在未来的三年内,深度学习将改变前端开发现状——它会提高原型设计的速度,并将降低软件开发的门槛。
继去年Tony Beltramelli和Airbnb推出了pix2code和ketch2code的论文之后,这个领域就开始腾飞。现在自动化前端开发的最大瓶颈是计算能力,但是通过深度学习算法以及综合的训练数据集,我们已然可以开始探索人工前端自动化。
本文我们将通过训练一个神经网络,使它可以直接将网页的设计原型图转换成基本的HTML和CSS网页。
以下是这个训练过程的简要概述:
1)将网页设计图导入到训练后的神经网络中
2)HTML标记
3)展示结果
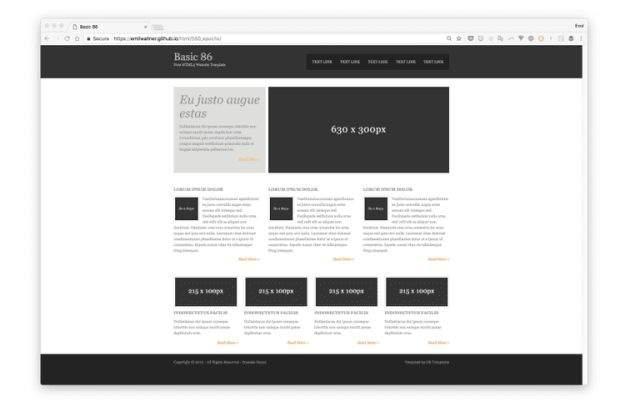
“我们将构建三个版本的神经网络”
在第一个版本,我们将实现一个最低限度版本,了解动态这部分的窍门。
HTML版本着重于全过程自动化,并且会解释各个神经网络层。最后Bootstrap版中,我们会创建基于LSTM的模型。
这篇文章里的模型都是以Beltramelli的pix2code论文和Brownlee的图像标注教程。这篇文章的代码用Python和Keras(基于TensorFlow)完成的。
如果你还是个深度学习领域的新手,那我建议你先了解一下Python,反向传播算法和卷积神经网络。我之前的三篇文章可以帮助你开始了解。
核心逻辑
让我们重新回顾一下我们的目标:我们想要构建一个能够将网页截图转换成相应HTML/CSS代码的神经网络。
我们提供给神经网络网页截图和相对应的HTML代码来训练它。.它逐个预测匹配的HTML标签来学习。当它要预测下一个标签时,会收到网页截图及对应的完整标签,直到下一个标签开始。谷歌表格提供了一个简单的训练数据的例子创建一个逐词预测模型是当今最常见的方法。当然还有其他的方法(https://machinelearningmastery.com/deep-learning-caption-generation-models/),但在整个教程中我们还是会使用的逐词预测的模型。
请注意,由于对它的每个预测我们都使用同样的网页截图,所以如果我们需要它预测20个词,那么就需要给它看20遍这个设计原型(即网页截图)。现在不要在意神经网络是如何工作的,我们的重点应该放在神经网络的输入输出参数上。
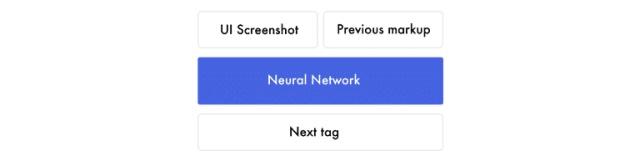
让我们把重点放在前面的标签。假设我们训练神经网络来预测“I can code"这句话。当它收到"I"时,它会预测到”can" 。接着它会收到"I can“并预测到”code"。它接收之前所有的单词然后只需要预测下一个单词。
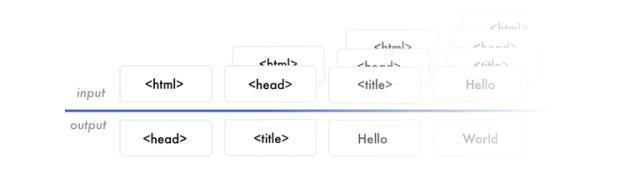
数据让神经网络可以创建特征。特征让输入数据和输出数据有了联系。神经网络需要将学习的网页截图、HTML语法构建出来,用来预测下一个HTML标签。
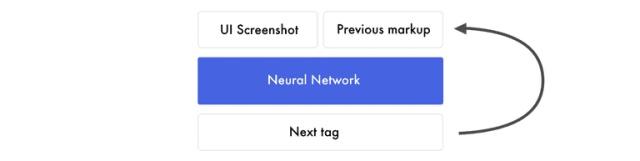
无论什么用途,训练模型的方式总是相似的。在每一次迭代中使用相同的图片生成一段段代码。我们并不会输入正确的HTML标签给神经网络,它使用自已生成的标签来预测下段标签。预测在“开始标签”时初始化,当它预测到“结束标签”或达到上限时结束。Google Sheet上有另一个示例。
“Hello World!"版本
让我们来构建”Hello World"版本。我们提供给神经网络一张显示"Hello World"的网页截图并教它如何生成对应的标签。
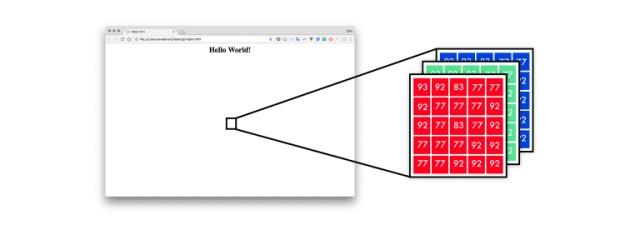
首先,神经网络将设计模型映射成像素值列表。像素值为0-255,其三个通道为红、黄、蓝。
为了使神经网络能够理解标签,我使用独热编码,所以”I can code"会被映射成下图这个样子:
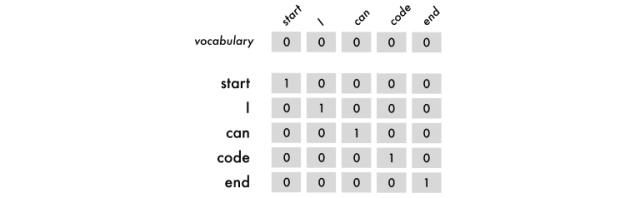
如上图所示,我们引入了开始标签和结束标签,它们能够帮助神经网络预测从哪里开始到哪里结束。我们使用顺序词组做为输入,它是从第一个词开始,顺序连接后面的词。输出总是一个词。
顺序词组的逻辑和词是一样的,不过它们需要相同的词组长度。
它们不受词汇表的限制,但受到最长词组长度的限制。如果它比最长词组长度短,你需要用空词去补全它,空词是内容全为0的词。

如你所见,空词是填充在左侧的。这样每次训练都会改变词的位置,使得模型能够学会这句话而不是记住每个单词的位置。下图每一行均表示一次预测,共有四次预测。逗号左边是用RGB表示的图片,逗号右边是前面词,括号外从上到下分别是每个预测的结果,其中结束标签用红色方块表示。

#Length of longest sentence max_caption_len = 3 #Size of vocabularyvocab_size = 3 # Load one screenshot for each word and turn them into digits images = for i in range(2): images.append(img_to_array(load_img('screenshot.jpg', target_size=(224,224)))) images = np.array(images, dtype=float) # Preprocess input for the VGG16 model images = preprocess_input(images) #Turn start tokens into one-hot encoding html_input = np.array( [[[0., 0., 0.], #start [0., 0., 0.], [1., 0., 0.]], [[0., 0., 0.], #start Hello World! [1., 0.,0.0., 1., 0.]]]) #Turn next word into one-hot encoding next_words = np.array( [[0., 1., 0.], # Hello World! [0., 0., 1.]]) # end# Load the VGG16 model trained on imagenet and output the classification feature VGG = VGG16(weights='imagenet', include_top=True) # Extract thefeatures from the image features = VGG.predict(images) #Load the feature to the network, apply a dense layer, and repeat the vector vgg_feature = Input(shape=(1000,)) vgg_feature_dense = Dense(5)(vgg_feature) vgg_feature_repeat = RepeatVector(max_caption_len)(vgg_feature_dense) # Extract information from the input seqence language_input = Input(shape=(vocab_size, vocab_size)) language_model = LSTM(5, return_sequences=True)(language_input) # Concatenate the information from the image and the input decoder = concatenate([vgg_feature_repeat, language_model]) # Extract information from the concatenated output decoder = LSTM(5, return_sequences=False)(decoder) # Predict which word comes nextdecoder_output = Dense(vocab_size, activation='softmax')(decoder) # Compile and run the neural network model = Model(inputs=[vgg_feature, language_input], outputs=decoder_output) model.compile(loss='categorical_crossentropy', optimizer='rmsprop') # Train the neural network model.fit([features, html_input], next_words, batch_size=2, shuffle=False, epochs=1000)- 1.
