Kafka源码系列,kafka 0.8.2.2为例给大家讲解。目标是大家读完kafka源码系列能彻底了解kafka,***能设计处自己的消息队列或者存储系统。
一,分布式系统的CAP理论
1,理论首先把分布式系统中的三个特性进行了如下归纳:
一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份***的数据副本)
可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
分区容错性(P):多副本进行容错。以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
2,CAP理论实践中的妥协
由于CAP理论在分布式存储系统中,做多只能实现上面两点。而现实环境是很复杂的,比如网络抖动及故障,硬件故障等问题,分区容错是我们必须要实现的。所以我们只能在一致性和可用性之间权衡。
A),CP系统-一致性优先原则
要实现强一致性的原则有很多方式,最简单的方式就是一个master节点和任意数目的包含冗余备份的附属节点。数据永远从master写入和读取。但是这个是存在单点故障的,由于master的故障会导致系统不可用,就此而言是放弃了可用性。但是一般情况下我们都有容错机制,让从属节点变为master,错误处理完成系统即可用了。
B),AP系统可用性优先原则
选择支持可用性和分区容错性,并牺牲一致性的系统被称为具有”最终一致性”。特点是,我们可以从任意的一个节点写入,该节点负责将数据同步到其它节点。读取的时候只需访问数据存在的一个节点就够了,但是可用会存在从某个节点读取的数据不是***的,也即系统不具备一致性。
C),灵活的一致性程度
三个特性之间权衡并不是非黑即白,其实可以平缓过度,达到***系统性能要求。
比如,在AP系统中,假如数据有三个冗余副本,我们可以通过调节请求数据的节点数目来达到高的一致性,比如我们同时向三个副本请求数据,那么我们就满足了强一致性,但是代价是丧失了容错性。通常,我们可以要求特定数目的节点或者大多数节点可用并且能返回一致性结果,是在一致性和容错性中进行权衡的一个不错的方法。
同样的在CP系统中,我们可以运行从附属节点中读取数据,牺牲一部分一致性来达到高的可用性。如果保持仍然只能想master写数据,那么我们还是高的一致性的写入操作,但是允许读取操作最终一致性。
我们可以根据具体的用例,调整CAP各种特性的强度,使之最适合用例的需要。甚至可以对同一个应用程序、同一个数据库中的不同类型的数据混合使用这些策略。
二,设计自己的分布式存储系统
设计一个分布式存储系统,并不难,难在如何保证系统的健壮性或者叫鲁棒性。至于原因,在这里浪尖只想说一句话那就是网络是不可靠的。
目前典型的分布式存储系统的结构为:
元数据服务器,数据存储节点,客户端。
数据的存取过程:
客户端会先获取元数据信息,然后根据元数据信息去特定的节点读写数据。元数据维护了数据在所有节点的存储情况,副本情况等等。数据存储节点会完成副本数据同步的过程。
与此同时,我们会要求分布式数据存储系统包含以下三个特性:
1,数据备份机制,顺利的处理某个节点无法访问的情况。
2,提供备份一致性的机制-----当用户请求数据的时候能获得最近更新的数据(一致性)。
3,线性扩展机制-----20个节点的吞吐量是10个节点的两倍。
三,剖析kafka存储系统
不要抬杠说kafka是消息队列不是存储系统。
1,Kafka的系统整个体系的角色:
1),zookeeper
记录的有kafka的Broker,kafka 的Broker controller选举,topic发布,配置更新,分区新增等都是客户端通过zookeeper发布到Crontroller的。
2),producer
负责发送数据到kafka
3),consumer
负责从kafka取数据
4),broker
负责数据接收、存储、管理等
5),topic 和 partition
Topic是代表一个种类的数据。Partition是对topic进行细分,保证吞吐量和处理并发度的关键,并且是集群数据备份的单元。
2,从常见的分布式存储系统的角色来看:
客户端:producer,consumer,zookeeper(topic,partition,Broker等相关的变更都是通过zookeeper通知到集群的controller的,要是觉得牵强可以将其归属到元数据集群)。
存储系统:Broker集群
元数据集群:zookeeper集群。其实每个Broker都会存储一份元数据(client-->zookeeper-->
Controller-->普通Broker)。
3,kafka的分布式存储特性
1),数据备份,故障恢复
分两个部分:
A),Broker故障恢复.Broker注册到zookeeper,临时zknode,/brokers/ids/[0...N],临时节点保存的是advertisedHost:advertisedPort,并会初始化SessionExpireListener该listener会监听Broker自己的临时节点(会话超时重新注册)。Crontroller就可以监听这个目录下的临时节点,会得知Brokers是否已经宕机,或者是否有新的Broker加入到节点.
