MySQL有一个很有意思的索引类型,叫做前缀索引,它可以给某个文本字段的前面部分单独做索引,从而降低索引的大小。
其实,Oracle也有类似的实现,对于文本,它可以通过substr的函数索引,实现同样甚至更多的功能。另外,经过探索,我们发现,原来数字和时间字段,在Oracle也可以实现类似的功能。
MySQL的前缀索引
MySQL的前缀索引指的是对指定的栏位的前面几位建立的索引。
- Altertable Table_Name add key(column_name(prefix_len));
或者
- Createindex index_name on Table_Name(column_name(prefix_len));
建立前缀索引后,可以直接当做普通索引进行过滤。
- Select ..from table_name where column_name=’…’;
前缀索引的***的好处是降低索引的大小。另外,由于InnoDB单列索引长度不能超过767bytes,如果是text或者blob字段,直接建立索引可能会报错,而前缀索引可以绕过这一限制。
做个测试看一下。
- delimiter;;
- dropFUNCTION if exists random_str;;
- CREATEFUNCTION random_str(n int) RETURNS varchar(30000)
- begin
- declarereturn_str varchar(30000) default "";
- declare iint default 0;
- whilelength(return_str) < n do
- setreturn_str=concat(return_str,md5(rand()));
- endwhile;
- returnsubstring(return_str,1,n);
- end;;
首先,创建一个生成超过1000长度的随机字符串的函数。
创建测试表
- CREATETABLE TEST_PREFIX_IND (
- ID INT(10) PRIMARY KEY AUTO_INCREMENT,
- NORMAL_STR VARCHAR(20) ,
- LONG_STR VARCHAR(1000),
- TEXT_STR TEXT,
- BLOB_STR BLOB
- );
插入10000行记录:
- drop procedure if exists init_test_prefix_ind;;
- createprocedure init_test_prefix_ind(n int)
- begin
- declare iint default 0;
- while i< n do
- insertinto test_prefix_ind(NORMAL_STR,long_str, TEXT_STR,BLOB_STR)
- values(random_str(20),random_str(rand()*1000+1),random_str(rand()*1000+1),random_str(rand()*300+1));
- seti=i+1;
- endwhile;
- end;;
- callinit_test_prefix_ind(10000);;
尝试在类型为varchar(1000)的LONG_STR创建索引
- altertable test_prefix_ind add key(LONG_STR);;
成功了,但是Sub_part显示为767,表示系统自动创建了前缀长度为767的前缀索引;

看看大小: 8992k

尝试在TEXT和BLOB的栏位上直接创建索引
- mysql> alter table test_prefix_ind add key(text_str);
- ERROR 1170 (42000): BLOB/TEXT column 'text_str' used in key specification without a key length
- mysql> alter table test_prefix_ind add key(blob_str);;
- ERROR 1170 (42000): BLOB/TEXT column 'blob_str' used in key specification without a key length
在TEXT和BLOB栏位上建立索引,必须指定前缀长度。
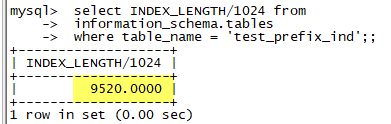
- alter table test_prefix_ind add key(text_str(30));;
看看大小,528k(9520-8992), 远远小于LONG_STR的8992k.
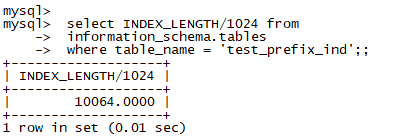
- alter table test_prefix_ind add key(blob_str(30));;
看看大小,544k(10064-9520)。
看看几个表的前缀长度和大小。前缀长度显著降低了索引的大小。

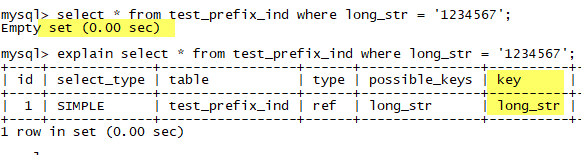
看看查询是否能正常进行:

可以使用上索引。
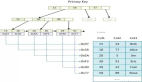
前缀索引长度的选择
对于一个可能挺长的栏位,怎么判断合适的前缀索引呢?
简单做法:
- Select count(distinct substr(long_str,1,5))/count(*) from test_prefix_ind;
炫一点的写法,通过一些小技巧,可以在同一个SQL里遍历多个值,同时查看多个值的选择度。
- select R,count(distinct substr(long_str,1,R))/count(*)
- from
- (SELECT @rownum:=ceil(@rownum*1.4) AS R
- FROM (SELECT @rownum:=1) r,test_prefix_ind limit 1,10
- ) R,test_prefix_ind T
- group by R;;
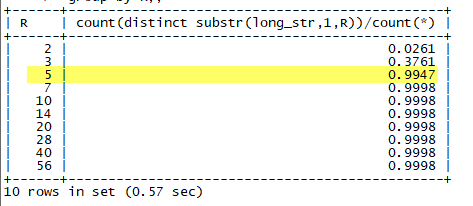
对于这个表,由于数据是随机的,所以,前5位已经足够好。
我们创建一个前缀长度为5的前缀索引。
- alter table test_prefix_ind add key(long_str(5));
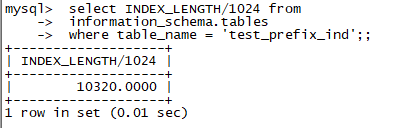
看看大小,仅仅258k(10320-10064),远低于最早创建的8992k。
测试一下性能,有前缀索引时:
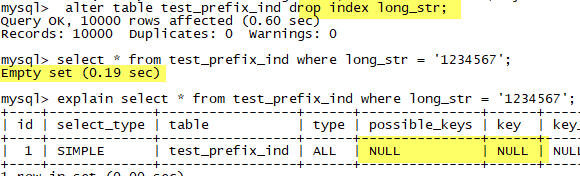
删除索引后,性能差距很明显:
Oracle的类似实现
从前面的做法中,我们可以发现,前缀索引本质上就是把栏位的前N位作为索引,这个看起来,很像Oracle的函数索引。类似于:
- Create index index_name on table_name(substr(column_name,1,<length>) );
对于Oracle的函数索引,我们一个比较深的印象就是,where条件必须和函数索引里的表达式一致,才能利用上函数索引。但既然MySQL可以用前缀索引,作为老前辈的Oracle, 似乎应该也能实现才对。
我们来看看,在Oracle里面,是否能够实现同样的功能。
创建表格:
- Create table test_substr as
- select object_id,object_name||dbms_random.string('x',dbms_random.value(1,1000) as object_name,created from all_objects ,
- (select * from dual connect by level < 100)
- where rownum < 10000;
创建substr的函数索引:
- Create index test_substr_inx on test_substr(substr(object_name,1,5));
看看执行计划:
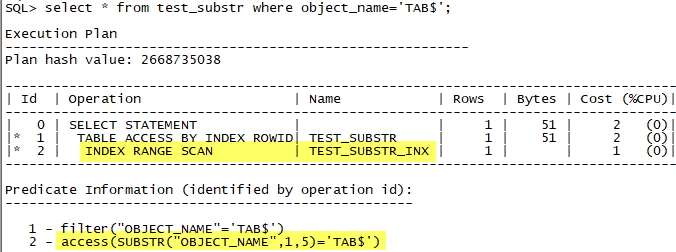
神奇的事情发生了,的确走了索引,Oracle也支持前缀索引~~
我们可以看到,找谓词中,增加了一个原来语句中没有的东西:

换成绑定变量看看:
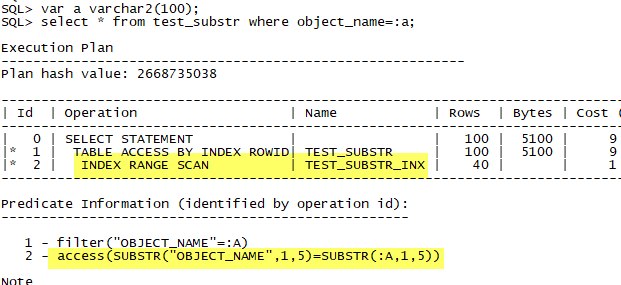
可以看到,谓词中变成了:

为什么多了这个东西?因为,从逻辑上来说:
- select * from test_substr where object_name=:a;
和
- select * from test_substr where object_name=:a and substr(object_name,1,5)=substr(:a,1,5);
是***等价的。Oracle相当于自动做了语义上的优化。
有兴趣的,可以做个10053。Oracle内部实际进行执行计划解析的,就是这样一个SQL。
- SELECT * FROM TEST_SUBSTR WHERE OBJECT_NAME=:A AND SUBSTR(OBJECT_NAME,1,5)=SUBSTR(:A,1,5);
看看如果创建普通索引,空间占用是多少。
- Create index test_substr_inx2 on test_substr(object_name);
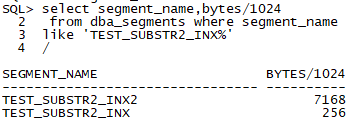
大小分别是7M和256K.
但Oracle仅止于此吗?我们在来试试看另一个SQL, 这次,我们在条件上也使用substr,但是长度不为5。
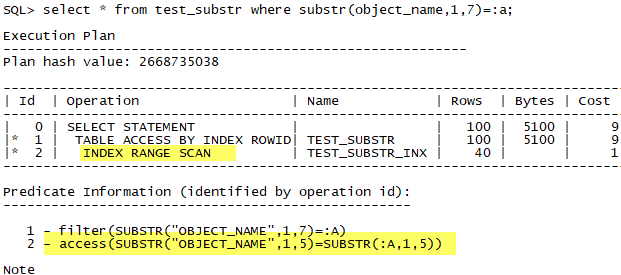
果然还是可以的。因为逻辑上来说
- select * from test_substr where substr(object_name,1,<N>)=:a;
在N>=5的时候,
- select * from test_substr where substr(object_name,1,<N>)=:a and substr(object_name,1,5)=substr(:a,1,5);
还是等价的。所以优化器还是可以继续加一个谓词。
当然,如果把WHERE条件中substr换成小于5的值,就不再能用得上索引。因为无法直接换为等价的、又带有substr(object_name,1,5)的语句。
Oracle时间、数字上的前缀索引
仅仅就这样吗?除了字符类型之外,数字类型和时间类型是否也支持?
我们再看看。
在刚才的表的基础上,创建时间类型上的trunc函数索引。
- select * from test_substr
- where substr(object_name,1,<N>)=:a and substr(object_name,1,5)=substr(:a,1,5);
看看执行计划:
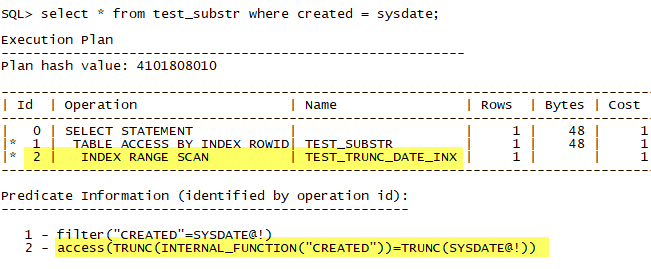
没问题,还是可以的。
创建数字类型上的trunc函数索引:
- create index test_trunc_number on TEST_SUBSTR(trunc(object_id));
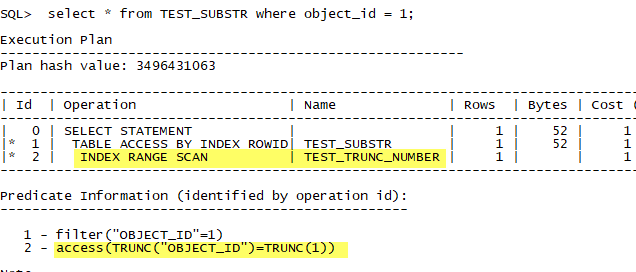
实际上,问题的关键在于等价与优化器的内部改写。
我们***再看另一个例子。
建另一个表,相当栏位长度最长为5。
- create table test_scale (object_name varchar2(5));
- insert into test_scale select substr(object_name,1,5) from all_objects;
- create index test_scale_str_inx in test_scale(object_name);
来看看这个语句的执行效果
- select * from test_scale where object_name = 'DBA_TABLES';
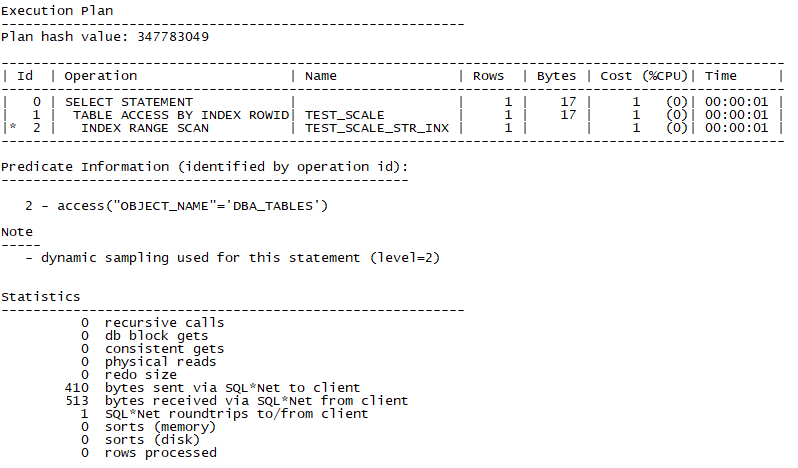
神奇的事情再次发生,autotrace中db block gets/consistent gets都为0,这代表数据库根本就没去访问表。
原因很简单,‘DBA_TABLES’这个值长度大于5, 超出了表定义中的varchar2(5)了。object_name = ‘DBA_TABLES’就等价于恒否的条件了。这个,在10053里也找不到,但的确存在。