在“Hello World"版本中,我们使用三个词条:"start"、"Hello World!"和"end"。
用字符、单词或者句子作为词条都是可以的。使用字符作为词条需要小量的词汇表,但是会压垮神经网络。三者中用单词作为词条最佳。
让我们开始预测吧:
# Create an empty sentence and insert the start token sentence = np.zeros((1, 3, 3)) # [[0,0,0], [0,0,0], [0,0,0]] start_token = [1., 0., 0.] # start sentence[0][2] = start_token # place start in empty sentence # Making the first prediction with the start token second_word = model.predict([np.array([features[1]]), sentence]) # Put the second word in the sentence and make the final prediction sentence[0][1] = start_token sentence[0][2] = np.round(second_word) third_word = model.predict([np.array([features[1]]), sentence]) # Place the start token and our two predictions in the sentence sentence[0][0] = start_token sentence[0][1] = np.round(second_word) sentence[0][2] = np.round(third_word) # Transform our one-hot predictions into the final tokens vocabulary = ["start", "
Hello World!
", "end"] for i in sentence[0]: print(vocabulary[np.argmax(i)], end=' ')
- 1.
- 2.
- 3.
- 4.
- 5.
输出:
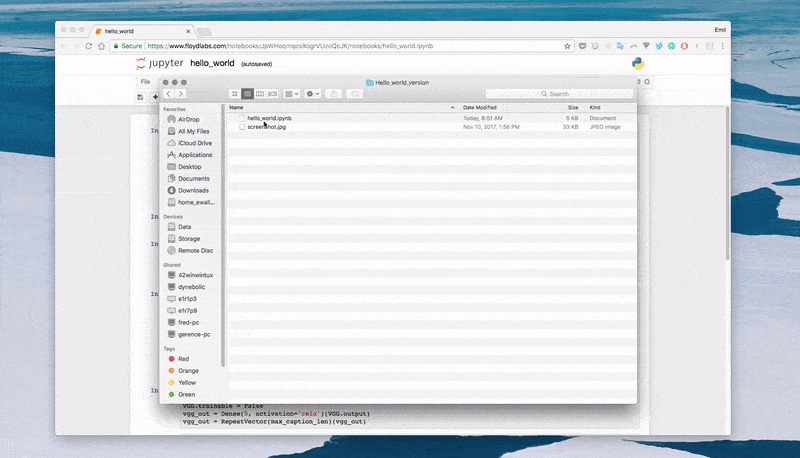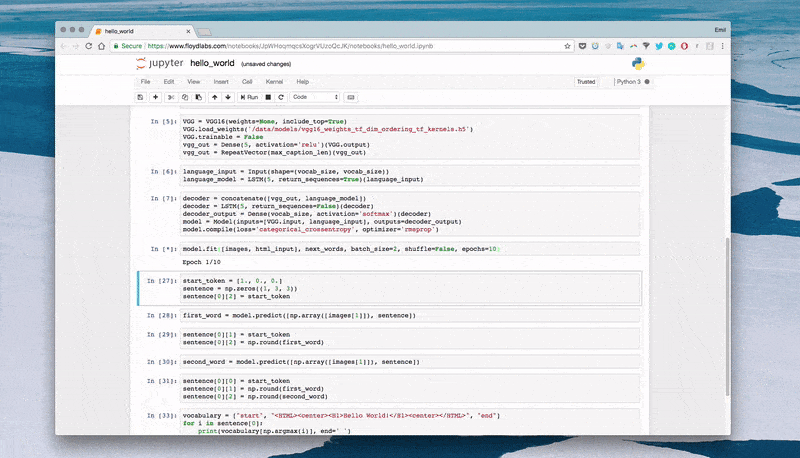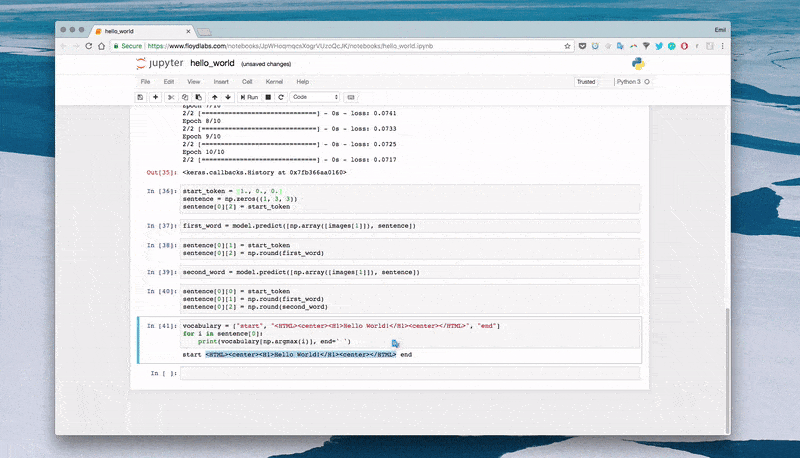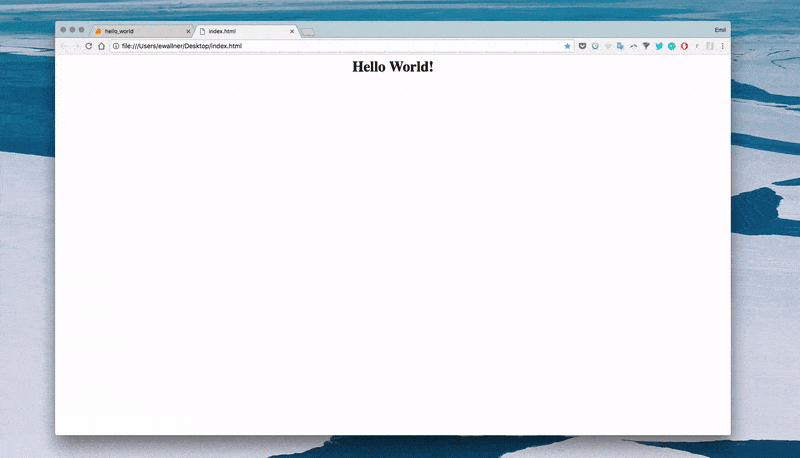
10 epochs: start start start
100 epochs: start <HTML><center><H1>Hello World!</H1></center></HTML> <HTML><center><H1>Hello World!</H1></center></HTML>
300 epochs: start <HTML><center><H1>Hello World!</H1></center></HTML> end
- 1.
