这篇文章中,你将了解到什么是迁移学习?它的应用有哪些?以及为什么它应该是数据科学家所需拥有的关键技能?
实际上,迁移学习并不是机器学习模型,也不是机器学习领域内的相关技术,它是机器学习中的一种“设计方法论”。而另一种类型的“设计方法论”就是像主动学习(active learning)这样的。
在后续的文章中,我将解释该如何将主动学习与迁移学习相结合使用,从而较佳地利用现有(和新的)数据。从广义上说,机器学习应用往往在利用外部信息以提高性能或泛化能力时会使用迁移学习。
迁移学习的定义
迁移学习的总体思路是使用从任务中所学到的知识,在那些只有少量已标注数据可用的环境中,获得大量可用的已标注数据。通常来说,创建已标注数据的成本很大,所以充分利用现有数据集是关键所在。
在传统的机器学习模型中,主要目标将从训练数据中学习到的模式泛化到不可见数据中。通过迁移学习,你可以尝试从已经学习到不同任务的模式开始,启动这个泛化过程。从本质上说,我们应该从一个已经学习能够解决不同任务的模式开始,而不是从头开始(通常是随机初始化的)进行该学习过程。

相较于必须从原始像素值着手,能够从图像中区分线条和形状(左)使得更容易确定某物是否是“汽车”。迁移学习使得你能够利用来自其他计算机视觉模型的学习模式。
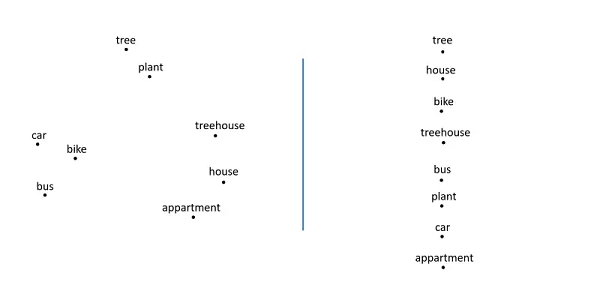
在NLP中,存在多种不同的方法用以表示单词(像左侧所表示的词嵌入,右侧表示所表示的)。通过迁移学习,机器学习模型可以充分利用不同单词之间存在的关系。
在多种领域中,知识和模式的迁移都是有可能的。而本文将通过查看几个不同领域的若干个示例对迁移学习加以说明。最终目标是激励数据科学家在他们的机器学习项目中使用迁移学习,并让他们意识到其优缺点。
我之所以认为对迁移学习的理解是数据科学家应该具备的关键技能,原因有三,如下所示:
迁移学习在任何一种学习中都是至关重要的。可以这样说,对于人生中每一个任务或是难题,我们没有被授以解决方法以获得该事件的成功。每个人都会遇到从未遇到过的情况,我们仍然设法以特殊的方式解决问题。从大量的经验中学习,并将“知识”导入到新的环境中,这正是迁移学习的全部意义所在。从这个角度来看,迁移学习和泛化在概念层面上是非常相似的,两者的主要区别在于迁移学习经常被用于“跨任务迁移知识,而不是在一个特定的任务中进行泛化”。因此,迁移学习与所有机器学习模型所必需的泛化概念,两者之间有着内在的联系。
迁移学习是确保在存含有大量小数据环境下实现深度学习技术突破的关键所在。在研究中,深度学习几乎是无处不在,但是在很多实际生活场景,我们通常没有数百万个标记数据点用以对模型进行训练。深度学习技术需要大量的数据以调整神经网络中的数百万个参数。特别是在监督学习的情况下,这意味着你需要大量(非常昂贵的)已标记数据。标记图像听起来微不足道,但是对于自然语言处理(NLP)中的样本来说,需要专家知识才能创建大型标记数据集。例如,宾州树库(Penn treebank)是一个词性标记语料库,已经有7年的历史了,需要许多具备专业知识的语言学家密切合作对其加以改进和完善。迁移学习是减少数据集所需大小的一种方法,以使神经网络成为可行的选择。其他可行的选择正朝着具有更多概率性启发的模型发展,这些模型通常更适合于处理有限的数据集。
