config push 192.168.58.131
3.2新建用户密钥
客户机需要ceph秘钥去访问ceph集群。ceph创建了一个默认的用户client.admin,它有足够的权限去访问ceph集群。但是不建议把client.admin共享到所有其他的客户端节点。这里我用分开的秘钥新建一个用户(client.rdb)去访问特定的存储池。
- cephauthget-or-createclient.rbdmon'allowr'osd'allowclass-readobject_prefixrbd_children,allowrwxpool=rbd'
为192.168.58.131上的client.rbd用户添加秘钥
- cephauthget-or-createclient.rbd|ssh192.168.58.131tee/etc/ceph/ceph.client.rbd.keyring
到客户端(192.168.58.131)检查集群健康状态
- [root@localhost ~]# cat /etc/ceph/ceph.client.rbd.keyring >> /etc/ceph/keyring
- [root@localhost ~]# ceph -s --name client.rbd
- cluster 86fb7c8b-9ad1-4eaf-a24c-0d2d9f36ab29
- health HEALTH_OK
- monmap e2: 3 mons at {ceph-node01=192.168.58.128:6789/0,ceph-node02=192.168.58.129:6789/0,ceph-node03=192.168.58.130:6789/0}
- election epoch 6, quorum 0,1,2 ceph-node01,ceph-node02,ceph-node03
- osdmap e15: 3 osds: 3 up, 3 in
- flags sortbitwise,require_jewel_osds
- pgmap v32: 64 pgs, 1 pools, 0 bytes data, 0 objects
- 100 MB used, 45946 MB / 46046 MB avail
- 64 active+clean
3.3创建块设备
- rbd create foo --size 4096 --name client.rbd # 创建一个 4096MB 大小的RADOS块设备
- rbd create rbd01 --size 10240 --name client.rbd # 创建一个 10240MB 大小的RADOS块设备
映射块设备
- [root@localhost ceph]# rbd create rbd02 --size 10240 --image-feature layering --name client.rbd
- [root@localhost ceph]# rbd map --image rbd02 --name client.rbd /dev/rdb02
- /dev/rbd0
提示:在映射块设备的时候,发生了如下错误。
- [root@localhost ceph]# rbd map --image rbd01 --name client.rbd /dev/rdb01
- rbd: sysfs write failed
- RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable".
- In some cases useful info is found in syslog - try "dmesg | tail" or so.
- rbd: map failed: (6) No such device or address
解决该办法有多种方式,分别如下所示:
1.在创建的过程中加入如下参数"--image-featurelayering"也解决该问题。
2.手动disable掉相关参数,如下所示:
- rbdfeaturedisablefooexclusive-lock,object-map,fast-diff,deep-flatten
3.在每个ceph节点的配置文件中,加入该配置项"rbd_default_features=1"。
3.4检查被映射的块设备
- [root@localhost ceph]# rbd showmapped --name client.rbd
- id pool image snap device
- 0 rbd rbd02 - /dev/rbd0
创建并挂载该设备
- fdisk -l /dev/rbd0
- mkfs.xfs /dev/rbd0
- mkdir /mnt/ceph-disk1
- mount /dev/rbd1 /mnt/ceph-disk1
验证
- [root@localhost ceph]# df -h /mnt/ceph-disk1/
- 文件系统 容量 已用 可用 已用% 挂载点
- /dev/rbd0 10G 33M 10G 1% /mnt/ceph-disk1
一个ceph块设备就创建完成。