- 2.
- 3.
- 4.
- 5.
走过的弯路:
-
在收集数据之前构建第一个运行的版本。在这个项目的早期,我设法得到Geocities托管网站的一个旧版本。它有3800万个网站。我只顾着这个数据的巨大的可能性,忽视了减少100K大小词汇所需的巨大工作量。
-
处理一个TB级的数据需要很好的硬件或者很强的耐心。在我的Mac遇到几个问题后,我最终使用了一个功能强大的远程服务器。要想获得顺畅的工作流程,估计你得租一个8核CPU的设备,再加上1GPS的网速
-
直到我理解了输入和输出数据之后,一切才变得有意义起来。输入数据X是网页截图和之前的标签。输出数据Y是下一个标签。当我明白了这个时,理解它们之间的一切变得更容易了。尝试不同的体系结构也变得更加容易。
-
别钻牛角尖。因为这个项目在深度学习中与很多领域相交叉,所以我一路钻了很多牛角尖。我花了一个星期从头开始编写RNN,也对嵌入向量空间感到非常着迷,并且被它独特的实现方法诱惑了。
-
图片到编码的网络是伪装了的图像描述模型。即使当我了解到这一点,我仍然忽视了许多图像描述的论文,只是因为它们不太酷。但是一旦我了解一些这方面的观点,我就加快了对问题空间的了解。
在FloygdHub上运行代码
FloydHub是一个深度学习的培训平台。我在刚开始学习深度学习的时候发现了这个平台,而且用它来训练和管理我的深度学习实验。你可以安装FloydHub,在10分钟内你就可以运行你的第一个模型了。这是云端GPU运行模型的最佳选择。
如果你是FloydHub的新手,那么做2分钟的安装(https://www.floydhub.com/)或5分钟的演练(https://www.youtube.com/watch?v=byLQ9kgjTdQ&t=21s)。
克隆存储库
git clone https://github.com/emilwallner/Screenshot-to-code-in-Keras.git
登录并启动FloydHub命令行工具
cd Screenshot-to-code-in-Keras
floyd login
floyd init s2c:
- 1.
- 2.
- 3.
- 4.
- 5.
在FloydHub云GPU机器上运行一个Jupyter Notebook:
floyd run --gpu --env tensorflow-1.4 --data emilwallner/datasets/imagetocode/2:data --mode jupyter- 1.
所有笔记本都在floydhub目录中。本地东西在本地。运行之后,你可以在这个地址找到第一个笔记本:
floydhub / Hello world / hello world.ipynb。- 1.
如果你想要更详细的说明和标志的解释,请关注我以前的帖子(https://blog.floydhub.com/colorizing-b&w-photos-with-neural-networks/)。
HTML版本
在这个版本中,我们将自动执行Hello World模型的多个步骤。本部分将着重于创建一个可扩展的实现和神经网络中的活动部分。
这个版本达不到随便给一个网站就能推演HTML代码,但它仍然为我们探索动态问题提供了一个不错的思路。
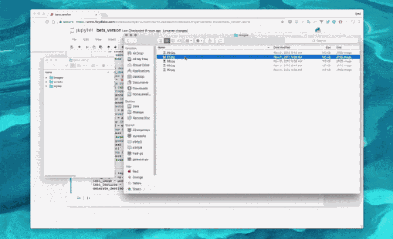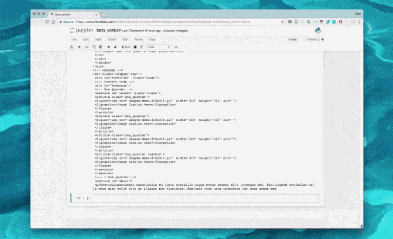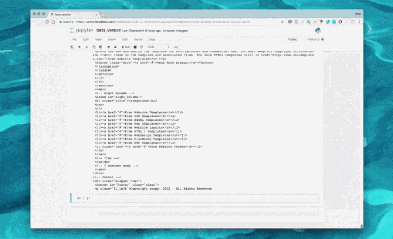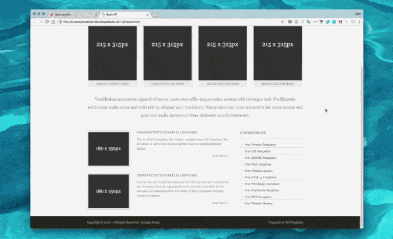
概览
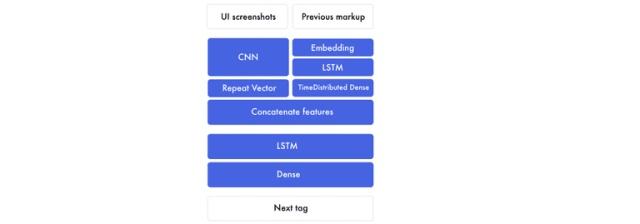
如果我们展开先前图形的组件,看起来就会像这样。
这个版本主要由两部分组成:
1.首先用于创建图像特征和之前标签特征的编码器。特征是神经网络创建的用来连接设计原型和标签的构建块。在编码器的结束部分,我们将图像特征和对应的标签串起来。
2.然后解码器将用合并后的设计原型特征和标签特征来创建下一个标签特征。这个特征运行在一个全连接神经网络上。
设计原型特征
由于每一个词前我们都需要插入一张网页截图,它成了训练神经网络的瓶颈 (example)(https://docs.google.com/spreadsheets/d/1xXwarcQZAHluorveZsACtXRdmNFbwGtN3WMNhcTdEyQ/edit#gid=0)。所以我们不使用图像,我们仅提取我们需要的信息来生成标签。
这是通过一个已经预先在Imagenet上训练好的卷积神经网络(CNN)来完成的。在最后的分类前我们需要从神经网络层中提取特征。
最终的特征是1536个8*8像素的图片集。虽然我们很难理解这些内容,但是神经网络可以从这里面提取物体的位置和元素。
HTML标签特征
在“Hello World”版本中,我们使用独热编码来表示标签。在这个版本中,我们使用词嵌入作为输入,输出数据仍保持独热编码格式。
句子的数据结构是一样的,不过映射词条的方式是不一样的。独热编码将每个词都当作独立部分。相反,我们将输入的词转化成数字列表来表示标签之间的关系。

词嵌入是8维的,根据词汇量的大小,变化通常在50-500之间。代表词的8个数字代表权重就像原始神经网络(vanilla neural network)一样。它们会不断地调整以表示词与词之间的关系。
这就是我们开始开发标签特征的方法。在神经网络中特征被开发出来用来表示输入数据和输出数据之间的关系。先不用担心它们是什么,我们在后面会深入讲解。
编码器
我们会将词嵌入传入到LTSM中,它会返回连续的标签特征。它们通过时序全连接层(time dense layer)运行 -把它想成有多个输入输出的全连接层。

同时图像特征也被提取出来。无论图像以哪种数据结构表示,它们都会被展开成一个很长的向量,再传送到全连接层,提取出高级特征。然后将这些特征与标签特征级联起来。
这个过程比较复杂 -让我们一步步来
标签特征
这里我们把词嵌入传输到LSTM层。如下图所示,所有的句子都被填充成长度为3的词符。