迁移学习有着显著的优点,同时缺点也是显而易见的。了解这些缺点对于成功的机器学习应用来说具有至关重要的作用。知识迁移只有在“适当”的情况下才有可能实现。在这个上下文下,对“适当”进行确切的定义并不是一件容易的事情,并且通常需要进行实验。你不应该相信一个开着玩具车孩子能够驾驭一辆法拉利。对迁移学习来说道理是一样的:虽然很难对其进行量化,但迁移学习是有上限的,它并不是一个适合于解决所有问题的“万金油”。
迁移学习的通用概念
迁移学习的要求
顾名思义,迁移学习需要具备将知识从一个领域迁移到另一个领域的能力。我们可以在一个较高层次上对迁移学习进行解释。一个例子就是,NLP中的体系结构可以在序列预测问题中得以重用,因为很多NLP问题本质上可以归结为序列预测问题。当然,迁移学习也可以在较低层次上进行解释,实际上,你可以在不同的模型中重用来自一个模型的参数(skip-gram、连续词袋(continuous bag-of-words)等)。迁移学习的要求一方面是特定的问题,另一方面是特定的模型。接下来的两节将分别讨论迁移学习所使用的高层次和低层次方法。尽管你会发现在不同的文献中这些概念的名称各有不同,但是迁移学习的总体概念是仍然存在的。
多任务学习
在多任务学习中,你可以同时在不同的任务上对一个模型进行训练。我们通常使用深度学习模型,因为它们可以灵活地进行调整。
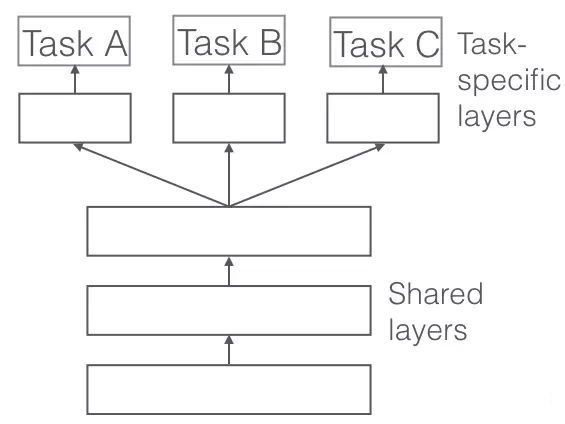
网络体系结构是以这样一种方式进行调整的,即在不同的任务使用第一层,随后对于不同的任务,使用特定于不同任务的层和输出。总的思路是,通过在不同任务上对网络进行训练,网络将会得到更好的泛化,因为模型应该能够在需要类似“知识”或“处理”的任务上表现良好。
自然语言处理中的示例是一个模型,其最终目标是执行实体识别。除了在实体识别任务中对模型进行纯粹的训练,你还可以用它进行语音分类,下一个单词预测……因此,模型将从这些任务和不同数据集的结构中获益。
Featuriser
深度学习模型的一大优点是特征提取是“自动化”的。基于标记数据和反向传播,网络能够确定用于任务的有用特征。例如,为了对图像进行分类,网络能够“计算出”输入的哪一部分是重要的。这意味着特征定义的手动工作被抽象出来了。深度学习网络可以在其他问题中得以重复使用,因为所提取的特征类型通常对于对其他问题来说也是有用的。本质上,在一个featuriser中,你可以使用网络的第一层来确定有用的特征,但是你不使用网络的输出,因为它是特定于任务的。
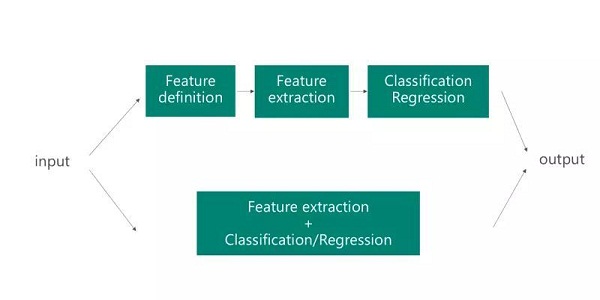
鉴于深度学习系统擅长特征提取,我们该如何重用现有网络以执行其他任务的特征提取呢?我们可以将数据样本馈送到网络中,并将网络中的一个中间层作为输出。这个中间层可以被阐述为一个固定的长度,原始数据的处理表示。典型地,featuriser的概念也往往用于计算机视觉任务中。然后将图像馈送到预训练网络中(例如,VGG或AlexNet),并且在新的数据表示上使用不同的机器学习方法。提取中间层作为图像的表示显著地减少了原始数据大小,使得它们更适合于传统的机器学习技术。例如,相较于具有一个类似128x128 = 16384维度的图像表征来说,具有一个较小的图像表征,如128维度的逻辑回归或支持向量机能够运行得更好。