Brokers集群通过向zookeeper注册临时节点/controller,来选举Crontroller,并且每个Broker都会监听该临时节点,通过临时节点的变动来决定是否进行Crontroller的选举。Crontroller宕机,触发其它Broker进行Crontroller重新选举。来进行容错。
B),topic表示一类消息,topic划分为若干partition,对每个partition进行数据的读写操作。Partition会有若干副本,副本会选举一个leader,然后数据的写入和读取都是通过leader来实现,这就实现了强一致性CP。与此同时引入了一个单点故障的问题,故障恢复机制是从isr列表里重新选举出leader。假如数据在flower从leader同步数据存在滞后的话,会导致数据丢失,那么此时,我们可以通过下面的配置,我们可以保证故障转移之后会不会有数据丢失。
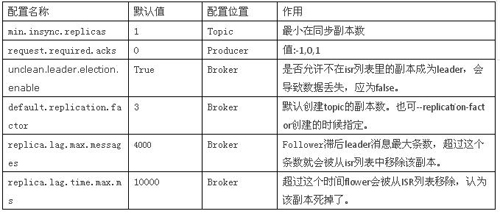
属性的详细介绍:
Request.required.acks:有三个取值分别的含义是:
0-不等待Broker应答,立即返回。
1-等待leader数据提交成功的应答。
-1-等待min.insync.replicas数目个副本都接收到数据才会视为写入成功。
该参数要结合min.insync.replicas来使用,当request.required.acks设置为-1时,isr列表里min.insync.replicas数目个副本数据写入完毕,才算消息生产成功。
min.insync.replicas数值不能超过副本数总数,假如相等的话,有一个副本不可用即会导致集群瘫痪。一般是replication.factor = min.insync.replicas +1即可。
2),数据备份一致性的机制
副本会选举出leader,其余follower。数据的写入和读取都是经过leader,以此来实现数据备份的一致性。所以,数据备份的一致性是CP,强一致性。Leader存在故障恢复机制:leader宕机,从isr列表里选举出新的leader。
3),线性扩展机制
该机制对于kafka来说也是分两个部分:
A),Broker的线性扩展
新的Broker加入集群,Crontroller会感知到变化。但是已有的分区或者数据不会重新分布到新的Broker上去,假如没有新增topic或者不进行人工迁移等操作的话新的Broker不会有数据。增加集群假如是非异构机器的话集群性能应该是线性增加的。
B),给某个topic扩大分区数,也会增加topic的并发度,前提是磁盘数目要合适。该增加也是会增加topic吞吐量。
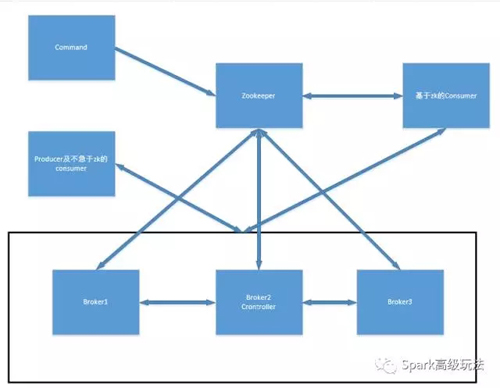
4,client与kafka集群之间通讯的机制
这篇文章之后讲大致过程,后面会陆续出文章讲细节部分。
A),Command---->zookeeper---->broker Controller---->Brokers
这个相当于基于zookeeper做了一个订阅发布系统。Topic创建配置更新等都是通过这种方式传达给所有Brokers Controller,然后由Broker Crontroller传递给所有的Brokers。
B),producer/SampleConsumer---->Brokers partitions leader----->follower
这个在<Kafka源码系列之通过源码分析Producer性能瓶颈>那讲已经说过,请求分两步:
1),***步随机选一个Broker,然后获取topic相关的元数据,如leader的位置等。
2),构建链接到所有leader所在Broker的连接池,进行数据的读写。
假如是生产消息的话follower会主动从leader上获取滞后的消息。
C),high consumer--->zookeeper---->brokers leader----->brokers follower
这个获取数据的方式比上个步骤多了个环节,就是从zookeeper上获取Broker的ip和port,而上个方式是直接在配置里写明了Broker的ip和port。
在上个基础上又基于zookeeper做了一些优化,增加了三个重要的zookeeper的listener:
1),ZKRebalancerListener
该listener监听的是/consumers/group/ids目录,当该目录下的有子节点增删的时候会触发,rebalance。假如尝试4次数后不能成功就会抛出一下异常
- throw new ConsumerRebalanceFailedException(consumerIdString + " can't rebalance after " + config.rebalanceMaxRetries +" retries")
2),ZKSessionExpireListener
监听的是每个consumer自己临时节点(/consumers/group/ids/consumerID)的删除与注册(无动作),临时节点删除时handleNewSession在处理函数里需要重新想zookeeper注册该节点。也会触发rebalance。
3),ZKTopicPartitionChangeListener
该listener,监控的是/brokers/topics/topicName节点的数据变动,也即是分区的变动,假如有新的分区增加也会触发rebalance。
四,总结
本文主要是想帮助大家理解设计一套分布式存储系统,首先介绍了CAP理论,接着讲了分布式存储系统的几个要素,***以kafka为例,讲解了kafka这个分布式消息队列或者分布式存储系统的结构。希望能帮助到大家。***,提笔做个埋点,关于zookeeper的理论及使用我们后面会跟大家娓娓道来。