为了混合信号及发现高级模式,我们引入一个TimeDistributed全连接层到标签特征中。TimeDistributed全连接层和通常的全连接层相似,只不过有很多的输入和输出。
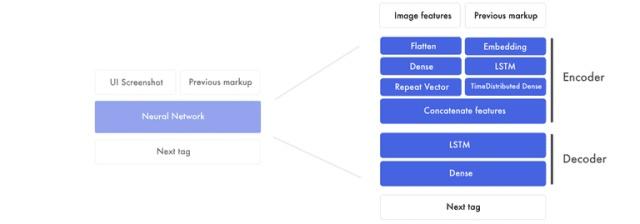
图像特征
同时我们会准备好图片。我们将这些图片特征转换成一个长列表。这些信息并没有发生变化,只是结构不同罢了。
同样的,为了混合信号并且提取高级概念我们再引入全连接层。由于我们只需要处理一个输入值,所以一个普通的全连接层就行了。为了连接图像特征和标签特征,我们复制图像特征。
级联图像特征和标签特征
所有的句子都被填充以创建3个标签特征。由于我们已经准备好了图像特征,现在我们可以为每个标签特征添加图像特征。
在为每个标签特征添加图像特征后,我们得到3个图像-标签特征。我们会把它们传输到解码器中。
解码器
这里我们使用刚才得到的图像-标记结合特征来预测下一个标签。

在下面的例子里,我们用这三个图像-标记特征对来输出下一个标签特征。请注意LSTM层将序列设置为“否”,也就是说它仅会预测出一个合并特性,而不是返回同输入序列同样长度的特性描述序列。在我们的实际案例中,这就是下一个标签的特性。它包含了最终预测结果所需要的信息。

最终预测
全连接层所起的作用就相当于一个传统的前馈型神经网络。
它将下个标签特性所包含的512个数位与4个最终预测值联系起来。假设词汇表中有四个单词:start,hello,world以及end。
对于词汇表中词汇的预测值可能是[0.1, 0.1, 0.1, 0.7],在全连接层启用softmax函数,将概率在0-1的区间内进行离散,同时所有预测值和为1。在本例中,预测第四个单词即为下一个标签。之后使用解码器,将独热编码的结果[0,0,0,1]译为映射值当中的“end”。
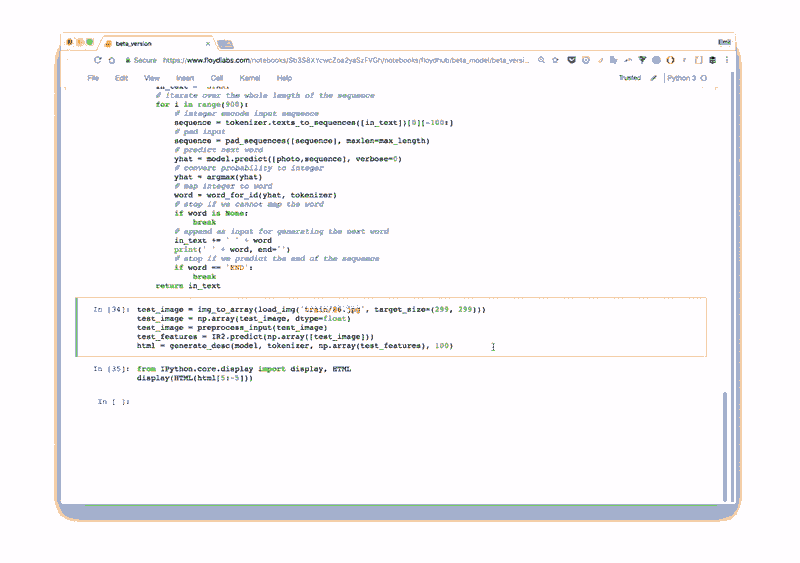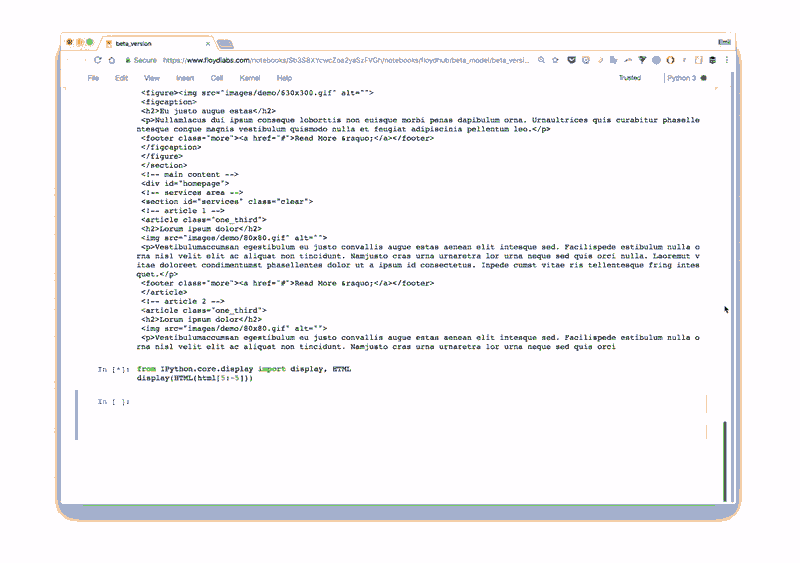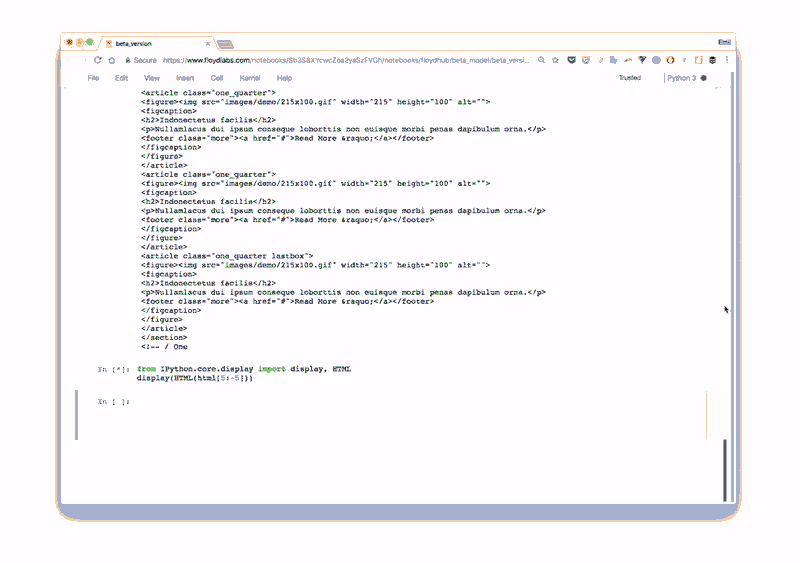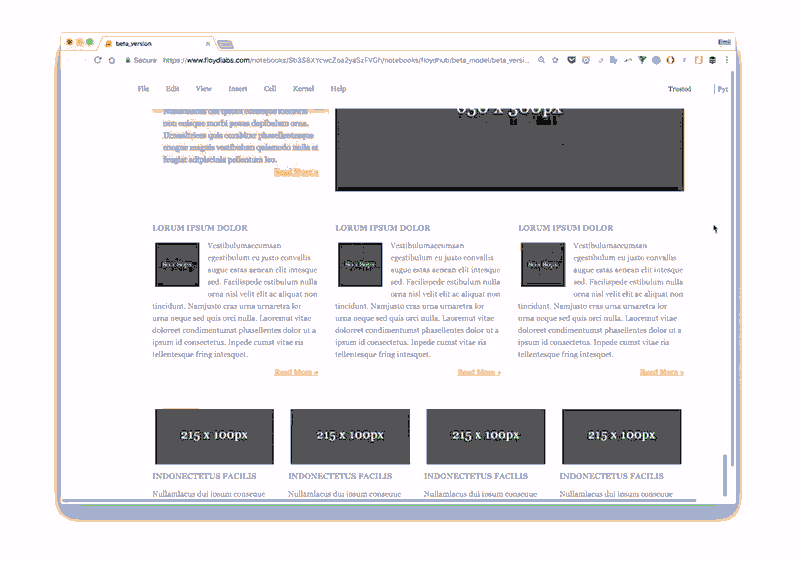
# Load the images and preprocess them for inception-resnet images = all_filenames = listdir('images/') all_filenames.sort for filename inall_filenames: images.append(img_to_array(load_img('images/'+filename, target_size=(299, 299)))) images = np.array(images, dtype=float) images = preprocess_input(images) # Run the images through inception-resnet and extract the features without the classification layer IR2 = InceptionResNetV2(weights='imagenet', include_top=False) features = IR2.predict(images) # We will cap each input sequence to 100 tokensmax_caption_len = 100 # Initialize the function that will create our vocabulary tokenizer = Tokenizer(filters='', split=" ", lower=False) # Read a document and return a string defload_doc(filename): file = open(filename, 'r') text = file.read file.close return text # Load all the HTML files X = all_filenames = listdir('html/'for filename inall_filenames: X.append(load_doc('html/'+filename)) # Create the vocabulary from the html files tokenizer.fit_on_texts(X) # Add +1 to leave space for empty words vocab_size = len(tokenizer.word_index) + 1 # Translate each word in text file to the matching vocabulary indexsequences = tokenizer.texts_to_sequences(X) # The longest HTML filemax_length = max(len(s) for s in sequences) # Intialize our final input to the model X, y, image_data = list, list, list for img_no, seq inenumerate(sequences): for i in range(1, len(seq)): # Add the entire sequence to the input and only keep the next word for the output in_seq, out_seq = seq[:i], seq[i] # If the sentence is shorter than max_length, fill it up with empty words in_seq = pad_sequences([in_seq], maxlen=max_length)[0] # Map the output to one-hot encoding out_seq = to_categorical([out_seq], num_classes=vocab_size)[0] # Add and image corresponding to the HTML file image_data.append(features[img_no]) # Cut the input sentence to 100 tokens, and add it to the input dataX.append(in_seq[-100:]) y.append(out_seq) X, y, image_data = np.array(X), np.array(y), np.array(image_data) # Create the encoder image_features = Input(shape=(8, 8, 1536,)) image_flat = Flatten(image_features) image_flat = Dense(128, activation='relu')(image_flat) ir2_out = RepeatVector(max_caption_len)(image_flat) language_input = Input(shape=(max_caption_len,)) language_model = Embedding(vocab_size, 200, input_length=max_caption_len)(language_input) language_model = LSTM(256, return_sequences=True)(language_model) language_model = LSTM(256, return_sequences=True)(language_model) language_model = TimeDistributed(Dense(128, activation='relu'))(language_model) # Create the decoder decoder = concatenate([ir2_out, language_model]) decoder = LSTM(512, return_sequences=False)(decoder) decoder_output = Dense(vocab_size, activation='softmax')(decoder) # Compile the model model = Model(inputs=[image_features, language_input], outputs=decoder_output) model.compile(loss='categorical_crossentropy', optimizer='rmsprop') # Train the neural network model.fit([image_data, X], y, batch_size=64, shuffle=False, epochs=2) # map an integer to a worddefword_for_id(integer, tokenizer): for word, index intokenizer.word_index.items: if index == integer: return word returnNone # generate a description for an image defgenerate_desc(model, tokenizer, photo, max_length): # seed the generation process in_text = 'START' # iterate over the whole length of the sequence for i in range(900): # integer encode input sequence sequence = tokenizer.texts_to_sequences([in_text])[0][-100:] # pad input sequence = pad_sequences([sequence], maxlen=max_length) # predict next word yhat = model.predict([photo,sequence], verbose=0) # convert probability to integer yhat = np.argmax(yhat) # map integer to word word = word_for_id(yhat, tokenizer) # stop if we cannot map the word if wordisNone: break # append as input for generating the next word in_text += ' ' + word # Print the prediction print(' ' + word, end='') # stop if we predict the end of the sequence if word == 'END': break return # Load and image, preprocess it for IR2, extract features and generate the HTMLtest_image = img_to_array(load_img('images/87.jpg', target_size=(299,299))) test_image = np.array(test_image, dtype=float) test_image = preprocess_input(test_image) test_features = IR2.predict(np.array([test_image])) generate_desc(model, tokenizer, np.array(test_features), 100)- 1.
