













自微信小程序出现游戏“跳一跳”后,众多微信用户纷纷和排行榜较上了劲,颇有一些不到***不罢休的架势。

而在离游戏“跳一跳”***上线过去了一个多月后,众多大神也开始显现。分数上千已不是难事。
“微信之父”张小龙也在 2018 微信公开课 PRO 上透露了自己玩微信小游戏“跳一跳”的分数,表示自己***分达到 6000+,他还称自己玩“跳一跳”时并不会紧张和心跳加快,而是觉得很平静,享受这个过程。
作为无(zhi)所(hui)不(ban)能(zhuan)的 AI 程序员,我们在想,能不能用人工智能(AI)和计算机视觉(CV)的方法来玩一玩这个游戏?
于是,我们开发了微信跳一跳 Auto-Jump 算法,重新定义了玩跳一跳的正确姿势。
我们的算法不仅远远超越了人类的水平,在速度和准确度上也远远超越了目前已知的所有算法,可以说是跳一跳界的 state-of-the-art,下面我们详细介绍我们的算法。
算法的***步是获取手机屏幕的截图并可以控制手机的触控操作,我们的 Github 仓库里详细介绍了针对 Android 和 iOS 手机的配置方法。
Github 地址:https://github.com/Prinsphield/Wechat_AutoJump
你只需要按照将手机连接电脑,按照教程执行就可以完成配置。在获取到屏幕截图之后,就是个简单的视觉问题。我们需要找的就是小人的位置和下一次需要跳的台面的中心。
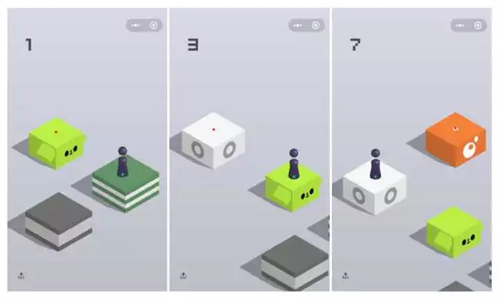
如图所示,绿色的点代表小人当前的位置,红点代表目标位置。

多尺度搜索(Multiscale Search)
这个问题可以有非常多的方法去解,为了糙快猛地刷上榜,我一开始用的方式是多尺度搜索。我随便找了一张图,把小人抠出来,就像下面这样。

另外,我注意到小人在屏幕的不同位置,大小略有不同,所以我设计了多尺度的搜索,用不同大小的进行匹配,***选取置信度(confidence score)***的。
多尺度搜索的代码长这样:
def multi_scale_search(pivot, screen, range=0.3, num=10):
H, W = screen.shape[:2]
h, w = pivot.shape[:2]
found = None
for scale in np.linspace(1-range, 1+range, num)[::-1]:
resized = cv2.resize(screen, (int(W * scale), int(H * scale)))
r = W / float(resized.shape[1])
if resized.shape[0] < h or resized.shape[1] < w:
break
res = cv2.matchTemplate(resized, pivot, cv2.TM_CCOEFF_NORMED)
loc = np.where(res >= res.max())
pos_h, pos_w = list(zip(*loc))[0]
if found is None or res.max() > found[-1]:
found = (pos_h, pos_w, r, res.max())
if found is None: return (0,0,0,0,0)
pos_h, pos_w, r, score = found
start_h, start_w = int(pos_h * r), int(pos_w * r)
end_h, end_w = int((pos_h + h) * r), int((pos_w + w) * r)
return [start_h, start_w, end_h, end_w, score]
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
我们来试一试,效果还不错,应该说是又快又好,我所有的实验中找小人从来没有失误。
不过这里的位置框的底部中心并不是小人的位置,真实的位置是在那之上一些。