输出
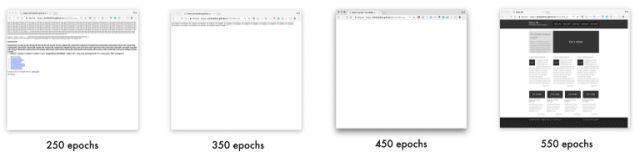
生成的网站链接:
-
250 epochs(https://emilwallner.github.io/html/250_epochs/)
-
350 epochs(https://emilwallner.github.io/html/350_epochs/)
-
450 epochs(https://emilwallner.github.io/html/450_epochs/)
-
550 epochs(https://emilwallner.github.io/html/550_epochs/)
如果点击链接无法显示任何结果,你可以右击选择“查看网页源代码”。以下是案例中用于识别分析的原网站。
如果上面的链接打开后没有内容显示,你可以右键选择"查看网页源代码“。这里是这些网页的本来的源代码。
走过的弯路:
-
(对我来说)LSTM网络的学习困难程度远高于卷积神经网络。在我全面认识理解LSTM网络之后,这一结构对我来说变得容易了一些。Fast.ai的循环神经网络视频有极大的帮助。同时在你试图理解这个网络结构如何运行的前,也要仔细观察那些输入和输出的特征。
-
从头构建一个词库比起压缩一个巨大的词库要容易太多,因为后者涉及到字体、DIV大小、十六进制颜色编码、变量名称和网页内容。
-
通常文本文件内容是用空格分开的,但是在代码文件中,你需要自定义解析方法。
-
你可以提取用Imagenet上已经训练好的模型来提取特征。Imagenet几乎没有什么网页图片,这可能有违直觉。但是同pix2code的模型比起来,它的损失要高30%。当然我也对基于网页截图来预训练的inception-resnet模型很有兴趣。
Bootstrap版本
在我们的最终版本中,我们会使用pix2code论文中搭建的bootstrap网站的一个数据集。通过使用Twitter的bootstrap,可以将HML和CSS相结合,并且压缩词库的大小。
我们将让它为一副之前没有见过的网页截图生成标签,同时也会深入探讨它是如何建立关于截图与标记的认知。
我们将会使用17个经过简化的词条将这些记号转换为HTML和CSS,而不是利用bootstrap标签进行训练。这一套数据集包括1500个测试截图以及250幅验证图像。平均每个截图都有65个词条,结果总计产生96925个训练样本。
通过对pix2code论文中提及模型的微调,我们的模型对于网页组件预测的准确度可以高达97%(基于BLEU饱和搜索测评,详解见后)。
端到端方法
利用预训练过的模型提取特征对于图像标注模型效果的确很好。但经过几次试验之后,我发现pix2code的端到端方法对于这类问题效果更佳。预训练模型并不是通过网页数据训练,而是通过定制的分类器训练。
在这一模型中,我们用一个轻量的卷积神经网络替换了预训练得到的图像特征。我们通过增加步长来增加信息密度,而不是最大池化函数。这样能最大程度保留前端各元素的位置和颜色信息。
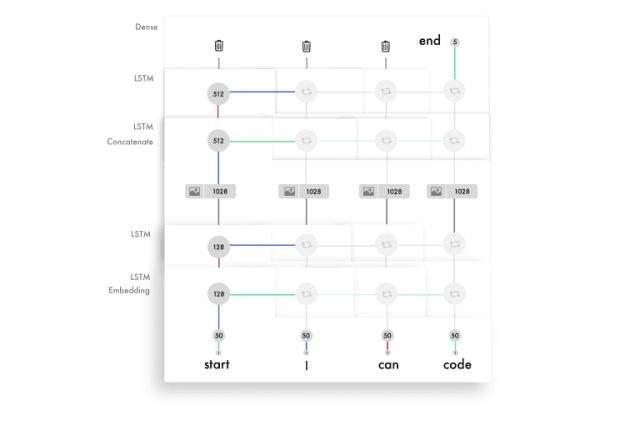
有两个核心模型可以做到这一点,卷积神经网络(CNN)和循环神经网络(RNN)。最常用的循环神经网络是长短期记忆网络(LSTM),接下来我将会用到。在我之前的文章中,也总结过许多非常棒的CNN教程,在本案例中,我们重点使用LSTM。
理解LSTM的时间步
掌握LSTM的难点在于时间步。一个原始神经网络(vanilla neural network)可以看做有两个时间步。如果你输入“Hello”,它将预测“World”。但是它尝试去预测更多的时间步。
在以下的示例中,输入包含了四个时间步,每一个都对应一个词。
LSTM适用于含有时间步的输入,适用于有序信息的神经网络。如果你对于模型进行解析,它的工作原理看起来类似这样:每一次向下递推都保持相同的权重。你可以对于之前的输出设置一套权重,然后对于新的输入再设置另一套权重。
被赋予权重的输入和输出将通过激活被联结并且组合,也就形成了那一时间步的输出。因为我们会反复使用这些权重,也就会从若干次的输入中得出信息,并形成对于结果的认知。加权后的输入和输出级联后传输给一个激活函数,作为相应的时间步的输出。这些被复用的权重集描述了输入的信息,并构建序列的知识。
以下是LSTM模型中每一个时间步的简化版本。
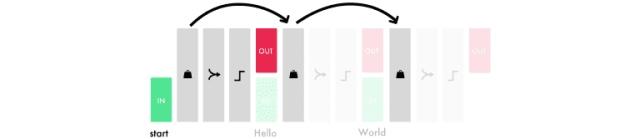
建议大家参考Andrew Trask的神教程(https://iamtrask.github.io/2015/11/15/anyone-can-code-lstm/),从无到有搭建一个RNN网络来理解背后的逻辑
理解LSTM层的单元
每一层LSTM的单元数量决定了它的记忆力,也同样决定了输出特征的大小。需要再次指出,我们这里的特征是层与层之间传递信息的一长串数字。
LSTM层中的每个单元都保留对于语法不同方面的记录。下面展示了如何实现一个单元对于div行信息进行保留。这也是我们用于训练bootstrap模型的一种简化标记。
每一个LSTM单元都存储了一个细胞状态。把细胞状态看作记忆,权重和激活函数使用不同的方式改变这个状态。使得LSTM层对于每一次的输入,可以很好的调整那些信息,决定哪些需要保留,而哪些需要丢弃。
除了传递每一次输入的输出特征外,层单元也会传递细胞状态,每一个LSTM细胞都对应一个不同的值。如果想了解LSTM层中的要素之间都是如何相互作用的,我强烈推荐Colah的教程,Jayasiri的Numpy实现,Karphay的讲座以及评论。
dir_name = 'resources/eval_light/' # Read a file and return a stringdefload_doc(filename): file = open(filename, 'r') text = file.read file.close return text defload_data(data_dir): text = images = # Load all the files and order them all_filenames = listdir(data_dir) all_filenames.sort for filename in (all_filenames): if filename[-3:] =="npz": # Load the images already prepared in arrays image = np.load(data_dir+filename) images.append(image['features']) else: # Load the boostrap tokens and rap them in a start and end tag syntax = ' ' + load_doc(data_dir+filename) + ' ' # Seperate all the words with a single space' '.join(syntax.split) # Add a space after each comma syntax = syntax.replace(',', ' ,') text.append(syntax) images = np.array(images, dtype=float) return images, text train_features, texts = load_data(dir_name) # Initialize the function to create the vocabularytokenizer = Tokenizer(filters='', split=" ", lower=False) # Create the vocabulary tokenizer.fit_on_texts([load_doc('bootstrap.vocab')]) # Add one spot for the empty word in the vocabulary vocab_size = len(tokenizer.word_index) + 1 # Map the input sentences into the vocabulary indexes train_sequences = tokenizer.texts_to_sequences(texts) # The longest set of boostrap tokens max_sequence = max(len(s) for s intrain_sequences) # Specify how many tokens to have in each input sentencemax_length = 48 defpreprocess_data(sequences, features): X, y, image_data = list, list, list for img_no, seq in enumerate(sequences): for i inrange(1, len(seq)): # Add the sentence until the current count(i) and add the current count to the output in_seq, out_seq = seq[:i], seq[i] # Pad all the input token sentences to max_sequence in_seq = pad_sequences([in_seq], maxlen=max_sequence)[0] # Turn the output into one-hot encoding out_seq = to_categorical([out_seq], num_classes=vocab_size)[0] # Add the corresponding image to the boostrap token file image_data.append(features[img_no]) # Cap the input sentence to 48 tokens and add it X.append(in_seq[-48:]) y.append(out_seq) returnnp.array(X), np.array(y), np.array(image_data) X, y, image_data = preprocess_data(train_sequences, train_features) #Create the encoderimage_model = Sequential image_model.add(Conv2D(16, (3, 3), padding='valid', activation='relu', input_shape=(256, 256, 3,))) image_model.add(Conv2D(16, (33), activation='relu', padding='same', strides=2)) image_model.add(Conv2D(32, (33), activation='relu', padding='same'32, (33), activation='relu', padding='same', strides=264, (33), activation='relu', padding='same'64, (33), activation='relu', padding='same', strides=2128, (33), activation='relu', padding='same')) image_model.add(Flatten) image_model.add(Dense(1024, activation='relu')) image_model.add(Dropout(0.3)) image_model.add(Dense(1024, activation='relu'0.3)) image_model.add(RepeatVector(max_length)) visual_input = Input(shape=(256, 256, 3,)) encoded_image = image_model(visual_input) language_input = Input(shape=(max_length,)) language_model = Embedding(vocab_size, 50, input_length=max_length, mask_zero=True)(language_input) language_model = LSTM(128, return_sequences=True)(language_model) language_model = LSTM(128, return_sequences=True)(language_model) #Create the decoder decoder = concatenate([encoded_image, language_model]) decoder = LSTM(512, return_sequences=True)(decoder) decoder = LSTM(512, return_sequences=False)(decoder) decoder = Dense(vocab_size, activation='softmax')(decoder) # Compile the model model = Model(inputs=[visual_input, language_input], outputs=decoder) optimizer = RMSprop(lr=0.0001, clipvalue=1.0) model.compile(loss='categorical_crossentropy', optimizer=optimizer) #Save the model for every 2nd epoch filepath="org-weights-epoch-{epoch:04d}--val_loss-{val_loss:.4f}--loss-{loss:.4f}.hdf5" checkpoint = ModelCheckpoint(filepath, monitor='val_loss', verbose=1, save_weights_only=True, period=2) callbacks_list = [checkpoint] # Train the model model.fit([image_data, X], y, batch_size=64, shuffle=False, validation_split=0.1, callbacks=callbacks_list, verbose=1, epochs=50) - 1.
准确率测试
用一种公平合理的方式测试正确率是比较困难的。假设逐词对照,如果在同步时有一个词错位,也许只能收获0%的正确率。而如果你删掉一个符合同步预测的词,准确率也可能高达99%。
我使用了BLEU测评,这一测评在机器翻译和图像标注模型上有很好表现。测评将句子打散为四个n-gram,也就是1-4个词组成的字符串。在以下的预测中,应该是“code”而不是‘cat’。
最终评分需要将每次打散的成绩乘以25%:
(4/5) * 0.25 + (2/4) * 0.25 + (1/3) * 0.25 + (0/2) * 0.25 = 0.2 + 0.125 + 0.083 + 0 = 0.408
求和结果再乘以句子长度做取值补偿。因为我们以上的例子中长度取值正确,所以这就是我们最终测评分数。
你可以通过增加n-gram的组数来增加测评难度,分为4组n-gram的模型是最符合人类的直觉。建议大家利用以下的代码运行一些案例,然后读一读维基百科对于BLEU测评的描述。
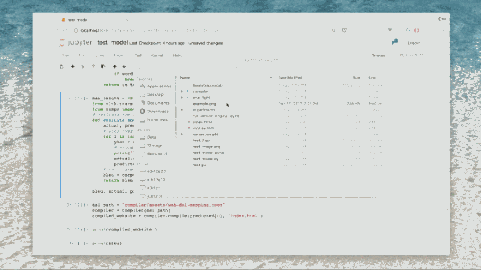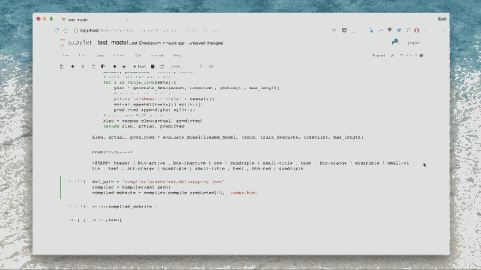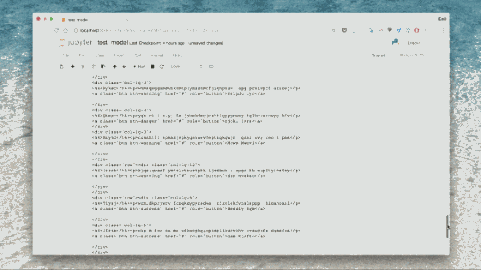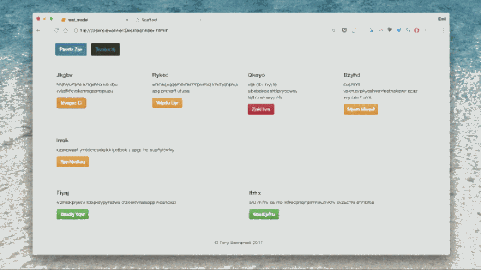
#Create a function to read a file and return its contentdefload_doc(filename): file = open(filename, 'r') text = file.read file.close return text defload_data(data_dir): text = images = files_in_folder = os.listdir(data_dir) files_in_folder.sort for filenamein tqdm(files_in_folder): #Add an image if filename[-3:] == "npz": image = np.load(data_dir+filename) images.append(image['features']) else: # Add text and wrap it in a start and end tag syntax = ' ' + load_doc(data_dir+filename) + ' ' #Seperate each word with a space' '.join(syntax.split) #Add a space between each comma syntax = syntax.replace(',', ' ,') text.append(syntax) images = np.array(images, dtype=float) return images, text #Intialize the function to create the vocabulary tokenizer = Tokenizer(filters='', split=" ", lower=False)#Create the