同理,目标台面也可以用这种办法搜索,但是我们需要收集一些不同的台面,有圆形的,方形的,便利店,井盖,棱柱等等。由于数量一多,加上多尺度的原因,速度上会慢下来。
这时候,我们就需要想办法加速了。首先可以注意到目标位置始终在小人的位置的上面,所以可以操作的一点就是在找到小人位置之后把小人位置以下的部分都舍弃掉,这样可以减少搜索空间。
但是这还是不够,我们需要进一步去挖掘游戏里的故事。小人和目标台面基本上是关于屏幕中心对称的位置的。这提供了一个非常好的思路去缩小搜索空间。
假设屏幕分辨率是(1280,720)的,小人底部的位置是(h1, w1),那么关于中心对称点的位置就是(1280 - h1, 720 - w1),以这个点为中心的一个边长 300 的正方形内,我们再去多尺度搜索目标位置,就会又快又准了。
效果见下图,蓝色框是(300,300)的搜索区域,红色框是搜到的台面,矩形中心就是目标点的坐标了。
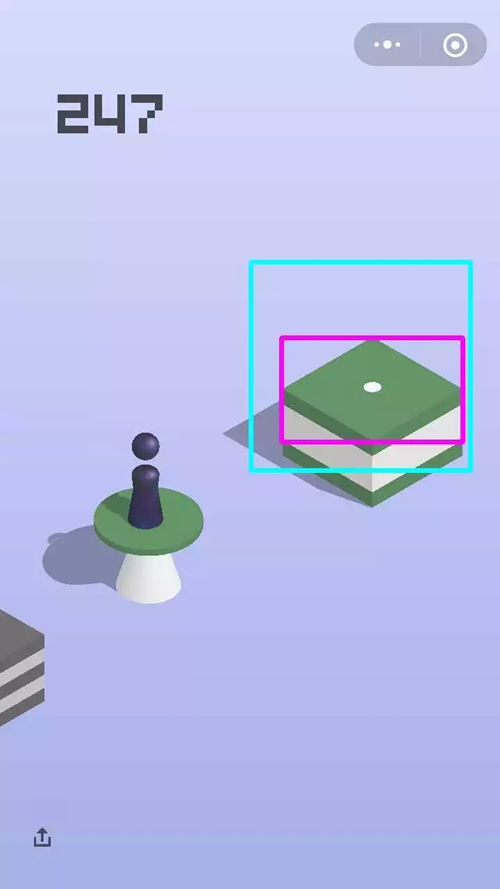
加速的奇技淫巧(Fast-Search)
玩游戏需要细心观察。我们可以发现,小人上一次如果跳到台面中心,那么下一次目标台面的中心会有一个白点,就像刚才所展示的图里的。
更加细心的人会发现,白点的 RGB 值是(245,245,245),这就让我找到了一个非常简单并且高效的方式,就是直接去搜索这个白点。
注意到白点是一个连通区域,像素值为(245,245,245)的像素个数稳定在 280-310 之间,所以我们可以利用这个去直接找到目标的位置。
这种方式只在前一次跳到中心的时候可以用,不过没有关系,我们每次都可以试一试这个不花时间的方法,不行再考虑多尺度搜索。
讲到这里,我们的方法已经可以运行的非常出色了,基本上是一个永动机。下面是用我的手机玩了一个半小时左右,跳了 859 次的状态。
我们的方法正确的计算出来了小人的位置和目标位置,不过我选择狗带了,因为手机卡的已经不行了。
以下是效果演示:
视频链接:https://v.vzuu.com/video/932359600779309056
到这里就结束了吗?那我们和业余玩家有什么区别?下面进入正经的学术时间,非战斗人员请迅速撤离。
CNN Coarse-to-Fine 模型
考虑到 iOS 设备由于屏幕抓取方案的限制(WebDriverAgent 获得的截图经过了压缩,图像像素受损,不再是原来的像素值,原因不详,欢迎了解详情的小伙伴提出改进意见)无法使用 fast-search。
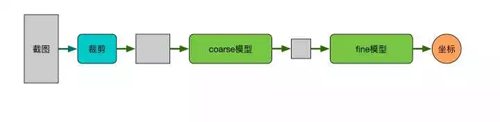
同时为了兼容多分辨率设备,我们使用卷积神经网络构建了一个更快更鲁棒的目标检测模型。
下面分数据采集与预处理,coarse 模型,fine 模型,Cascade 四部分介绍我们的算法。
数据采集与预处理
基于我们非常准确的 multiscale-search 和 fast-search 模型,我们采集了 7 次实验数据,共计大约 3000 张屏幕截图,每一张截图均带有目标位置标注。
对于每一张图,我们进行了两种不同的预处理方式,并分别用于训练 Coarse 模型和 Fine 模型,下面分别介绍两种不同的预处理方式。
Coarse 模型数据预处理
由于每一张图像中真正对于当前判断有意义的区域只在屏幕中央位置,即人和目标物体所在的位置,因此,每一张截图的上下两部分都是没有意义的。
于是,我们将采集到的大小为 1280*720 的图像沿 x 方向上下各截去 320*720 大小,只保留中心 640*720 的图像作为训练数据。
我们观察到,游戏中,每一次当小人落在目标物中心位置时,下一个目标物的中心会出现一个白色的圆点。