vocabulary in a specific ordertokenizer.fit_on_texts([load_doc('bootstrap.vocab')]) dir_name ='../../../../eval/' train_features, texts = load_data(dir_name) #load model and weights json_file = open('../../../../model.json', 'r') loaded_model_json = json_file.read json_file.close loaded_model = model_from_json(loaded_model_json) # load weights into new modelloaded_model.load_weights("../../../../weights.hdf5") print("Loaded model from disk") # map an integer to a word defword_for_id(integer, tokenizer):for word, index in tokenizer.word_index.items: if index == integer: returnword returnNone print(word_for_id(17, tokenizer)) # generate a description for an image defgenerate_desc(model, tokenizer, photo, max_length): photo = np.array([photo]) # seed the generation process in_text = ' ' # iterate over the whole length of the sequence print(' Prediction----> ', end='') for i in range(150): # integer encode input sequence sequence = tokenizer.texts_to_sequences([in_text])[0] # pad inputsequence = pad_sequences([sequence], maxlen=max_length) # predict next word yhat = loaded_model.predict([photo, sequence], verbose=0) # convert probability to integer yhat = argmax(yhat) # map integer to word word = word_for_id(yhat, tokenizer) # stop if we cannot map the word if wordisNone: break # append as input for generating the next word in_text += word + ' ' # stop if we predict the end of the sequence print(word + ' ', end='') if word == '': break return in_text max_length = 48 # evaluate the skill of the model defevaluate_model(model, descriptions, photos, tokenizer, max_length): actual, predicted = list, list # step over the whole set for i in range(len(texts)): yhat = generate_desc(model, tokenizer, photos[i], max_length) # store actual and predictedprint(' Real----> ' + texts[i]) actual.append([texts[i].split]) predicted.append(yhat.split) # calculate BLEU score bleu = corpus_bleu(actual, predicted) return bleu, actual, predicted bleu, actual, predicted = evaluate_model(loaded_model, texts, train_features, tokenizer, max_length) #Compile the tokens into HTML and css dsl_path ="compiler/assets/web-dsl-mapping.json" compiler = Compiler(dsl_path) compiled_website = compiler.compile(predicted[0], 'index.html') print(compiled_website ) print(bleu) - 1.
输出
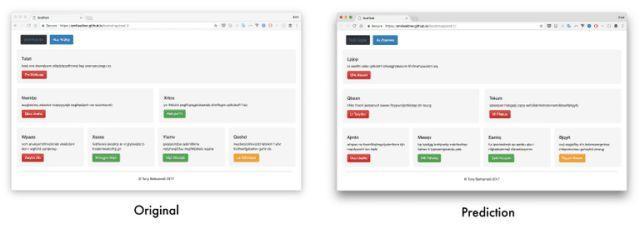
输出样本链接:
-
Generated website 1 - Original 1
(https://emilwallner.github.io/bootstrap/pred_1/) (https://emilwallner.github.io/bootstrap/real_1/)
-
Generated website 2 - Original 2
() ()
-
Generated website 3 - Original 3
() ()
-
Generated website 4 - Original 4
() ()
-
Generated website 5 - Original 5
() ()
走过的弯路:
-
理解每个模型的不足,而不是随机选择模型测试。一开始我采用的方法比较随机,比如批量归一化,双向网络,甚至尝试实现注意力。看到测试数据后,我才明白这些方法并不能准确的预测颜色和位置,这是我意识到卷积神经网络当中存在一些不足。这导致我使用增加步长的办法去代替最大池化方法。损失从0.12降到了0.02,同时BLEU评分从85%升到97%。
-
如果具有相关性的话,仅考虑使用经过预训练的模型。对于小型的数据集,我认为一个经过训练的图像模型可以改善表现。以我个人的经验看来,一个端到端的模型训练费时,并且需要更多的内存,但是准确率会提高30%。
-
如果使用远程服务器运行模型,需要考虑到轻微的偏差。我的MAC以字母表顺序读取文件,但是在服务器上,文件是随机读取的。这会导致截图和代码之间的不匹配。虽然预测结果趋同,但是有效数据比起重新匹配前要糟糕50%。
-
掌握引用的库函数。包括词汇表中的空词条里的填充空格。如果不进行特别添加,识别中将不包括这一标记。我是通过几次观察到最终结果中无法预测出“单个”标记,才注意到这一点。快速检查一遍后,我意识到这并不包含在词库中。同时也需要注意,训练和检测时,需要使用同样顺序的词库。
-
实验时使用轻量的模型。利用GRU而不是LSTM可以让每光华迭代循环的时间减少30%,并且对于结果不会有太大影响。
接下会发生什么?
-
前端开发是应用深度学习理想的空间。生成数据容易,并且现在的深度学习算法可以实现绝大部分的逻辑。
-
其中很有意思的地方是“通过LSTM实现注意力”。它不仅可以用来提高准确率,而且让我们可以让CNN将它的注意力放在生成标签上。
-
注意力也是标签、样式、脚本甚至后端之间交流的关键。注意力层可以追踪变量,使神经网格可以在不同的编程语言中交流。
-
但是在不久的将来,最大的影响来自于建立生成数据的可扩展方法。那时你可以一步步地添加字体、颜色、内容和动画。
-
目前大部分的进步在是将草图转换成模板。在两年内,我们可以在纸上画上应用的模板,然后瞬间生成对应的前端代码。事实上Airbnb’s design team(https://airbnb.design/sketching-interfaces/) andUizard(https://www.uizard.io/)已经建立了基本可以使用的原型了。
进一步的实验
-
根据相应的语法创建一个稳定的随机应用/网站生成器。
-
生成从草图到应用的数据。自动转换应用/网页截图到草图并用GAN来构建多样性。
-
添加注意力层,可视化每一次预测的焦点,像这个模型一样。
-
为模块化方法创建一个框架。比如字体编码器、颜色编码器、结构编码器,然后用一个解码器将它们整合起来。从稳定的图像特征开始似乎不错。
-
让神经网络学习简单的HTML组件,然后将它生成CSS动画。注意力机制和可视化输入源真的很神奇。
关于作者: Emil Wallner
深度学习邻域的资深博客撰写者,投资人,曾就职于牛津大学商学院,现长期居住在法国,是非盈利组织42(écoles)项目组成员。我们已获得授权翻译