考虑到训练数据中 fast-search 会产生大量有白点的数据,为了杜绝白色圆点对网络训练的干扰,我们对每一张图进行了去白点操作,具体做法是,用白点周围的纯色像素填充白点区域。
Fine 模型数据预处理
为了进一步提升模型的精度,我们为 Fine 模型建立了数据集,对训练集中的每一张图,在目标点附近截取 320*320 大小的一块作为训练数据。
为了防止网络学到 trivial 的结果,我们对每一张图增加了 50 像素的随机偏移。Fine 模型数据同样进行了去白点操作。
Coarse 模型
我们把这一问题看成了回归问题,Coarse 模型使用一个卷积神经网络回归目标的位置。
def forward(self, img, is_training, keep_prob, name='coarse'):
with tf.name_scope(name):
with tf.variable_scope(name):
out = self.conv2d('conv1', img, [3, 3, self.input_channle, 16], 2)
# out = tf.layers.batch_normalization(out, name='bn1', training=is_training)
out = tf.nn.relu(out, name='relu1')
out = self.make_conv_bn_relu('conv2', out, [3, 3, 16, 32], 1, is_training)
out = tf.nn.max_pool(out, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
out = self.make_conv_bn_relu('conv3', out, [5, 5, 32, 64], 1, is_training)
out = tf.nn.max_pool(out, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
out = self.make_conv_bn_relu('conv4', out, [7, 7, 64, 128], 1, is_training)
out = tf.nn.max_pool(out, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
out = self.make_conv_bn_relu('conv5', out, [9, 9, 128, 256], 1, is_training)
out = tf.nn.max_pool(out, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
out = tf.reshape(out, [-1, 256 * 20 * 23])
out = self.make_fc('fc1', out, [256 * 20 * 23, 256], keep_prob)
out = self.make_fc('fc2', out, [256, 2], keep_prob)
return out
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
经过 10 个小时的训练,Coarse 模型在测试集上达到了 6 像素的精度,实际测试精度大约为 10 像素,在测试机器(MacBook Pro Retina, 15-inch, Mid 2015, 2.2 GHz Intel Core i7)上 inference 时间 0.4 秒。
这一模型可以很轻松的拿到超过 1k 的分数,这已经远远超过了人类水平和绝大多数自动算法的水平,日常娱乐完全够用,不过,你认为我们就此为止那就大错特错了。
Fine 模型
Fine 模型结构与 Coarse 模型类似,参数量稍大,Fine 模型作为对 Coarse 模型的 refine 操作。
def forward(self, img, is_training, keep_prob, name='fine'):
with tf.name_scope(name):
with tf.variable_scope(name):
out = self.conv2d('conv1', img, [3, 3, self.input_channle, 16], 2)
# out = tf.layers.batch_normalization(out, name='bn1', training=is_training)
out = tf.nn.relu(out, name='relu1')
out = self.make_conv_bn_relu('conv2', out, [3, 3, 16, 64], 1, is_training)
out = tf.nn.max_pool(out, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
out = self.make_conv_bn_relu('conv3', out, [5, 5, 64, 128], 1, is_training)
out = tf.nn.max_pool(out, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
out = self.make_conv_bn_relu('conv4', out, [7, 7, 128, 256], 1, is_training)
out = tf.nn.max_pool(out, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
out = self.make_conv_bn_relu('conv5', out, [9, 9, 256, 512], 1, is_training)
out = tf.nn.max_pool(out, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
out = tf.reshape(out, [-1, 512 * 10 * 10])
out = self.make_fc('fc1', out, [512 * 10 * 10, 512], keep_prob)
out = self.make_fc('fc2', out, [512, 2], keep_prob)
return out
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
经过 10 个小时训练,Fine 模型测试集精度达到了 0.5 像素,实际测试精度大约为 1 像素,在测试机器上的 inference 时间 0.2 秒。
Cascade
总体精度 1 像素左右,时间 0.6 秒。
总结
针对这一问题,我们利用 AI 和 CV 技术,提出了合适适用于 iOS 和 Android 设备的完整解决方案,稍有技术背景的用户都可以实现成功配置、运行。
我们提出了 Multiscale-Search,Fast-Search 和 CNN Coarse-to-Fine 三种解决这一问题的算法,三种算法相互配合,可以实现快速准确的搜索、跳跃,用户针对自己的设备稍加调整,跳跃参数即可接近实现“永动机”。
讲到这里,似乎可以宣布,我们的工作 terminate 了这个问题,微信小游戏跳一跳 Game Over!
友情提示:适度游戏益脑,沉迷游戏伤身,技术手段的乐趣在于技术本身而不在游戏排名,希望大家理性对待游戏排名和本文提出的技术,用游戏娱乐自己的生活。
声明:本文提出的算法及开源代码符合 MIT 开源协议,以商业目的使用该算法造成的一切后果须由使用者本人承担。
Git 仓库地址:
- https://github.com/Prinsphield/Wechat_AutoJump
- https://github.com/Richard-An/Wechat_AutoJump



















